
アイリスデータセットで極める機械学習完全制覇
 山崎講師
山崎講師第1章:アイリスデータセットで機械学習の第一歩!データの顔つきを理解する準備編
こんにちは。ゆうせいです。
これから皆さんと一緒に、機械学習というエキサイティングな世界を冒険していきたいと思います。人工知能やAIという言葉を聞かない日はありませんが、その正体はいったい何なのでしょうか。
実は、機械学習とは「データの中に隠れたルールを見つけ出す作業」のことなんです。
今回は、その第一歩として、世界で最も有名なデータセットの一つである「アイリス(アヤメの花)」を使って、データの正体を暴いていきましょう。まずはモデルを作る前に、材料となるデータをじっくり観察することから始めます。皆さんは、目の前にあるデータがどんな特徴を持っているか、想像したことはありますか?
機械学習の王道!アイリスデータセットとは?
アイリスデータセットは、3種類のアヤメ(セトサ、バージカラー、バージニカ)という花の特徴を記録したデータです。

具体的には、以下の4つの数値が記録されています。
- がく片の長さ(Sepal Length)
- がく片の幅(Sepal Width)
- 花弁の長さ(Petal Length)
- 花弁の幅(Petal Width)
この4つの数字を使って、その花がどの種類なのかを当てるのが機械学習のミッションです。でも、いきなり「予測しろ!」と言われても困りますよね。まずは、料理と同じで「材料の吟味」が必要です。
Pandasでデータの性格を数値化する
まずは、PythonのPandasというライブラリを使って、データの「基本統計量」を見てみましょう。基本統計量とは、データの平均値やバラつき具合を示す数値のことです。
import pandas as pd
from sklearn.datasets import load_iris
# データの読み込み
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['target'] = iris.target
# 基本統計量の表示
print(df.describe())このコードを実行すると、各項目の平均値(mean)や標準偏差(std)が表示されます。
ここで専門用語の解説です。
「標準偏差(Standard Deviation)」とは、データが平均からどれくらい散らばっているかを表す指標です。
例えば、クラス全員のテストの点数が 50 点だった場合、標準偏差は 
この数値を見ることで、データが「みんな似たり寄ったり」なのか「個性が爆発している」のかを判断できるのです。
可視化の魔法!Seabornで相関を確認する
数字だけを見ていても、データの全体像はつかみにくいですよね。そこで「可視化」の出番です。Seabornというライブラリの pairplot(ペアプロット)を使うと、全ての特徴量の組み合わせを一度にグラフ化できます。
import seaborn as sns
import matplotlib.pyplot as plt
# ターゲット名を日本語に変換(分かりやすくするため)
df['species'] = df['target'].map({0: 'setosa', 1: 'versicolor', 2: 'virginica'})
# ペアプロットの作成
sns.pairplot(df.drop('target', axis=1), hue='species')
plt.show()

このグラフを見ると、種類ごとに色が分かれて表示されます。特定の項目を組み合わせると、ある種類だけがポツンと離れて存在していることに気づきませんか?
線形分離可能か?という重要な視点
グラフを見て気づいたかもしれませんが、セトサ(setosa)という種類は、他の2種と比べて明らかに離れた場所にあります。このように、直線や平面でスパッと綺麗にグループを分けられる状態を「線形分離可能(Linearly Separable)」と呼びます。
機械学習において、この「線形分離可能かどうか」を判断することは極めて重要です!
メリット
直線で分けられるほど単純なデータであれば、計算が非常に簡単で、なぜその答えになったのかという理由(解釈性)も説明しやすくなります。
デメリット
現実の世界のデータは、もっと複雑に絡み合っていることが多いです。直線で分けられない「非線形」なデータに対して無理やり直線を引こうとすると、予測の精度がガクッと落ちてしまいます。
アイリスの場合、セトサは直線で分けられそうですが、残りの2種は少し境界線が重なっていますね。ここをどう見極めるかが、エンジニアの腕の見せ所です。
次のステップへの指針
今回は、データの顔つきを観察する「準備編」をお届けしました。
- データの平均やバラつき(基本統計量)を確認する
- グラフにして特徴同士のつながり(相関)を視覚的に理解する
- 直線で分けられるか(線形分離可能性)を考察する
この3つのステップは、どんなに高度なAIを作る時でも欠かせない儀式です。
さて、データの顔つきが分かったところで、次は実際に「予測」に挑戦してみたくありませんか?
次回は第2章「回帰編」です。花びらの長さから幅を予測するという、最もシンプルで奥が深い統計モデルの世界をご案内します。
楽しみにしていてくださいね!
今回の内容で、自分の手元にあるデータも可視化してみたいと思いましたか?まずは手始めに、データの平均値と最大値の差がどれくらいあるかチェックすることから始めてみてくださいね。
第2章:回帰編 - 特徴量同士の関係性を探る
前回の準備編では、アイリスデータの「顔つき」をじっくり観察しましたね。セトサ、バージカラー、バージニカという3つのグループが、それぞれどんな数字の特徴を持っているか、なんとなくイメージが湧いてきたでしょうか?
今回は、いよいよ「予測」の第一歩を踏み出します。でも、いきなり「花の種類」を当てるわけではありません。まずは、もっと根本的な「数字から数字を当てる」という 回帰(かいき) という手法に挑戦してみましょう。
皆さんは、身長が高い人は体重も重い傾向がある、といった「あちらが増えれば、こちらも増える」という関係性を目にしたことはありませんか?
