最低限知っておきたいPythonの文法
 山崎講師
山崎講師この記事では、当社のPython関連の研修に参加される方のために知っておきたい基本事項や考え方をまとめました。
サンプルコードはGoogle Colabにも置いてあります。
1. Python言語の特徴
Pythonの特徴は以下の4点です。
1. クロスプラットフォーム環境
PythonはWindows、macOS、Linuxなど各種OSで公式のインタプリタが提供されており、どこでも実行可能です。
2. 多様なプログラミングパラダイムのサポート
Pythonはオブジェクト指向だけでなく、手続き型や関数型といった複数のパラダイムをサポートしており、プログラミングの基本概念を学ぶのに適しています。
3. シンプルな文法と他言語への橋渡し
文法がシンプルで読みやすく、初心者でも理解しやすい点はもちろん、他の言語(C、Java、JavaScriptなど)との共通概念も多いため、後々の他言語習得にも役立ちます。
4. 幅広い活用分野
データサイエンス、機械学習、Webアプリケーション、スクリプトによる自動化など、幅広い分野で利用されているため、どのようなお仕事をされていても役立ちます。
2. Pythonプログラムの実行
Pythonでは、プログラムコードは基本的にインタプリタによって直接実行されます。
内部的には、ソースコードが自動的にバイトコード(.pycファイル)にコンパイルされ、Python仮想マシン(PVM)上で実行されますが、このプロセスはユーザーが意識する必要はほとんどありません。
例:Hello World プログラム
以下のコードをエディタに入力してみましょう。
print("hello, world")注意点:
- キーボードから入力する際、全角と半角の区別に注意してください。数値や英字は半角で入力する必要があります(IMEの設定変更を行うなどの対策をお勧めします)。
- 保存先は、例えばCドライブ直下のpythonフォルダなどに新規保存し、ファイル名は
sample01.pyとします。
コマンドラインでの実行
以下のように実行してみましょう。
> python example01.py
hello, world
今後はIDE(例: Visual Studio Codeなど)を活用すると、ワンクリックで実行できるため、より効率的に開発できます。
3. エラーを恐れない
プログラム開発ではエラーはつきものです。積極的にエラーを発生させ、その原因を探ることが上達の秘訣です。
エラーの例
以下の例は、ダブルクォーテーションとシングルクォーテーションと、かっこの対応が取れていないためエラーになります。
print("Hello')
実行すると、Pythonは「SyntaxError: unterminated string literal (detected at line 1)」といったエラーメッセージを表示し、プログラムは終了します。
エラーメッセージには、どの行で何が起きたか重要な情報が含まれているので、必ず読んで理解する習慣をつけましょう。
4. プログラムはメモリ上にロードされて実行される
Pythonプログラムも、ソースコードがバイトコードに変換され、メモリ上にロードされて実行されます。この過程を理解しておくと、プログラムの動作原理やエラー発生時の挙動、パフォーマンス最適化の際に役立ちます。
また、CPUはプログラムの命令を実行し、メモリはデータの一時的な保管場所として機能します。これらの役割は、どのプログラミング言語でも共通の考え方です。
5. システムに必要なIPO
システムという概念は、「仕組み」を意味し、その基本構成は以下の3要素で成り立ちます。
- Input(入力)ユーザーや他のシステムからの情報やデータ。
- Process(処理)入力された情報を加工・解析し、目的の処理を実行。
- Output(出力)処理結果を画面やファイル、他のシステムへ出力する。
例えば、Pythonで電卓プログラムを作成する場合、ユーザーから数値を入力(Input)し、計算処理を行い(Process)、結果を表示(Output)する、という流れになります。
このようなIPOの考え方は、システム開発の基本であり、どの言語でも重要です。
6. コメントの入れ方
コメントは、コードに対する人間向けのメモです。Pythonでは以下の方法で記述します。
- シングルラインコメント
行の先頭に # を付けることで、その行の残りをコメントにできます。
print("Hello World")- 複数行コメント(ドキュメンテーション文字列)
3つのシングルクォート(''')またはダブルクォート(""")で囲む方法です。主に関数やクラスの説明に使われます。
"""
この関数は、Hello Worldを表示
します。
作成者: yamazaki
作成日: 20XX/11/09
"""
def main():
print("Hello World")コメントは、後で自分や他の人がコードを読み返すときの大切な手掛かりとなるため、積極的に記述しましょう。
7. エラーへの対処
Pythonでは、エラーは大きく分けて以下の3種類に分類されます。
- 文法エラー(SyntaxError)プログラムが正しい文法で書かれていない場合、実行前にエラーが検出されます。
- 実行時エラー(RuntimeError)実行中に発生するエラー。例:ゼロ除算エラー、インデックスエラーなど。
- 論理エラープログラムは実行されるが、期待した結果が得られないエラーです。※論理エラーは、テストやデバッガを使って検出する必要があります。
エラーメッセージには、エラー発生箇所や原因が示されるため、必ずその内容を確認し、生成AIで対策を調べましょう。
8. 標準出力
Pythonにおいて、標準出力とは、プログラムが結果を表示するための出力先(コンソールなど)を指します。
標準出力には print() 関数を使用します。
print("Hello World")print()は自動的に改行を付けて出力します。- 改行が不要な場合は、
endパラメータを利用できます(例:print("Hello", end=""))。
標準出力を利用することは、デバッグやプログラムの動作確認にも非常に有効です。
まとめ(導入編)
以上、Pythonの基本的な特徴や実行方法、プログラムの構成、オブジェクト指向の考え方、エラー処理、コメントの付け方、標準出力の利用方法などについて解説しました。
Pythonは以下の点で異なります。
- シンプルな文法と動的型付け→ コードが読みやすく、初心者にも取り組みやすい。
- コンパイルの概念がユーザーに隠蔽されている→ ソースコードをそのまま実行できるため、環境構築が簡単。
ただし、厳密な型チェックやアクセス修飾子は存在しないため、コードの規模が大きくなるときは、設計やテストに特に注意が必要です。
Pythonはそのシンプルさと多機能性から、初学者が最初に取り組むプログラミング言語としても、プロフェッショナルが活用する言語としても非常に有用です。ぜひ、この記事を参考に、Pythonの世界に飛び込んでみてください!
次章では変数とデータ型を学びます。
1. 変数とデータ型をマスター
Pythonプログラミングの世界へようこそ!
この章では、あなたがコンピュータと対話するための、本当に最初の、そして最も重要な一歩を踏み出します。難しく考えないでくださいね。まずはコンピュータを「ちょっと賢い電卓」として使うところから始めてみましょう!
準備はいいですか?まずはコンピュータに計算をお願いしてみよう!
プログラミングの第一歩として、Pythonに簡単な計算をさせてみましょう。まるで電卓に打ち込むような感覚で大丈夫ですよ。
例えば、足し算や引き算は次のように書きます。
print(1 + 2)これを実行すると、コンピュータは 3 という答えを返してくれます。簡単でしょう?
掛け算は * (アスタリスク)、割り算は / (スラッシュ)という記号を使います。学校で習った記号とは少し違うので、覚えておきましょう!
print(5 * 3)
# 15
print(10 / 2)
# 5.0この他にも、割り算の「あまり」を求める % (パーセント)や、「べき乗」(同じ数を何回か掛けること)を計算する ** など、便利な計算機能がたくさんあります。
print(10 % 3)
# 1
print(2 ** 3)
# 8ここで少し専門用語を紹介しますね。+ や * のような計算の種類を指示する記号を「演算子(えんざんし)」と呼びます。料理で例えるなら、「切る」「焼く」「煮る」といった調理方法の指示みたいなものです。
そして、 5 * 3 のように、演算子と数値を組み合わせた計算式全体を「式(しき)」と呼びます。式は、コンピュータによって計算され、必ず一つの「値(あたい)」(計算結果)を生み出します。
計算結果をしまっておく魔法の箱「変数」
さて、計算はできるようになりましたが、計算結果を後からもう一度使いたい時、どうすればいいでしょうか?毎回同じ計算を打ち込むのは少し面倒ですよね。
そんな時に登場するのが「変数(へんすう)」です!
変数を一言でいうと、「データに名前をつけて保存しておくための箱」のようなものです。この箱にデータを入れておけば、後から名前を呼ぶだけで何度でも中身を取り出して使えます。
実際にコードを見てみましょう。例えば、税込み価格を計算する場面を想像してください。
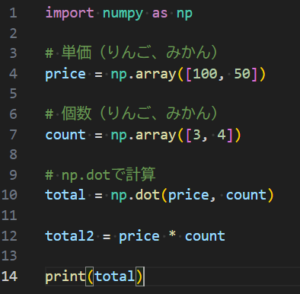
price = 150
tax_rate = 0.1
sales_tax = price * tax_rate
total_price = price + sales_tax
print(total_price)これを実行すると、画面には 165.0 と表示されます。
何が起きているか、一行ずつ見ていきましょう!
- price = 150
priceという名前の変数(箱)を用意して、その中に150という数値を入れています。 - tax_rate = 0.1
同じように、tax_rateという名前の変数に0.1(消費税10%)を入れています。 - sales_tax = price * tax_rate
priceとtax_rateの中身を取り出して掛け算し、その結果(15.0)をsales_taxという新しい変数に入れています。 - total_price = price + sales_tax
最後に、price(150)とsales_tax(15.0)を足し算した結果をtotal_priceに入れています。 - print(total_price)
print()は、カッコの中に入れた変数の値を画面に表示してくれる命令です。
ここで一つ、非常に重要なルールがあります。プログラミングの世界で使う = は、数学の「等しい」という意味ではありません。「右側の値を、左側の変数に代入する(だいにゅうする)」という意味の命令記号なのです。これを「代入演算子」と呼びます。
変数を使うことには、たくさんのメリットがあります。
- 再利用が簡単:同じ値を何度も使いたい時に、変数名を呼ぶだけで済みます。
- 意味が明確になる:ただ
150と書くよりもpriceと書いた方が、「これは価格なんだな」と後から見ても分かりやすいですよね。 - 修正が楽になる:もし税率が8%に変わったら?
tax_rate = 0.08と、たった一箇所を直すだけで、関連するすべての計算結果が自動的に変わります。便利だと思いませんか?
「数値」と「文字」は違う?データ型という考え方
突然ですが、コンピュータにとって 100 という「数値」と、 "100" という「文字」は、全くの別物として扱われます。驚きですよね?
人間にとっては同じに見えても、コンピュータはそれぞれのデータがどんな「種類」なのかを厳密に区別しています。このデータの種類のことを「データ型(データがた)」と呼びます。
なぜデータ型が重要なのでしょうか?それは、データ型によって「できること」と「できないこと」が変わってくるからです。
こちらのコードを見てください。
# 数値同士の足し算
number1 = 100
number2 = 200
print(number1 + number2)
# 結果: 300
# 文字同士の足し算
text1 = "100"
text2 = "200"
print(text1 + text2)
# 結果: 100200一つ目のprintは、300という計算結果を表示します。これは予想通りですね。
しかし、二つ目のprintは、なんと100200と表示します。
これは、 + という演算子が、相手にするデータ型によって振る舞いを変えるためです。
- 相手が数値なら「足し算」
- 相手が文字なら「連結(れんけつ)」
このように、データ型を意識しないと、思わぬ結果につながることがあります。プログラミングの基本として、代表的なデータ型をいくつか覚えておきましょう。
- 整数型(int):
100や-5のような、小数点のない数値です。integer(整数)の略です。 - 浮動小数点数型(float):
3.14や0.1のような、小数点を含む数値です。 - 文字列型(str):
"こんにちは"や"Python"のように、"(ダブルクォーテーション)か'(シングルクォーテーション)で囲まれた文字の並びです。string(文字列)の略です。
自分が使っている変数のデータ型が何か分からなくなった時は、type() という便利な命令で確認できます。
price = 150 # 整数
tax_rate = 0.1 # 浮動小数点数
message = "ありがとう" # 文字列
print(type(price))
print(type(tax_rate))
print(type(message))実行すると、それぞれ <class 'int'>, <class 'float'>, <class 'str'> と表示され、変数のデータ型を教えてくれます。
まとめ:最初の扉を開けました!
お疲れ様でした!この章では、プログラミングの本当に基礎となる3つの重要な概念を学びましたね。
- 式と演算:コンピュータに計算をさせる方法
- 変数:データに名前をつけて保存しておく魔法の箱
- データ型:数値や文字といったデータの種類
これらは、これからあなたが書くすべてのプログラムの土台となる知識です。一つ一つの意味をしっかり理解しておきましょう。
さて、今は一つの変数に一つのデータしか入れられませんでした。でも、例えばクラスの生徒全員の名前を管理したい時、一人ひとりの変数を用意するのは大変そうですよね?