単回帰分析:一本の直線で未来を予測する
機械学習の最もシンプルな形、それが 単回帰分析 です。
これは、1つのデータ(説明変数)を使って、もう1つのデータ(目的変数)を予測する方法です。
今回は、アイリスの「花弁の長さ」を見て「花弁の幅」を予測してみましょう。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.datasets import load_iris
from sklearn.metrics import mean_squared_error, mean_absolute_error
# データの準備
iris = load_iris()
X = iris.data[:, 2].reshape(-1, 1) # 花弁の長さ
y = iris.data[:, 3] # 花弁の幅
# モデルの作成と学習
model = LinearRegression()
model.fit(X, y)
# 予測
y_pred = model.predict(X)
# 可視化
plt.scatter(X, y) # 実データ
plt.plot(X, y_pred, color='red') # 回帰直線を赤に
plt.xlabel('Petal Length')
plt.ylabel('Petal Width')
plt.show()
# 評価指標
print("R^2:", model.score(X, y))
print("MSE:", mean_squared_error(y, y_pred))
print("RMSE:", np.sqrt(mean_squared_error(y, y_pred)))
print("MAE:", mean_absolute_error(y, y_pred))

グラフに赤い直線が引かれましたか?この直線こそが、AIが見つけ出した「ルール」です。
| R^2: 0.9271098389904927 MSE: 0.04206730919499318 RMSE: 0.20510316719883478 MAE: 0.15647051371014092 |
① R² = 0.927
①決定係数(説明力)
- 0〜1の範囲
- 1に近いほど良い
- 0.927 ≒ 92.7%を説明できている
花弁の長さだけで、花弁の幅の変動の約93%を説明できている
→ 非常に高い線形関係
② MSE = 0.042
平均二乗誤差
- 誤差を二乗して平均
- 単位は「幅²」
値が小さいほど良いですが、
単位が二乗なので直感的ではありません。
③ RMSE = 0.205
平方根平均二乗誤差
- MSEの平方根
- 元の単位(cm)に戻る
予測は平均して 約0.20 cm ずれる
かなり小さい誤差です。
④ MAE = 0.156
平均絶対誤差
予測は平均して 約0.16 cm ずれる
RMSEより小さい
→ 大きな外れ値はほとんどない
重回帰分析:複数のヒントで精度を上げる
単回帰では「花弁の長さ」だけをヒントにしましたが、実際には「がく片の幅」や「がく片の長さ」も関係しているかもしれません。このように、複数のヒントを使って1つの数字を予測することを 重回帰分析 と呼びます。
ヒントが増えるほど、AIはより多角的に判断できるようになります。皆さんも、天気予報を見る時に「気温」だけでなく「湿度」や「風速」もチェックしたほうが、傘を持つべきか正確に判断できますよね?それと同じ理屈です。
今回はアイリスデータセットを使った例として:
目的変数:花弁の幅(petal width)
説明変数:その他3変数
で実装します。
重回帰分析
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.datasets import load_iris
from sklearn.metrics import r2_score, mean_squared_error, mean_absolute_error
from sklearn.model_selection import train_test_split
# データ読み込み
iris = load_iris()
X = iris.data[:, :3] # 3つの説明変数
y = iris.data[:, 3] # 目的変数(petal width)
# 学習用・テスト用に分割
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
# モデル学習
model = LinearRegression()
model.fit(X_train, y_train)
# 予測
y_pred = model.predict(X_test)
# ===== 評価 =====
print("R^2:", r2_score(y_test, y_pred))
print("MSE:", mean_squared_error(y_test, y_pred))
print("RMSE:", np.sqrt(mean_squared_error(y_test, y_pred)))
print("MAE:", mean_absolute_error(y_test, y_pred))
# ===== 可視化(予測 vs 実測)=====
plt.scatter(y_test, y_pred)
plt.xlabel("Actual")
plt.ylabel("Predicted")
plt.title("Multiple Regression: Actual vs Predicted")
plt.plot([y.min(), y.max()], [y.min(), y.max()], color="red") # 完全一致線
plt.show()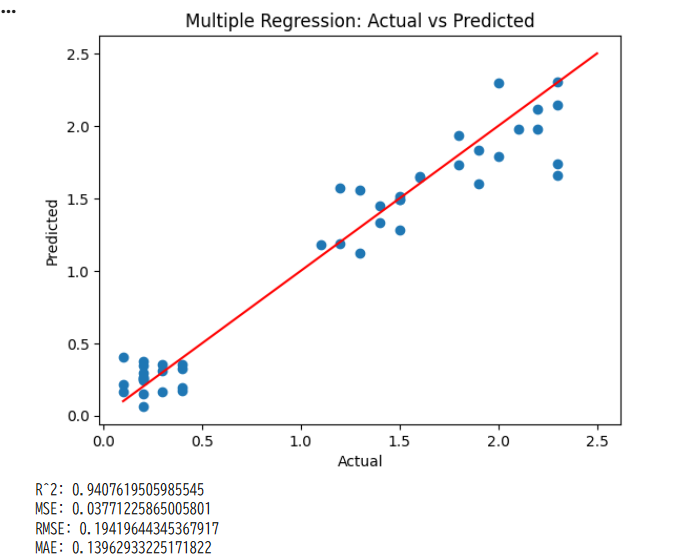
最小二乗法:AIはどうやって「最高の直線」を決めるのか?
ここで、少しだけ理屈のお話をします。AIは適当に直線を引いているわけではありません。最小二乗法(さいしょうにじょうほう) という賢いルールに従っています。
仕組みを高校生向けに解説
- まず、仮の直線を引いてみます。
- 実際のデータ点と、直線との「ズレ(誤差)」を測ります。
- そのズレを 2 乗して、全部足し合わせます。
- この「ズレの合計」が、世界で一番小さくなるような直線の角度と位置を探し出します。
なぜ 2 乗するのでしょうか?それは、ズレがプラスの場合とマイナスの場合があるからです。そのまま足すと 
メリットとデメリット
メリット
- とにかくシンプル: 計算が速く、中身が「数式」なので、なぜその予測になったのか人間が 100% 理解できます。
- 基本中の基本: どんなに複雑なディープラーニングも、根本を辿ればこの「ズレを最小にする」という考え方がベースになっています。
デメリット
- 曲がったことが大嫌い: データがグニャリと曲がった関係(非線形)を持っている場合、直線(線形)で無理やり予測しようとすると大きなミスをします。
まとめと次のステップへの指針
第2章では、数字のつながりを線で捉える「回帰」を学びました。
- 1つのヒントで予測するのが「単回帰」
- たくさんのヒントを使うのが「重回帰」
- ズレを最小にする魔法が「最小二乗法」
これで、数値の関係性を数式にする力が身につきましたね。
しかし、今のままでは「花の名前」という言葉を予測することはできません。なぜなら、言葉は数字ではないからです。
次回、第3章「線形分類編」では、この直線の考え方を応用して、いよいよ「グループを分ける境界線」を引く方法を学んでいきましょう。
「この線より右ならバージニカ!」といった具合に、AIがどうやって決断を下すのか、気になりませんか?
次は、確率を使って分類する「ロジスティック回帰」という、名前は回帰なのに分類が得意な不思議な手法を紹介します。お楽しみに!
第3章:線形分類編 - 境界線を引く基本
前回は、数字のつながりを一本の直線で表す「回帰」に挑戦しましたね。花弁の長さから幅をピタリと当てる直線の魔法、いかがでしたか?