次の章では、たくさんのデータを一つの変数でまとめて扱う方法について学んでいきます。プログラミングの可能性が、さらにグッと広がりますよ!期待していてください!
2. コンテナを使ってデータを整理
前章では、変数という魔法の箱にデータを入れる方法を学びましたね。でも、もし管理したいデータが100個、1000個と増えていったらどうでしょう? score1, score2, score3... なんて変数を延々と作り続けるのは、考えるだけで気が遠くなりそうですよね。
そこで今回は、たくさんのデータを一つの変数でまとめてスッキリ管理するための、超便利な道具「コンテナ」について学んでいきましょう!
データが増えてくると変数は大変?
例えば、あなたが5人の生徒のテストの点数を管理したいとします。これまでの知識だけだと、こんな風に書くことになるかもしれません。
student1_score = 88
student2_score = 92
student3_score = 75
student4_score = 80
student5_score = 955人ならまだしも、これが40人のクラスだったら...?変数を40個も作るのは現実的ではありません。それに、全員の点数の合計を計算するのも一苦労です。
こんな「たくさんの、関連性のあるデータ」を扱うために、Pythonには「コンテナ」という仕組みが用意されているのです。コンテナは、その名の通り、複数のデータを入れておける大きな容器のようなもの。早速、代表的なコンテナを見ていきましょう!
まずはコレを覚えよう!「リスト」
最もよく使われるコンテナが「リスト」です。リストは、複数のデータを「順番に」並べて格納することができます。デパートの案内板や、スマホの連絡先リストのように、データがズラッと並んでいるイメージですね。
リストの作り方と特徴
リストを作るのはとても簡単。[](角括弧)でデータをカンマ区切りで囲むだけです。
scores = [88, 92, 75, 80, 95]
print(scores)これを実行すると、[88, 92, 75, 80, 95] と、リストの中身がそのまま表示されます。さっきよりもずっとスッキリしましたね!
リストの最大の特徴は、格納したデータに「順番」があることです。そして、その順番を示す「インデックス番号」というものが、先頭から0, 1, 2, 3 ... と自動的に割り振られます。
注意してください!
プログラミングの世界では、なぜか順番を0から数えるのがお約束なんです。これは絶対に覚えておきましょう!
このインデックス番号を使えば、特定の一つだけのデータを取り出すことができます。
scores = [88, 92, 75, 80, 95]
# 0番目(先頭)のデータを取り出す
print(scores[0])
# 2番目(3番目)のデータを取り出す
print(scores[2])実行結果は、それぞれ 88 と 75 になります。
さらに、リストは中身を自由に追加したり、変更したり、削除したりできます。こういう「後から変更できる」性質を、専門用語で「ミュータブル(mutable)」と言います。
scores = [88, 92, 75]
# 新しいデータを末尾に追加する
scores.append(100)
print(scores)
# [88, 92, 75, 100] になる
# 1番目のデータを書き換える
scores[1] = 85
print(scores)
# [88, 85, 75, 100] になるappend はリストに用意されている「追加」の機能です。このように、リストにはデータを操作するための便利な機能がたくさん備わっています。
名前でデータを管理する「ディクショナリ」
リストは順番でデータを管理するのに便利でしたが、もし「順番」ではなく「名前」でデータを管理したい場合はどうでしょうか。例えば、「tanakaさんの点数」「suzukiさんの点数」のように。
そんな時に大活躍するのが「ディクショナリ」(辞書)です。
ディクショナリの作り方と特徴
ディクショナリは、 {} (波括弧)を使い、「キー」と「値(バリュー)」をペアにしてデータを作ります。: の左側がキー、右側が値です。
scores = {"tanaka": 88, "suzuki": 92, "sato": 75}
print(scores)まるで本物の辞書で単語(キー)を引くと意味(値)が書かれているように、ディクショナリではキーを指定することで、対応する値を取り出すことができます。
scores = {"tanaka": 88, "suzuki": 92, "sato": 75}
# "suzuki"さんの点数を取り出す
print(scores["suzuki"])
これを実行すると 92 が表示されます。リストがインデックス番号でデータを取り出したのに対し、ディクショナリはキーでデータを取り出す、という違いが分かりましたか?
もちろん、ディクショナリもリストと同じで「ミュータブル」です。後から新しいキーと値のペアを追加したり、既存の値を変更したりできます。
scores = {"tanaka": 88, "suzuki": 92}
# 新しいデータを追加する
scores["watanabe"] = 80
print(scores)
# {'tanaka': 88, 'suzuki': 92, 'watanabe': 80} になる
# "tanaka"さんの点数を変更する
scores["tanaka"] = 90
print(scores)
# {'tanaka': 90, 'suzuki': 92, 'watanabe': 80} になるリストとディクショナリ、この二つを使いこなせるようになれば、扱えるデータの幅が大きく広がりますよ!
まとめ:データ整理の達人になろう!
お疲れ様でした!今回は、たくさんのデータをまとめて扱うためのコンテナを学びました。
- リスト:順番が重要で、後から変更もしたいときに使う万能選手。
- ディクショナリ:順番より「名前(キー)」でデータを管理したいときに最適。
コンテナには他の種類もありますが、まずは基本となる「リスト」と「ディクショナリ」の二つをしっかりマスターしましょう!
さて、データを整理する道具は手に入れました。でも、プログラムはまだ上から下へ一直線にしか進みません。次の章では、いよいよプログラムに「もし○○だったら、△△する」といった、状況に応じた判断をさせるための「条件分岐」を学びます。プログラミングが、もっと「賢く」なりますよ!お楽しみに!
3. if文でプログラムに判断をさせよう
これまでのプログラムは、書かれたコードを上から下へ、一本道をまっすぐ進むだけでしたね。でも、私たちの日常を思い浮かべてみてください。「もし雨が降っていたら、傘を持っていく」「もしお腹が空いていた ら、ご飯を食べる」というように、私たちは常に状況に応じて行動を変えています。
今回は、プログラムにそんな「もし○○だったら、△△する」という、状況判断の能力を与える魔法、「条件分岐」を学んでいきます。この章を終える頃には、あなたのプログラムは単なる命令の実行者から、賢い判断ができるパートナーへと進化しますよ!