今回は、いよいよ機械学習の真骨頂である「分類」の世界へ足を踏み入れます。回帰が「数値を当てる」ものだったのに対し、分類は「これは何の種類か?」というグループ分けを行う作業です。
皆さんは、リンゴとミカンを分けるとき、何を基準にしますか?色、形、手触り……。AIも同じように、データの中に「境界線」を引くことで、種類を見分けていくのです。
ロジスティック回帰:確率で白黒つける
名前に「回帰」と付いていますが、実はこれ、立派な「分類」の手法なんです。
ロジスティック回帰は、あるデータが特定のグループに属する「確率」を計算します。例えば、「この花がセトサである確率は 
この確率が 
仕組みを高校生向けに解説
- まず、前回学んだ回帰のように、データを元に計算式を作ります。
- その計算結果を、どんなに大きな数字も小さな数字も
の間に収めてしまう「シグモイド関数」という魔法の箱に通します。
- 出てきた数字を「確率」として扱い、分類を行います。
今回は 2クラス分類(Setosa vs Versicolor) に限定し、
2特徴量で可視化可能な形 にします。(境界は0.5)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# ===== データ準備 =====
iris = load_iris()
# 2クラス(0: setosa, 1: versicolor)
X = iris.data[:100, :2] # 2特徴量(sepal length, sepal width)
y = iris.target[:100]
# 学習用・テスト用分割
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
# ===== モデル学習 =====
model = LogisticRegression()
model.fit(X_train, y_train)
# ===== 予測 =====
y_pred = model.predict(X_test)
y_prob = model.predict_proba(X_test)[:, 1] # クラス1の確率
# ===== 可視化(決定境界)=====
x_min, x_max = X[:, 0].min() - 0.5, X[:, 0].max() + 0.5
y_min, y_max = X[:, 1].min() - 0.5, X[:, 1].max() + 0.5
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.3, cmap=plt.cm.Paired)
plt.scatter(X_test[:, 0], X_test[:, 1], c=y_test, edgecolors='k', cmap=plt.cm.Paired)
plt.xlabel("Sepal length")
plt.ylabel("Sepal width")
plt.title("Logistic Regression Decision Boundary")
plt.show()
# ===== 評価 =====
print("Accuracy:", accuracy_score(y_test, y_pred))
print("\nConfusion Matrix:\n", confusion_matrix(y_test, y_pred))
print("\nClassification Report:\n", classification_report(y_test, y_pred))
線形SVM:一番「余裕」のある境界線を引く
もう一つ、非常に賢い分類手法を紹介します。それが 線形SVM(サポートベクターマシン) です。
ロジスティック回帰が「確率」を考えるのに対し、SVMは「境界線の引き方の美学」を追求します。
例えば、2つのグループを分けるとき、ギリギリのところに線を引くと、新しいデータが来たときに間違えやすくなりますよね?SVMは、それぞれのグループの端っこにあるデータ(これをサポートベクターと呼びます)から、できるだけ遠く、一番広い「道幅」が確保できる場所に線を引きます。
この道幅のことを マージン と呼び、これを最大にすることを「マージン最大化」と言います。
Pythonで境界線を可視化してみよう
それでは、実際にアイリスのデータを使って、AIがどこに境界線を引いたのかを見てみましょう。今回は2つの特徴量(がく片の長さと幅)だけに絞って、視覚的に確認します。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# データの準備(2クラス・2特徴量)
iris = load_iris()
X = iris.data[:100, :2]
y = iris.target[:100]
# モデル学習
model = LogisticRegression()
model.fit(X, y)
# 予測
y_pred = model.predict(X)
# 境界線の描画
x_min, x_max = X[:, 0].min() - 0.5, X[:, 0].max() + 0.5
y_min, y_max = X[:, 1].min() - 0.5, X[:, 1].max() + 0.5
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.3, cmap=plt.cm.Paired)
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', cmap=plt.cm.Paired)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.show()
# ===== 評価指標 =====
print("Accuracy:", accuracy_score(y, y_pred))
print("\nConfusion Matrix:\n", confusion_matrix(y, y_pred))
print("\nClassification Report:\n", classification_report(y, y_pred))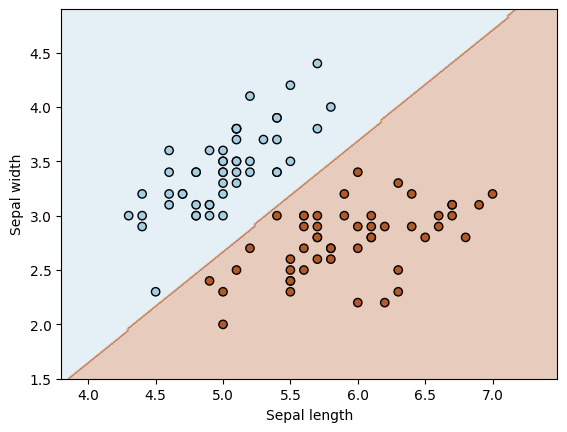
画面に、綺麗に色分けされたエリアが表示されましたか?これがAIの「決断の境界線」です!

メリットとデメリット
メリット
- 線形モデルの強み: 計算が非常に高速で、大規模なデータでも扱いやすいです。
- 解釈のしやすさ: どの特徴量が分類に強く影響したかが一目瞭然です。
デメリット
- 直線の限界: データが複雑に混ざり合っていて、曲線でしか分けられないようなケースには対応できません。これを「線形境界線の限界」と呼びます。
まとめと次のステップへの指針
第3章では、データを直線で切り分ける「線形分類」を学びました。
- 確率で判断を下す「ロジスティック回帰」
- ギリギリの境界を攻めて道幅を広げる「線形SVM」
- 境界線が見えると、AIが何を基準にしているかが見えてくる!
さて、もしデータが直線で分けられないほど複雑だったらどうしましょう?例えば、ミカンの中にリンゴが埋まっているような「ドーナツ型」のデータだったら?
次回、第4章「非線形・木モデル編」では、直線というルールを脱ぎ捨てて、もっと柔軟に、もっと複雑にデータを切り分ける強力な手法たちを紹介します。
「似たもの同士を隣に並べる」という直感的な方法や、クイズのように条件を分岐させる方法が登場しますよ。準備はいいですか?
次は、あの有名な「決定木」を使って、AIの思考プロセスを覗き見してみましょう!