プログラムの流れをコントロールするということ
プログラムは、一つ一つの命令文、これを「文(ぶん)」と呼びますが、その集まりでできています。通常、これらの文は記述された順に実行されます。
しかし、時には特定の条件の時だけ実行したい文や、条件によって実行する文を変えたい場合がありますよね。このように、プログラムの実行の流れを意図的に変える仕組みのことを「制御構造(せいぎょこうぞう)」と呼びます。
今回学ぶ「条件分岐」は、この制御構造の最も基本的で重要なものの一つです。さあ、プログラムの流れを自由に操るための第一歩を踏み出しましょう!
「もし~なら」を実現するif文
条件分岐の基本となるのが if文 です。英語の "if" と同じで、「もし~ならば、...する」という意味を表します。
その構造は非常にシンプルです。
if 条件式:
条件が満たされた(真)場合に実行する処理
ifの後に判断の基準となる「条件式」を書き、その末尾には必ず : (コロン)をつけます。そして次の行から、条件が満たされたときに実行したい処理を、少し字下げ(インデント)して書きます。この字下げが「この処理はif文の一部ですよ」という目印になる、Pythonの非常に重要なルールです!
例えば、テストの点数が60点以上なら「合格」と表示するプログラムを見てみましょう。
score = 85
if score >= 60:
print("合格です!おめでとうございます。")このコードでは、まず変数 score に 85 を代入しています。
次にif文で score >= 60 という条件式を評価します。85は60以上なので、この条件は満たされます(専門用語では「真(しん)」と言います)。
条件が真なので、字下げされたprint文が実行され、画面に「合格です!おめでとうございます。」と表示される、という仕組みです。
もし score が50だったら、条件は満たされない(「偽(ぎ)」と言います)ので、print文は実行されず、プログラムは何も表示せずに終了します。
TrueかFalseか?コンピュータの判断基準
if文が使っている「条件式」は、コンピュータにとって「Yes」か「No」か、つまり「真(True)」か「偽(False)」かのどちらか一方の答えしか出ない式のことを指します。
この判断のために使われるのが「比較演算子(ひかくえんざんし)」です。数学で習った等号や不等号と似ていますが、少し違う記号もあるのでここでしっかり覚えましょう!
| 意味 | 演算子 | 例 (age = 20) | 結果 |
| 等しい | == | age == 20 | True |
| 等しくない | != | age != 20 | False |
| より大きい | > | age > 20 | False |
| より小さい | < | age < 20 | False |
| 以上 | >= | age >= 20 | True |
| 以下 | <= | age <= 20 | True |
ここで絶対に注意してほしいのが、 = と == の違いです。
=は「代入」を意味します。x = 5は「xという変数に5を入れる」という命令です。==は「比較」を意味します。x == 5は「xの中身は5と等しいですか?」という質問です。
これを間違えると、プログラムは全く意図通りに動かなくなってしまうので、しっかり区別してくださいね!
判断のバリエーションを増やそう!
「もし~なら」だけでなく、「~でなかったら」「もし~ならA、そうでなくBならC、どちらでもなければD」のように、もっと複雑な判断をさせたい時もありますよね。そのための構文もちゃんと用意されています。
if-else構文:「もし~なら、さもなければ」
条件が満たされなかった場合に、必ず何か別の処理を実行させたい。そんな時に使うのが else です。
age = 18
if age >= 20:
print("お酒をどうぞ。")
else:
print("20歳になってからお越しください。")このプログラムでは、 age は 18 なので age >= 20 という条件は満たされません(偽)。すると、ifのブロックは無視され、 else: に続くブロックが実行されます。結果として「20歳になってからお越しください。」と表示されます。
if-elif-else構文:3つ以上の選択肢
選択肢が3つ以上ある場合はどうでしょう?そんな時は elif (else if の略)の出番です。
elif を使うと、最初のifの条件が偽だった場合に、さらに別の条件で判断を続けることができます。
score = 75
if score >= 90:
print("評価はSです。素晴らしい!")
elif score >= 80:
print("評価はAです。優秀です。")
elif score >= 70:
print("評価はBです。良い調子ですね。")
else:
print("評価はCです。次回頑張りましょう!")このコードは、上から順番に条件をチェックしていきます。
score >= 90? → 75なので偽。次に進む。score >= 80? → 75なので偽。次に進む。score >= 70? → 75なので真!ここの処理を実行。結果として「評価はBです。良い調子ですね。」と表示されます。
elifの条件が一度でも真になったら、それ以降のelifやelseはすべて無視される、という点もポイントです。
まとめ:プログラムに知性を与えよう!
お疲れ様でした!この章では、プログラムの流れを自在に操る「条件分岐」について学びました。
- if文:「もし~なら」という基本的な条件判断を行う。
- 比較演算子:
==や>など、条件式の判断基準となる記号。 - インデント:字下げによって、処理のまとまりを示すPythonの重要なルール。
- if-else:「もし~なら、そうでなければ」という2択の分岐。
- if-elif-else:3つ以上の選択肢を持つ、より複雑な分岐。
if文をマスターしたあなたは、もはやプログラムに「知性」を与える方法を手に入れたと言っても過言ではありません。
さて、状況に応じて処理を変えることはできるようになりました。ですが、「同じ処理を100回繰り返したい」といった場合はどうでしょう?print文を100行書くのは大変ですよね。
次の章では、面倒な繰り返し処理をコンピュータに自動で実行させる、もう一つの重要な制御構造「繰り返し」について学んでいきます。プログラミングの効率が、劇的にアップしますよ!ぜひ、楽しみにしていてくださいね。
4. 繰り返しで面倒な作業を秒殺しよう!
3章では、if文を使ってプログラムに状況判断をさせる方法を学びましたね。これにより、プログラムはより賢く、柔軟な動きができるようになりました。しかし、もし「『こんにちは』と100回表示してください」とお願いされたら、どうしますか? print("こんにちは") を100行も書くなんて、想像するだけでうんざりしてしまいますよね。
プログラミングの真の力は、こうした「面倒な繰り返し作業」をコンピュータに肩代わりさせられる点にあります。今回は、そのための強力な武器である「繰り返し処理」をマスターしていきましょう。この章を終えれば、あなたは退屈な作業から解放され、より創造的なことに時間を使えるようになりますよ!
基本的な繰り返しの形「while文」
まず紹介するのは while文 です。これは「ある条件を満たしている間、ずっと処理を繰り返す」という命令です。英語の "while" (~の間)と全く同じ意味ですね。
while文の構造はif文とよく似ています。
while 条件式:
条件が満たされている(真)間、繰り返す処理
whileの後に「条件式」を書き、:(コロン)をつけます。そして、繰り返したい処理を字下げ(インデント)して書く。このルールもif文と同じです。
では、1から5までの数字を順番に表示するプログラムを見てみましょう。
# カウンター用の変数を用意し、初期値を1にする
count = 1
# countが5以下の間、処理を繰り返す
while count <= 5:
print(count)
# countの値を1増やす(これをしないと無限にループします!)
count = count + 1
print("処理が終了しました。")
このコードの動きを、一緒に追いかけてみましょう。- 最初に変数
countに1が入ります。 - while文の条件
count <= 5をチェックします。1は5以下なので、条件は真です。 - 字下げされたブロックが実行されます。
print(count)で1が表示されます。 - 次に
count = count + 1が実行され、countの中身が2になります。 - ブロックの最後まで来たので、再びwhileの条件チェックに戻ります。
count <= 5をチェック。2は5以下なので、真です。print(count)で2が表示され、countが3になります。- ...これを繰り返し...
- countが5の時、
print(count)で5が表示され、countが6になります。 - whileの条件チェックに戻り
count <= 5を評価します。6は5以下ではないので、条件は偽となります。 - while文の繰り返しが終了し、ループを抜け出します。
- 最後に
print("処理が終了しました。")が実行されます。
while文で最も注意すべき点は、ループ内で条件式に関わる変数の値を更新し、いつか必ずループが終わるように設計することです。もし count = count + 1 の一行を忘れてしまったら、countは永遠に1のままなので、条件は常に真となり、プログラムは無限に1を表示し続けて終了できなくなってしまいます(これを無限ループと呼びます)。
こちらが本命!「for文」による繰り返し
while文は条件が複雑な場合に役立ちます。ですが、単に「リストの全要素に対して同じ処理をしたい」とか「10回だけ処理を繰り返したい」といった、繰り返す回数や範囲が明確な場合は、もっと安全で便利な for文 を使うのが一般的です。
for文は、リストやタプルのような「コンテナ」から要素を一つずつ順番に取り出して、すべての要素がなくなるまで処理を繰り返します。
# scores というリストを用意
scores = [88, 92, 75, 80, 95]
# scoresリストから、点数を一つずつ s という変数に取り出して処理する
for s in scores:
print(s)このコードは、 scores というリストの中から、最初の 88 を s という変数に入れ、 print(s) を実行します。次に、 92 を s に入れ、 print(s) を実行。これをリストの最後の要素である 95 まで繰り返します。実行結果は、リストの中身が順番に表示されます。
while文のように、カウンター変数の初期化や更新を自分で書く必要がないため、コードがスッキリして、無限ループに陥る心配もありません。非常に安全で読みやすい書き方だと思いませんか?
「でも、決まった回数だけ繰り返したい時はどうするの?」と思ったあなた、鋭いですね!そのために range() という便利な機能が用意されています。
range(5) と書くと、これは [0, 1, 2, 3, 4] という数列と同じようなものを作り出してくれます。
# 0から4まで、5回繰り返す
for i in range(5):
print(i, "回目のこんにちは")
これを実行すると、 0 回目のこんにちは から 4 回目のこんにちは までが順番に表示されます。回数を指定するだけで繰り返し処理が書けるので、非常によく使われるテクニックです。
まとめ:退屈な作業はコンピュータにお任せ!
お疲れ様でした!今回は、プログラミングの強力な機能である「繰り返し」を学びました。
- while文:「条件が真の間」繰り返す。無限ループに注意が必要。
- for文:リストなどの要素を順番に取り出して繰り返す。安全でよく使われる。
- range():for文と組み合わせて「決まった回数」の繰り返しを簡単に実現。
これらの繰り返し処理を使いこなせるようになると、これまで手作業でやっていた多くの退屈な作業を自動化できるようになります。プログラミングの本当の楽しさが、ここから始まると言ってもいいでしょう。
さて、データ整理術(コンテナ)、判断力(条件分岐)、そして忍耐力(繰り返し)と、プログラムに必要な基本的な能力が揃ってきました。しかし、プログラムが長くなってくると、同じようなコードを何度も書く場面が出てきます。
次の章では、そうした処理を一つの「部品」としてまとめて、名前をつけて何度も使い回せるようにする「関数」というテクニックを学びます。プログラムがもっと整理され、見通しが良くなりますよ!お楽しみに!
5. 「関数」でコードを部品化しよう
これまでの章で、あなたはデータを整理し(コンテナ)、状況を判断し(条件分岐)、作業を繰り返す(繰り返し)方法を学びました。これらを組み合わせれば、かなり複雑なプログラムも作れるようになってきたはずです。しかし、プログラムが長くなってくると、新たな問題に直面しませんか?「あれ、この計算処理、さっきも書いたような…」「コードが長すぎて、どこで何をしているのか分かりにくい!」といった問題です。
今回は、そんな悩みを一気に解決する魔法のテクニック、「関数」について学んでいきます。関数をマスターすれば、あなたのコードは驚くほど整理され、再利用しやすくなり、プログラミングの効率が飛躍的に向上しますよ!
同じコードを何度も書くのはもうやめよう!
プログラムを書いていると、同じような処理のまとまりを、あちこちで繰り返し使いたい場面がよく出てきます。例えば、「税抜価格から税込価格を計算する」という処理を考えてみましょう。
# 商品Aの税込価格を計算
price_a = 800
tax_rate = 0.1
total_a = price_a * (1 + tax_rate)
print(total_a)
# 商品Bの税込価格を計算
price_b = 1200
total_b = price_b * (1 + tax_rate)
print(total_b)
このコードでは、税込価格を計算する 価格 * (1 + 税率) というロジックが2回登場しています。今回は2回だけですが、もし100回必要になったら?もし、将来的に税率の計算方法が少し複雑になったら?その100箇所すべてを、間違いなく修正する自信はありますか?
とても大変ですよね。こんな時にこそ「関数」の出番です!