第4章:非線形・木モデル編 - 複雑な境界線へ
前回は、真っ直ぐな線でデータを切り分ける「線形分類」を学びました。でも、現実の世界はそんなに単純な直線ばかりではありませんよね?例えば、森の中に点在する池の場所を特定しようとしたとき、一本の直線ではどうしても池を囲い込むことはできません。
今回は、そんな「直線では太刀打ちできない複雑なパターン」を攻略する、柔軟でパワフルな手法たちを紹介します。AIがもっと自由に、もっと人間味のある判断を下す様子を覗いてみましょう。
k近傍法 (k-NN):「類は友を呼ぶ」直感のアルゴリズム
まずは、もっとも直感的な手法である k近傍法(ケーきんぼうほう) です。
この手法のルールはたった一つ。「近くにいるものと同じ仲間だ」と決めることです。
例えば、知らない花が咲いていたとき、そのすぐ周りに咲いている 3 つの花が全部「セトサ」だったら、その知らない花も「セトサ」である可能性が高いですよね?
仕組みを高校生向けに解説
- 分類したい新しいデータ点を、図の中に置きます。
- その点から距離が近い順に
個(例えば 3 個や 5 個)のデータを選びます。
- 選ばれた
アイリスデータセットを使い、2クラス(setosa / versicolor)で2特徴量(可視化のため)で実装します。(k=3)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# ===== データ準備 =====
iris = load_iris()
# 2クラス & 2特徴量
X = iris.data[:100, :2]
y = iris.target[:100]
# 学習用・テスト用に分割
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
# ===== k近傍法モデル =====
k = 3
model = KNeighborsClassifier(n_neighbors=k)
model.fit(X_train, y_train)
# ===== 予測 =====
y_pred = model.predict(X_test)
# ===== 評価 =====
print("Accuracy:", accuracy_score(y_test, y_pred))
print("\nConfusion Matrix:\n", confusion_matrix(y_test, y_pred))
print("\nClassification Report:\n", classification_report(y_test, y_pred))
# ===== 可視化(決定境界)=====
x_min, x_max = X[:, 0].min() - 0.5, X[:, 0].max() + 0.5
y_min, y_max = X[:, 1].min() - 0.5, X[:, 1].max() + 0.5
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.3, cmap=plt.cm.Paired)
plt.scatter(X_test[:, 0], X_test[:, 1], c=y_test, edgecolors='k', cmap=plt.cm.Paired)
plt.xlabel("Sepal length")
plt.ylabel("Sepal width")
plt.title(f"k-NN (k={k}) Decision Boundary")
plt.show()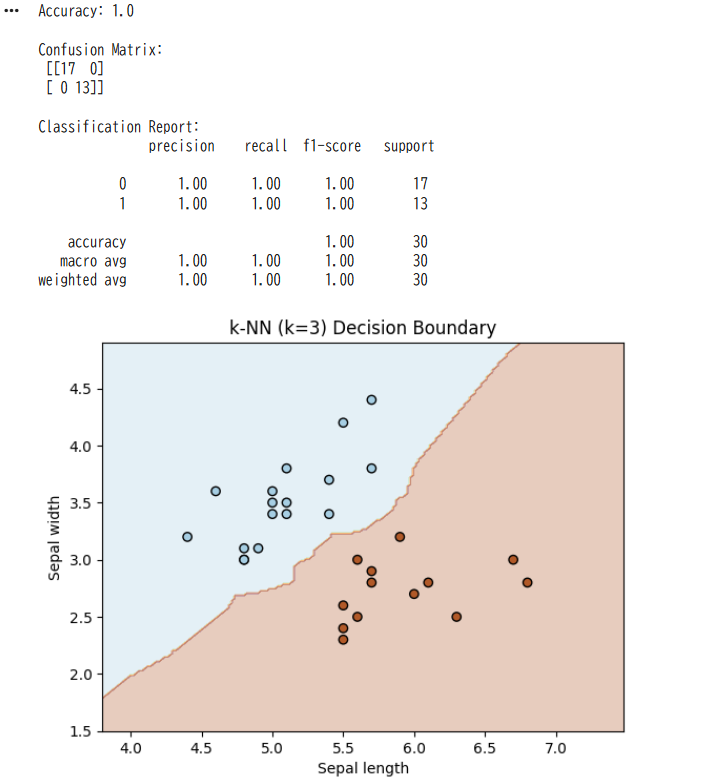
決定木 (Decision Tree):Yes/Noで分けるクイズ王
次に紹介するのは 決定木(けっていき) です。これは、データの特徴に対して「花弁の長さは 
皆さんも「アキネーター」という、質問に答えるだけで人物を当てるゲームで遊んだことはありませんか?決定木はまさに、あのゲームのようにデータを仕分けていきます。
仕組みを高校生向けに解説
- 根っこ(スタート)から始まり、一番情報をスッキリ分けられる質問を選びます。
- 質問の答えが Yes なら右、No なら左へとデータを流します。
- 最終的に、同じ種類のデータだけが集まる「葉っぱ」にたどり着くまで繰り返します。
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
# データの読み込み
iris = load_iris()
X, y = iris.data, iris.target
# 決定木モデルの作成(深さを制限して見やすくします)
clf = DecisionTreeClassifier(max_depth=3)
clf.fit(X, y)
# 木の構造を可視化
plt.figure(figsize=(12, 8))
plot_tree(clf, feature_names=iris.feature_names, class_names=iris.target_names, filled=True)
plt.show()

このコードを実行すると、AIがどのような基準で「もし〜なら」と判断しているのか、その思考プロセスが図(ツリープロット)として表示されます!
カーネルSVM:次元を飛ばして裏技で分ける
第3章で登場したSVM(サポートベクターマシン)の進化系が カーネルSVM です。
もし、平面上でデータが複雑に混ざり合っていて直線で分けられないなら、データを「高い次元( 3 次元など)」に放り投げてみましょう。
仕組みを高校生向けに解説
例えば、机の上に赤と青のおはじきが混ざって置かれているとします。これを直線で分けるのは難しいですが、赤のおはじきだけを「えいっ!」と空中に放り投げたらどうでしょう?
空中にある赤と、机の上にある青の間に、板を一枚差し込めば綺麗に分けられますよね。これがカーネル法のイメージです。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# ===== データ準備 =====
iris = load_iris()
# 2クラス(setosa, versicolor)
X = iris.data[:100, :2] # 2特徴量(可視化用)
y = iris.target[:100]
# 学習用・テスト用分割
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
# ===== カーネルSVMモデル =====
model = SVC(kernel="rbf", C=1.0, gamma="scale")
model.fit(X_train, y_train)
# ===== 予測 =====
y_pred = model.predict(X_test)
# ===== 評価 =====
print("Accuracy:", accuracy_score(y_test, y_pred))
print("\nConfusion Matrix:\n", confusion_matrix(y_test, y_pred))
print("\nClassification Report:\n", classification_report(y_test, y_pred))
# ===== 可視化(決定境界)=====
x_min, x_max = X[:, 0].min() - 0.5, X[:, 0].max() + 0.5
y_min, y_max = X[:, 1].min() - 0.5, X[:, 1].max() + 0.5
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.3, cmap=plt.cm.Paired)
plt.scatter(X_test[:, 0], X_test[:, 1], c=y_test,
edgecolors='k', cmap=plt.cm.Paired)
plt.xlabel("Sepal length")
plt.ylabel("Sepal width")
plt.title("Kernel SVM (RBF)")
plt.show()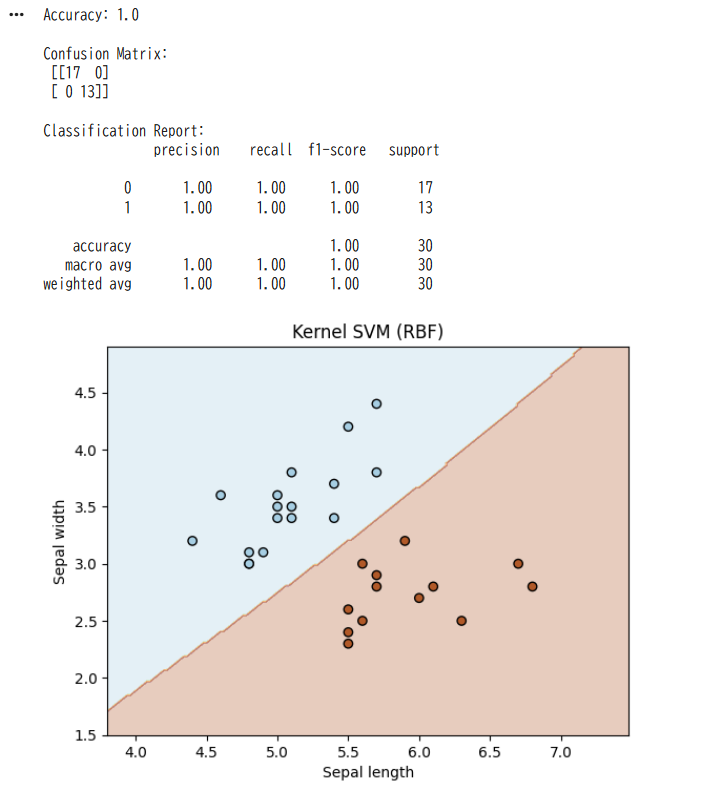
メリットとデメリット
メリット
- 柔軟性: 直線では不可能な、複雑でグニャグニャした境界線も引くことができます。
- 解釈性(決定木): なぜその答えになったのか、質問の枝を辿れば人間にも理解しやすいです。
デメリット
- 過学習(オーバーフィッティング): 複雑に分けすぎてしまい、手元のデータには完璧でも、新しいデータが来ると間違えてしまうことがあります。テスト勉強で「過去問の答え」だけを丸暗記して、本番の応用問題が解けない状態に似ています。
まとめと次のステップへの指針
第4章では、柔軟な思考を持つモデルたちを学びました。
- 近所の多数決で決める「k近傍法」
- Yes/Noの質問攻めで仕分ける「決定木」
- 高次元に飛ばして解決する「カーネルSVM」
これで、どんなに複雑な形のデータが来ても、戦う武器は揃いました。
しかし、一人の賢いAI(モデル)にも限界はあります。時には間違えることもあるでしょう。それなら、たくさんのAIを集めて「会議」を開かせたらもっと正確になると思いませんか?
次回、第5章「アンサンブル学習編」では、弱点を補い合う複数のモデルを束ねて、最強の予測精度を作り出すテクニックを伝授します。
「三人寄れば文殊の知恵」を機械学習で実現する方法、気になりませんか?お楽しみに!
第5章:アンサンブル学習編 - 弱者を束ねて最強を作る
前回は、複雑な境界線を描く「非線形モデル」や、クイズ形式で分類する「決定木」を学びました。AIが少しずつ賢くなっていく様子、ワクワクしませんか?
でも、一人の天才(一つのモデル)に頼りすぎるのは少し危険です。そのAIがたまたま苦手な問題が出たら、予測は外れてしまいますよね。そこで今回は、複数のモデルをチームとして動かし、多数決やリベンジで精度を極限まで高める「アンサンブル学習」という手法に挑戦します。
まさに「三人寄れば文殊の知恵」を地で行く、現代の機械学習で最も強力な武器の一つです!