関数とは、一連の処理を一つの「部品」としてまとめて、名前をつけたものです。一度この部品を作ってしまえば、あとはその名前を呼ぶだけで、いつでもどこでも同じ処理を呼び出すことができます。
料理の「レシピ」をイメージすると分かりやすいかもしれません。一度「カレーの作り方」というレシピを完成させてしまえば、あとは「このレシピでカレー作って!」とお願いするだけで、誰でも同じカレーが作れますよね。関数は、まさにプログラムにおけるレシピなのです。
関数の心臓部、「引数」と「戻り値」
では、実際に先ほどの税込価格を計算する関数を作ってみましょう。関数の定義は def というキーワードを使います。
# 税込価格を計算する関数を定義する
def calculate_tax_included_price(price):
tax_rate = 0.1
total = price * (1 + tax_rate)
return total
# 関数を使って計算する
total_a = calculate_tax_included_price(800)
total_b = calculate_tax_included_price(1200)
print(total_a)
print(total_b)
見事にコードがスッキリしましたね! def で始まる部分が関数の「定義」、つまりレシピ本体です。そして、 calculate_tax_included_price(800) のように実際に使うことを「呼び出し」と言います。
ここで、二つの非常に重要な専門用語が登場します。「引数(ひきすう)」と「戻り値(もどりち)」です。
引数(Argument):関数に渡す材料
関数を定義する時、 def calculate_tax_included_price(price): のカッコの中に price という変数がありますね。これは、この関数が仕事をするために外部から受け取る「材料」です。これを仮引数(かりひきすう)と呼びます。
そして、関数を呼び出す時に calculate_tax_included_price(800) のように渡している 800 という具体的な値。これが引数です。
800 という引数が、関数の中では price という仮引数に入り、計算に使われるわけです。これにより、800の計算も1200の計算も、同じ関数を使い回して実行できるのです。引数は、関数を柔軟で再利用可能な部品にするための、鍵となる仕組みです。
戻り値(Return Value):関数からの成果物
関数の中で計算した結果を、関数の呼び出し元に返してあげる必要があります。その役割を果たすのが return です。 return total と書くことで、「total変数の中身を、この関数の成果物として返します!」と宣言しているのです。
呼び出し元の total_a = calculate_tax_included_price(800) というコードは、「calculate_tax_included_price関数を800という材料で動かして、返ってきた成果物をtotal_aという変数にしまいなさい」という意味になります。
この「引数」と「戻り値」のデータの受け渡しがあるおかげで、関数は独立した部品として機能することができるのです。
応用テクニック:一度に複数の値を返す
関数は、実は一度に複数の値を返すこともできます。例えば、ある数値リストを受け取って、その合計値と平均値の両方を計算して返したい、なんて時に便利です。
def calculate_sum_and_average(numbers):
total = sum(numbers) # sum() はリストの合計を計算する組み込み関数
average = total / len(numbers) # len() はリストの要素数を数える組み込み関数
return total, average
scores = [88, 92, 75, 80, 95]
s, a = calculate_sum_and_average(scores)
print("合計点:", s)
print("平均点:", a)
return total, average のように、返したい値をカンマで区切って並べるだけです。簡単でしょう?
呼び出し側では s, a = ... のように、受け取るための変数をカンマで区切って用意します。すると、returnされた値が順番にそれぞれの変数に代入されます。
これは、Pythonが内部で自動的に (total, average) という「タプル」を作って返し、それを受け取り側で分解(アンパック)している、という仕組みになっています。複数の計算結果をスマートに扱えると、コードの幅がさらに広がりますよ。
関数の独立性を壊す危険なワナ
最後に関数を使う上での、とても重要な注意点をお話しします。それは「グローバル変数」の扱いです。
関数の外側で定義された変数をグローバル変数と呼びます。そして、関数の中から、このグローバル変数を読み書きすることができてしまいます。
# グローバル変数
tax_rate = 0.1
def calculate_bad_example(price):
# 関数の外にある tax_rate を直接使ってしまっている!
total = price * (1 + tax_rate)
return total
print(calculate_bad_example(1000))一見、このコードは問題なく動きます。しかし、これは非常に危険な書き方です。なぜなら、この関数の計算結果が、関数の外側にある tax_rate という変数の状態に完全に依存してしまっているからです。
もし、プログラムのどこか別の場所で、誰かがうっかり tax_rate = 0.08 と書き換えてしまったら?この関数の計算結果は、意図せず変わってしまいます。関数が独立した「部品」ではなくなり、外部の環境に左右される、不安定で予測不能な存在になってしまうのです。
良い関数とは、外部とのやり取りを引数と戻り値だけで完結させている、独立性の高い部品です。これを意識して設計することが、バグが少なく、メンテナンスしやすいプログラムを作るための秘訣です!
まとめ:プログラムを「設計」する第一歩
お疲れ様でした!今回は、コードを部品化し、再利用可能にするための強力なツール「関数」を学びました。
- 関数:処理をひとまとめにし、名前をつけた部品。
defで定義する。 - メリット:コードの再利用性が高まり、見通しが良くなり、修正も楽になる。
- 引数:関数に渡す「材料」となるデータ。
- 戻り値:関数が返す「成果物」となるデータ。
returnで指定する。 - 独立性:良い関数は、引数と戻り値だけで外部とやり取りし、グローバル変数に依存しない。
関数を使いこなすことは、単にコードを書くことから、プログラム全体を「設計」することへのステップアップを意味します。
さて、私たちは自作の「処理(動詞)」を作れるようになりました。でも、プログラムの世界には「データ(名詞)」と「処理(動詞)」をひとまとめにした、もっと強力な部品の作り方があります。それが次の章で学ぶ「オブジェクト」です。プログラミングの考え方が、また一段と深まりますよ。どうぞ、お楽しみに!
6. すべては「モノ」-オブジェクト指向
これまであなたは、数値や文字列といった「データ」と、if文やfor文、そして自作の「関数」といった「処理」を別々のものとして学んできましたね。しかし、Pythonの世界の根底には、もっと深遠でパワフルな考え方が流れています。それは、「プログラムに登場するすべてのものは、データと処理をひとまとめにした『モノ(オブジェクト)』である」という考え方です。
今回は、このプログラミングの核心とも言える「オブジェクト」の正体に迫ります。この概念を理解すれば、なぜ今まで何気なく使っていたコードがそのように動くのか、その理由がストンと腑に落ちるはずですよ!
あなたが使ってきた「値」の本当の姿
突然ですが、こんなコードを書いたことはありませんか?
name = "yamazaki"
message = "こんにちは、{}さん".format(name)
print(message)
"こんにちは、{}さん" という文字列の後ろに .format(name) とつけると、 {} の部分が name の中身に置き換わって、「こんにちは、yamazakiさん」と表示されます。便利ですよね。
でも、少し不思議に思いませんか?なぜ文字列の後ろにドット( . )をつけて、まるであたかも「文字列さん、フォーマットお願いします!」と命令するような書き方ができるのでしょう。
その答えこそが、「オブジェクト」です。
Pythonでは、 123 のような数値も、 "hello" のような文字列も、 [1, 2, 3] のようなリストも、単なるデータではありません。それぞれが固有の「データ(値そのもの)」と、そのデータを扱うための専用の「処理(関数)」をセットで内蔵した、一つの独立した「モノ(オブジェクト)」なのです。
文字列オブジェクトは、「"hello"という文字データ」を自分の中に持っているだけでなく、「formatする能力」や「すべてを大文字にする能力(upper)」、「特定の文字を置き換える能力(replace)」といった、たくさんの特殊能力(関数)を一緒に持っています。
この、オブジェクトに内蔵されている専用の関数のことを、特別に「メソッド」と呼びます。 .format() は、文字列オブジェクトだけが持っている便利なメソッドの一つだった、というわけです。
my_name = "sato"
# 文字列オブジェクトが持つ upper メソッドを使う
upper_name = my_name.upper()
print(upper_name) # "SATO" と表示される
このように、 オブジェクト.メソッド() という形で、そのオブジェクトが持つ能力を引き出して使うのが、Pythonプログラミングの基本スタイルなのです。
オブジェクトの「設計図」と「実体」
「なるほど、Pythonの世界はオブジェクトで満ち溢れているのか!」と分かったところで、次の疑問が湧いてきますよね。「じゃあ、そのオブジェクト自体は、一体誰がどうやって作っているの?」と。
オブジェクトは、「クラス」という設計図をもとに作られます。
クラスは、いわば「たい焼きの金型」のようなものです。金型には「あんこを入れる場所」や「尻尾の形」といった情報が定義されていますよね。この金型(クラス)を使って焼き上げた、一つ一つのたい焼き(あんこ入り、クリーム入りなど)が「オブジェクト」、あるいは「インスタンス」と呼ばれる実体です。
実際に、簡単なクラスを設計してみましょう。ここでは「ネコ」クラスを考えてみます。
# 「ネコ」というクラス(設計図)を定義する
class Cat:
# この設計図からオブジェクトが作られる瞬間に呼ばれる特殊なメソッド
def __init__(self, name, color):
# このネコに固有のデータ(属性)を持たせる
self.name = name
self.color = color
# このネコができること(メソッド)を定義する
def meow(self):
print("{}「にゃーん」".format(self.name))
# Catクラス(設計図)から、2匹のネコ(オブジェクト)を作る
cat1 = Cat("タマ", "白")
cat2 = Cat("クロ", "黒")
# それぞれのネコが持つデータ(属性)を見てみる
print(cat1.name) # "タマ"
print(cat2.color) # "黒"
# それぞれのネコに鳴いてもらう(メソッドを呼び出す)
cat1.meow() # タマ「にゃーん」
cat2.meow() # クロ「にゃーん」
少し複雑に見えるかもしれませんが、一つずつ見ていきましょう。
class Cat:で、「Cat」という名前の設計図を作り始めます。__init__は「初期化メソッド」と呼ばれる特殊なメソッドです。Cat("タマ", "白")のようにオブジェクトが作られる瞬間に自動的に呼ばれ、そのオブジェクトが持つべき初期データを設定します。ここでself.name = nameのようにして設定された、オブジェクト固有のデータのことを「属性(アトリビュート)」と呼びます。meowは、このクラスから作られたオブジェクトができる「振る舞い」を定義したメソッドです。cat1 = Cat(...)やcat2 = Cat(...)の部分で、設計図から具体的なオブジェクト(インスタンス)を生成しています。
cat1 と cat2 は、同じCatクラスという設計図から作られましたが、それぞれが name や color という異なる属性(データ)を持つ、独立した別のオブジェクトになっている点が重要です。
知らないとハマる!オブジェクトの同一性という落とし穴
最後に、オブジェクトを扱う上で非常に重要な「同一性」という概念について説明します。これは、多くの初心者がつまずくポイントなので、しっかり理解してくださいね。
次のコードを見てください。 list_a と list_b は、どちらも [1, 2, 3] という同じ中身を持っています。
list_a = [1, 2, 3]
list_b = [1, 2, 3]
# == で比較する(中身が等しいか?)
print(list_a == list_b)
# is で比較する(全く同じモノか?)
print(list_a is list_b)これを実行すると、一つ目の == の結果は True になります。これは、「二つのリストの中身が等しいですか?」という比較で、その通りなのでTrueです。
しかし、二つ目の is の結果は False になります。 is 演算子は、「二つの変数が、メモリ上で全く同じ一つのオブジェクトを指していますか?」という、より厳密な比較を行います。この場合、list_aとlist_bは、中身こそ同じですが、それぞれが別々に作られた二つの異なるリストオブジェクトです。
例えるなら、全く同じデザインのTシャツが2枚あるようなものです。 == は「デザインは同じ?」と聞いているのに対し、 is は「この2枚は、物理的に全く同じ一枚のTシャツ?」と聞いているようなもの。当然、答えはノーですよね。
では、次の場合はどうでしょう?
list_c = [10, 20, 30]
list_d = list_c # list_cをlist_dに代入
# is で比較する
print(list_c is list_d)
# list_dの中身を一つ変えてみる
list_d[0] = 99
# list_cはどうなっている?
print(list_c)これを実行すると、 is の結果は True になります。そして、最後の print(list_c) の結果は、なんと [99, 20, 30] に変わってしまっています!
list_d = list_c というコードは、リストをコピーしているのではありません。「list_cという変数が指しているオブジェクトの住所を、list_dという変数にも教える」という意味になります。結果として、list_cとlist_dは、二人で一つのリストオブジェクトを共有している状態になるのです。だから、list_dを通して中身を変更すると、list_cから見ても中身が変わってしまう、という現象が起きます。
この挙動は、特にリストのような変更可能な(ミュータブルな)オブジェクトを扱う際に、バグの原因となりやすいので、 = と is の違いと合わせて、絶対に覚えておいてください。
まとめ:世界の解像度が上がるオブジェクト指向
お疲れ様でした!今回は、Pythonプログラミングの根幹をなす「オブジェクト」という考え方を学びました。
- オブジェクト:データ(属性)と処理(メソッド)がセットになった「モノ」。Pythonではすべてがオブジェクトである。
- クラス:オブジェクトを作るための「設計図」。
- インスタンス:クラスという設計図から作られた、オブジェクトの「実体」。
- 同一性:
==は値が等しいか、isは全く同一のオブジェクトかを判定する。
オブジェクトという概念を理解すると、Pythonの世界の解像度がグッと上がります。これまでバラバラに見えていたデータと処理が、実は密接に結びついた「モノ」として存在していることが見えてくるはずです。この考え方は「オブジェクト指向プログラミング」と呼ばれ、現代のソフトウェア開発の主流となっています。
さて、自分で部品(クラスやオブジェクト)を設計する方法を学びました。次の章では、Pythonにあらかじめ用意されている便利な部品や、世界中の開発者が作って公開している素晴らしい部品たち(モジュール、ライブラリ)を、どうやって自分のプログラムに組み込んで使うのかを学んでいきます。プログラミングの可能性が、無限に広がりますよ!どうぞお楽しみに!