ランダムフォレスト:たくさんの決定木で多数決
まず紹介するのは、第4章で学んだ「決定木」をたくさん集めた ランダムフォレスト です。
直訳すると「ランダムな森」。一本の木ではなく、森全体で答えを出す仕組みです。
仕組みを高校生向けに解説
- 元のデータから、ランダムに一部のデータを取り出します。
- そのデータを使って、少しずつ個性の違う「決定木」を 100 本くらい作ります。
- 未知のデータが来たら、 100 本の木全員に「これは何の花?」と聞きます。
- 最後に「多数決」を行い、一番票が多かった種類を最終回答にします。
一人の意見に偏らず、みんなで話し合って決めるので、一部のデータに惑わされる(過学習)ことが少なく、非常に安定した成績を叩き出します。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# ===== データ読み込み =====
iris = load_iris()
# 2特徴量(可視化用)
X = iris.data[:, :2]
y = iris.target
# 学習用・テスト用に分割
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
# ===== ランダムフォレスト =====
model = RandomForestClassifier(
n_estimators=100,
random_state=42
)
model.fit(X_train, y_train)
# ===== 予測 =====
y_pred = model.predict(X_test)
# ===== 評価 =====
print("Accuracy:", accuracy_score(y_test, y_pred))
print("\nConfusion Matrix:\n", confusion_matrix(y_test, y_pred))
print("\nClassification Report:\n", classification_report(y_test, y_pred))
# ===== 決定境界の可視化 =====
x_min, x_max = X[:, 0].min() - 0.5, X[:, 0].max() + 0.5
y_min, y_max = X[:, 1].min() - 0.5, X[:, 1].max() + 0.5
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.3, cmap=plt.cm.Paired)
plt.scatter(X_test[:, 0], X_test[:, 1],
c=y_test, edgecolors='k', cmap=plt.cm.Paired)
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.title("Random Forest Decision Boundary")
plt.show()
勾配ブースティング:前のミスのリベンジを繰り返す
次に、現代のデータコンペなどで「最強」の名を欲しいままにしている 勾配ブースティング です。代表的なものに XGBoost や LightGBM があります。
ランダムフォレストが「並列」にみんなで一斉に解くのに対し、こちらは「直列」に一人ずつ順番に解いていきます。
仕組みを高校生向けに解説
- 最初の AI が問題を解きます。当然、いくつか間違えます。
- 次の AI は、前の AI が「間違えた問題」に重点を置いて学習し、リベンジを果たします。
- これを何度も繰り返し、前のモデルの弱点を次々と補強していきます。
まるで、模試の後に「間違えたところだけ」を集中的に勉強して、次の模試に備える受験生のような学習スタイルですね。
Pythonでアンサンブルの力を試す
それでは、ランダムフォレストを使ってアイリスの分類をしてみましょう。
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# データの準備
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.3, random_state=42)
# ランダムフォレストモデルの作成と学習
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# 予測と精度の確認
y_pred = model.predict(X_test)
print(f"正解率: {accuracy_score(y_test, y_pred) * 100}%")
驚くほど高い精度が出たのではないでしょうか?これがチームプレーの力です。
メリットとデメリット
メリット
- 圧倒的な精度: 単独のモデルよりも遥かに高い予測能力を持ちます。
- データの癖に強い: 外れ値(変なデータ)が少し混ざっていても、多数決や補強によって影響を抑えることができます。
デメリット
- 中身がブラックボックス: 100 本以上の木の判断を全部追いかけるのは人間には不可能です。「なぜそうなったか」を説明するのが難しくなります。
- 計算コスト: 複数のモデルを動かすため、単純な手法よりは時間がかかります。
まとめと次のステップへの指針
第5章では、モデルを束ねてパワーアップさせる方法を学びました。
- 数を頼りに安定感を生む「ランダムフォレスト」
- 苦手を克服して精度を研ぎ澄ます「勾配ブースティング」
- 精度は高いが、中身が少し見えにくくなる(ブラックボックス化)
さて、これまでは「花の種類の答え」が最初から分かっているデータを使ってきました。しかし、もし世界に「答え(ラベル)」がないデータばかりだったらどうしますか?
次回、第6章「教師なし学習編」では、AIが自らデータの構造を見抜き、勝手にグループ分けを始めるという、さらに不思議な魔法をお見せします。
AIに「これ、いい感じに分けておいて」と頼むと、一体どうなるのでしょうか?
次は、データの裏側に隠れた「地図」を作る方法を紹介します。お楽しみに!
第6章:教師なし学習編 - ラベルに頼らず構造を見抜く
こんにちは。ゆうせいです。
これまでの章では、花の種類という「答え」が最初から用意されているデータを扱ってきました。このように、先生が答えを教えてくれるような学習スタイルを「教師あり学習」と呼びます。
でも、現実の世界では「答え」がついていないデータの方が圧倒的に多いんです。例えば、新しい惑星の観測データや、顧客の購買履歴など、誰にも正解が分からないものをどう整理すればいいのでしょうか。
今回は、AIが自らデータの共通点を見つけ出し、勝手にグループ分けをしてくれる 教師なし学習 の世界へご案内します。
k-means:AIが勝手にグループを見つける
まずは、もっとも代表的な手法である k-means(ケーミーンズ) です。
これは、あらかじめ「
仕組みを高校生向けに解説
- グラフの上に、適当に
- 全てのデータは、一番近いリーダーのチームに所属します。
- リーダーは、自分のチームになったメンバーたちの「ちょうど真ん中」に移動します。
- リーダーが動かなくなるまでこれを繰り返すと、自然と綺麗なグループが出来上がります。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
from sklearn.metrics import silhouette_score, adjusted_rand_score
# ===== データ読み込み =====
iris = load_iris()
X = iris.data
y = iris.target # 本来はクラスタリングでは使わない(評価用)
# ===== k-means =====
k = 3
kmeans = KMeans(n_clusters=k, random_state=42, n_init=10)
kmeans.fit(X)
labels = kmeans.labels_
# ===== 評価 =====
print("Inertia (クラスタ内誤差平方和):", kmeans.inertia_)
print("Silhouette Score:", silhouette_score(X, labels))
print("Adjusted Rand Index(正解との一致度):", adjusted_rand_score(y, labels))
# ===== 可視化(PCAで2次元化)=====
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
plt.figure(figsize=(8,6))
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=labels, cmap='viridis')
plt.title("k-means Clustering (k=3)")
plt.xlabel("PC1")
plt.ylabel("PC2")
plt.show()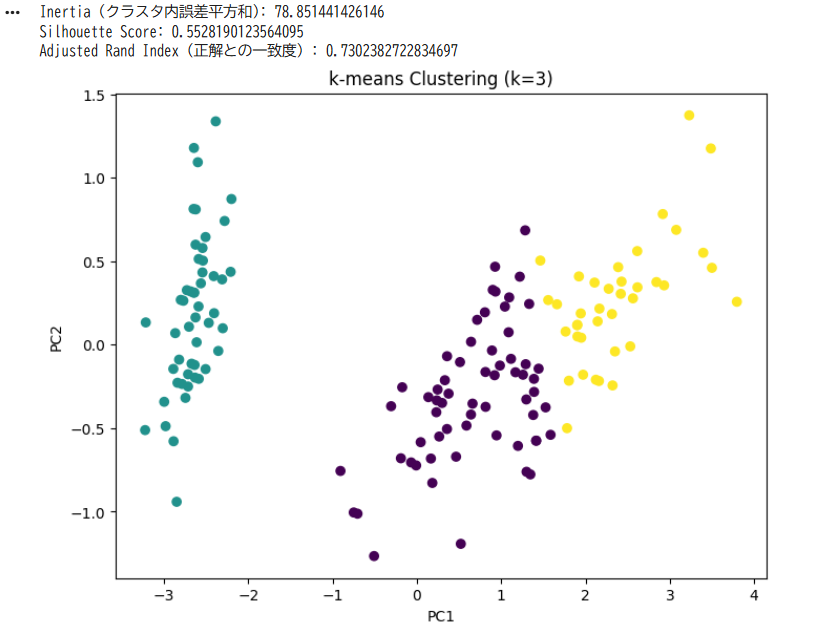
主成分分析 (PCA):情報をギュッと凝縮する
アイリスのデータには4つの項目(次元)がありましたね。でも、人間は4次元のグラフをイメージすることができません。そこで役立つのが 主成分分析(PCA) です。
これは、データの情報をできるだけ損なわないようにしながら、4次元を2次元や3次元に「圧縮」する技術です。
仕組みを高校生向けに解説
広い部屋に散らばった点々の影を、壁に映し出すようなイメージです。どの角度から光を当てれば、点々の広がり(情報)が一番よく見えるでしょうか?その「一番よく見える角度」を見つけ出して、平面の地図を作り直すのがPCAの役割です。
Pythonで4次元データを2次元の地図にする
実際にPCAを使って、4つの数字を2つの数字に圧縮し、アイリスの「地図」を描いてみましょう。
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
# データの読み込み
iris = load_iris()
X = iris.data
y = iris.target
# PCAで4次元から2次元へ圧縮
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
# 可視化
plt.figure(figsize=(8, 6))
colors = ['navy', 'turquoise', 'darkorange']
for i, color, name in zip([0, 1, 2], colors, iris.target_names):
plt.scatter(X_pca[y == i, 0], X_pca[y == i, 1], color=color, label=name)
plt.legend()
plt.title('PCA of IRIS dataset')
plt.show()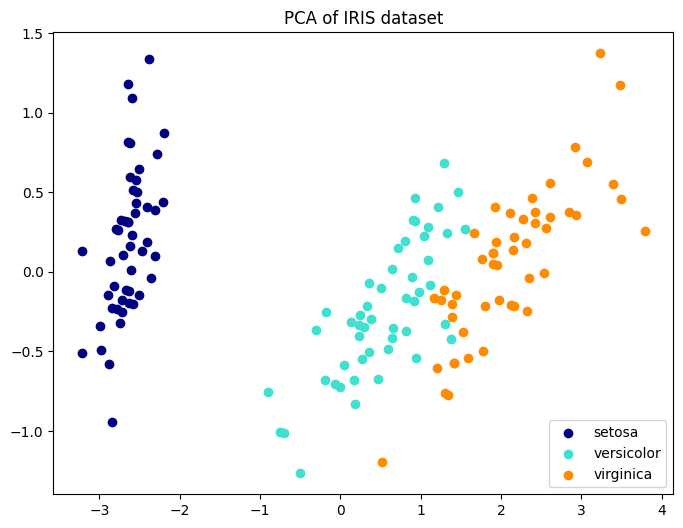
どうでしょうか?4つの数字をバラバラに見るよりも、2次元にまとめた方が「種類ごとの境界」がはっきりと見えてきませんか?
メリットとデメリット
メリット
- 答えがなくても分析できる: 誰も正解を知らない未知のデータから、新しい発見ができます。
- 可視化できる: 複雑なデータをシンプルな図に落とし込めるので、人間が理解しやすくなります。
デメリット
- 評価が難しい: 答えがないので「本当にこのグループ分けで正しいのか?」を客観的に判断するのが難しいという側面があります。
まとめと次のステップへの指針
第6章では、自律的にデータを整理する手法を学びました。
- リーダーが動いてチームを作る「k-means」
- 多次元を平面に投影して地図を作る「PCA」
- 隠れた構造を炙り出す「教師なし学習」
ここまでで、統計的な手法から最新のアンサンブル学習まで、幅広く攻略してきましたね。でも、最近話題の「生成AI」や「画像認識」の裏側には、まだ紹介していないもう一つの主役がいます。
次回、第7章「ディープラーニング編」では、いよいよ人間の脳を模した「ニューラルネットワーク」の扉を叩きます。
これまでの手法と何が違うのか、なぜそんなに賢いのか。その秘密を探りに行きましょう!
AIに「花」を認識させる脳みそを作ってみたいと思いませんか?
第7章:ディープラーニング編 - ニューラルネットワークの扉
こんにちは。ゆうせいです。
これまで、直線を引いたり、クイズ形式で分けたり、チームで多数決をしたりと、様々な手法でアイリスの正体に迫ってきました。いよいよこのシリーズもクライマックス。今回は、現代のAIブームの主役である ディープラーニング(深層学習) に挑戦しましょう!
ディープラーニングと聞くと「難しそう……」と身構えてしまうかもしれません。でも大丈夫。基本は、人間の脳にある神経細胞のネットワークをコンピュータの中に再現しようとする試みなんです。
多層パーセプトロン (MLP):脳の仕組みをシミュレートする
ディープラーニングの最も基本的な形が 多層パーセプトロン(MLP) です。
これは、入力層、隠れ層(中間層)、出力層という3つの階層で構成されています。
仕組みを高校生向けに解説
- 入力層: 花弁の長さなどのデータを受け取る窓口です。
- 隠れ層: ここが脳みその本体です!入力されたデータに「重み」をかけたり、複雑な計算をしたりして、特徴を見つけ出します。
- 出力層: 最終的に「これはセトサだ!」といった答えを出す出口です。
データが層を通り抜けるたびに、まるでバケツリレーのように情報が加工され、より高度な判断ができるようになります。この層を何枚も重ねて「深く」したものが、ディープラーニングというわけです。
活性化関数と最適化:賢くなるための隠し味
ニューラルネットワークを賢く動かすには、いくつかの重要な設定があります。
- 活性化関数(ReLUなど):次の層へ信号を伝えるときに「どれくらい強く伝えるか」を決めるフィルターです。例えば ReLU(レリュ) は、マイナスの信号はバッサリ切り捨て、プラスの信号だけをそのまま通します。これにより、ネットワークに複雑な表現力が生まれます。
- 最適化アルゴリズム(Adamなど):AIが学習するとき、予想と正解のズレを修正していく必要があります。 Adam(アダム) は、その修正を「どのくらいのスピードで、どの方向に」行うのが効率的かを自動で調整してくれる、非常に優秀なナビゲーターです。
Keras/PyTorchでの実装:AIを作るための道具
実際にディープラーニングのコードを書くとき、世界中で使われている2つの有名な道具(フレームワーク)があります。
- Keras (TensorFlow):初心者の方におすすめ!積み木を重ねるように、直感的にネットワークを組み立てることができます。
- PyTorch:現在、研究者やプロの間で最も人気があります。計算の途中経過が分かりやすく、より自由度の高い設計が可能です。
今回は、Kerasを使ってアイリスを分類する簡単なイメージを見てみましょう。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.datasets import load_iris
from sklearn.preprocessing import OneHotEncoder
from sklearn.model_selection import train_test_split
# データの準備
iris = load_iris()
X = iris.data
y = iris.target.reshape(-1, 1)
# 学習用とテスト用に分ける(8:2)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# ラベルを変換
encoder = OneHotEncoder(sparse_output=False)
y_train_enc = encoder.fit_transform(y_train)
y_test_enc = encoder.transform(y_test)
# モデルの構築
model = Sequential([
Dense(10, activation='relu', input_shape=(4,)),
Dense(10, activation='relu'),
Dense(3, activation='softmax')
])
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 学習の実行
print("AIが学習を開始します...")
model.fit(X_train, y_train_enc, epochs=50, batch_size=5, verbose=0)
# テストデータで評価
loss, accuracy = model.evaluate(X_test, y_test_enc, verbose=0)
print(f"テストデータの正解率: {accuracy * 100}%")
テストデータの正解率: 96.66666388511658%
メリットとデメリット
メリット
- 無限の可能性: データさえ大量にあれば、人間では気づけないような超複雑なパターンも見つけ出せます。
- 汎用性: 同じ仕組みを応用して、画像認識や翻訳など、あらゆる分野に使えます。
デメリット
- データ食い: アイリスのような少量のデータでは、せっかくのパワーを発揮しきれず、これまでの手法(ランダムフォレストなど)に負けることもあります。
- ブラックボックス: なぜその答えになったのかを人間が説明するのは、さらに難しくなります。
まとめと次のステップへの指針
第7章では、最新AIの心臓部であるディープラーニングを学びました。
- 情報をバケツリレーする「多層パーセプトロン」
- 信号を調整する「活性化関数」
- 効率よく学習を進める「最適化(Adam)」
これで、機械学習の主要な武器はすべて揃いました!
これまで色々な手法を学んできましたが、「結局、どれを使えばいいの?」と迷ってしまいますよね。
次回はいよいよ最終回、第8章「総括」です。
これまで学んだ全手法を戦わせ、それぞれの得意・不得意を整理して、皆さんがこれからどの道に進むべきか、最後の地図をお渡しします。
最強のモデルはどれだったのか……決着をつけに行きましょう!
それでは、最後の大詰めをお楽しみに!
アイリスデータセットで極める機械学習:最強のモデルはどれだ?完結編
ついにここまで辿り着きましたね!第1章のデータ観察から始まり、回帰、分類、そしてディープラーニングまで。皆さんはアイリスという小さな花を通して、機械学習の広大な地図を一周してきました。
最後となる今回は、これまでの戦いを振り返り、どの手法がどんな場面で「最強」なのかをハッキリさせましょう。
徹底比較!手法ごとの成績表
アイリスデータセット(テストデータ)に対して、これまでのモデルがどのようなパフォーマンスを見せたのか、一覧表にまとめました。
| 手法名 | 正解率(目安) | 解釈性(理由の分かりやすさ) | 学習スピード |
| ロジスティック回帰 | 95% 前後 | ◎ 非常に分かりやすい | 爆速 |
| 決定木 | 93% 前後 | ◎ 質問を辿れる | 速い |
| ランダムフォレスト | 97% 前後 | △ 少し複雑 | 普通 |
| 勾配ブースティング | 98% 前後 | × ほぼ中身は見えない | 少し遅い |
| ディープラーニング | 95% 〜 98% | × ブラックボックス | 遅い(設定次第) |
いかがでしょうか?「最新のディープラーニングが常に一番!」というわけではないことに驚いたかもしれませんね。
推論速度と解釈性のトレードオフ
ここで大切な専門用語、「トレードオフ」について解説します。
これは「何かを得れば、何かを失う」という、あちらを立てればこちらが立たずな関係のことです。
機械学習の世界では、主に 精度 と 解釈性 がトレードオフの関係にあります。
具体的な例え
- ロジスティック回帰(シンプル): 精度はそこそこですが、「なぜそう判断したのか」が明確です。銀行の融資審査など、理由の説明が求められる場面で大活躍します。
- ディープラーニング(複雑): 驚異的な精度を叩き出しますが、中身は数百万個の数字が絡み合う迷宮です。自動運転や画像認識など、「理屈より、とにかく正確に動いてほしい」場面で選ばれます。
精度だけを追い求めるのが正解ではなく、使う目的に合わせて最適な道具を選ぶのが、プロのデータサイエンティストへの第一歩です!
結局、どれが最強だったのか?
アイリスデータセットのような「綺麗でデータ数が少ない」ケースでは、ランダムフォレスト や SVM が最もバランスが良く、最強と言えるでしょう。
ディープラーニングは、数万、数百万という大量のデータがあって初めて本領を発揮します。150件ほどのアイリスデータでは、重火器を持ち出してアリを退治するようなもので、少しオーバーパワー(過剰)なのです。
今後の学習の指針:次に学ぶべきこと
このシリーズを通して、皆さんは機械学習の基礎体力をしっかり身につけました。次に挑戦するなら、以下の3つのルートがおすすめです!
- データの種類を変えてみる(画像への挑戦):数字のデータの次は、画像データに挑戦しましょう。「MNIST」という手書き数字のデータセットを使えば、ディープラーニングの本当の凄さを体感できます。
- より大きなデータに挑む(Kaggleに登録):世界中のエンジニアが精度を競う「Kaggle(カグル)」というサイトがあります。ここで公開されている、より複雑なデータセットで腕試しをしてみてください。
- 数学的な裏側を覗いてみる:今回さらっと流した数式の裏側には、微分や線形代数といった数学の魔法が隠れています。少しずつ数式と仲良くなると、モデルの「気持ち」がより深く理解できるようになります。
これで「アイリスデータセットで極める機械学習完全制覇」は完結です。
皆さんがこれからAIという魔法を使って、どんな未来を作っていくのか、私はとても楽しみにしています。
また別のテーマでお会いしましょう。お疲れ様でした!
セイ・コンサルティング・グループでは新人エンジニア研修のアシスタント講師を募集しています。
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。