7. モジュールとライブラリ活用術
6章では、データと処理を一体化させた「オブジェクト」というパワフルな概念を学び、自分でプログラムの「部品」を設計する方法を知りましたね。しかし、プログラミングの醍醐味は、必ずしもすべての部品を自分で一から作ることにあるわけではありません。もし、車輪を再発明する必要がないとしたら?もし、世界中の天才たちが作り上げた超高性能な部品を、あなたのプログラムに自由に組み込めるとしたら?
今回は、そうした先人たちの知恵の結晶である「部品」を自分のプログラムで活用する方法を学んでいきます。この章をマスターすれば、あなたのPythonでできることの範囲は、文字通り無限に広がりますよ!
プログラムの世界の「部品」たち
あなたが何か大きなものを作ろうとするとき、例えば家を建てるところを想像してみてください。まさか、釘の一本一本、窓ガラスの一枚一枚を、砂や鉄鉱石から自分で作ったりはしませんよね。ほとんどの場合、規格化された釘や窓ガラスを建材メーカーから購入してきて、それらを組み合わせて家を建てるはずです。
プログラミングも全く同じです。複雑な計算、ウェブサイトとの通信、データのグラフ化といった一般的な処理は、すでに誰かが最高の品質の「部品」として作り上げてくれています。私たちの仕事は、これらの優れた既製品の部品を見つけ出し、賢く組み合わせて、自分の目的を達成することなのです。
Pythonでは、これらの「部品」はいくつかの種類に分かれています。一番身近なものから順番に見ていきましょう。
意識せずに使っている「組み込み関数」
実は、あなたはすでに最も基本的な部品を使いこなしています。それが「組み込み関数」です。
print() や len()、 type()、 sum() といった、これまで何気なく使ってきたこれらの関数は、Pythonをインストールしたその瞬間から、特に何も準備しなくても使えるようになっています。
これらは、ドライバーやハンマーのように、どんなプログラムを作る上でも必要になるであろう、最も基本的で汎用的な道具(関数)たちです。Pythonが最初から用意してくれている、いわば「標準装備のツールセット」だと考えてください。
専門ツールセット「モジュール」
基本的なツールセットだけでは、専門的な作業はできませんよね。数学の特殊な計算がしたくなったり、ランダムな数字を扱いたくなったりすることもあるでしょう。そんな時に登場するのが「モジュール」です。
モジュールとは、関連する関数やクラス(設計図)を一つのファイルにまとめたものです。Pythonには、こうした専門的なモジュールが最初からたくさん用意されています(これらを標準ライブラリと呼びます)。
ただし、組み込み関数と違って、モジュールは使う前に「これからこの道具箱(モジュール)を使いますよ!」と、プログラムに宣言してあげる必要があります。そのための命令が import です。
例えば、数学的な計算を色々詰め込んだ math モジュールを使ってみましょう。
# mathモジュールをプログラムに読み込む
import math
# mathモジュールの中にある円周率(パイ)というデータを使ってみる
print(math.pi) # 3.141592653589793 と表示される
# mathモジュールの中にあるsqrtという関数(平方根を計算する)を使ってみる
result = math.sqrt(2) # 2の平方根を計算
print(result) # 1.4142135623730951 と表示されるimport math と書くことで、mathという名前の道具箱が使えるようになります。そして、その中の道具を使うには math.pi や math.sqrt() のように、 モジュール名.道具名 という形で指定します。
このように、importは、あなたのプログラムに新たな機能を追加するための魔法の呪文なのです。
巨大な道具箱「パッケージ」
モジュールがたくさん増えてくると、それらを整理整頓したくなりますよね。「これは画像処理用」「これは音声処理用」というように。「パッケージ」は、まさにそのための仕組みです。
パッケージとは、複数のモジュールをディレクトリ(フォルダ)構造でまとめたものです。大きな工具箱の中に、さらに「ネジ類」「釘類」といった小さな引き出し(モジュール)が入っているのをイメージしてください。
これにより、大規模で複雑なライブラリを、系統立てて管理することができるのです。私たちはパッケージの中から、 フォルダ名.ファイル名 のようにして、目的のモジュールをピンポイントで指定して使うことができます。
Pythonの真髄!「外部ライブラリ」
標準ライブラリだけでも非常に多くのことができますが、Pythonの本当の力はここから始まります。それが「外部ライブラリ」(サードパーティライブラリ)の存在です。
外部ライブラリとは、世界中の企業や個人開発者が作成し、インターネット上で公開してくれている、超高性能なモジュールやパッケージ群のことです。データ分析の専門家が作った統計解析ライブラリ、ウェブのプロが作ったネットワーク通信ライブラリ、AI研究者が作った機械学習ライブラリなど、ありとあらゆる分野の最高のツールが揃っています。
これらの外部ライブラリを利用するには、まず自分のコンピュータにそれらをインストールする必要があります。そのための専用ツールが pip (ピップ)です。pipはPythonのパッケージ管理システムで、コマンドプロンプトやターミナルといった黒い画面で、次のように命令を打ち込むことでライブラリをインストールできます。
pip install ライブラリ名
例えば、 requests という、ウェブサイトの情報を取得するのに非常に人気のあるライブラリをインストールするには、次のようにします。
pip install requestsインストールが完了すれば、あとは標準ライブラリのモジュールと同じように import requests と書くだけで、そのライブラリが持つ強力な機能を自分のプログラムで使えるようになります。
pipの名前の由来
「pip」は "Pip Installs Packages" または "Pip Installs Python" の略とされています。Pythonのパッケージ管理ツールで、パッケージのインストールや更新を自動化するために作られました。再帰的なユーモアのある名前ですね。
外部ライブラリの圧倒的なパワー
では、requestsライブラリを使うと、どれほど便利になるのでしょうか?例えば、「GoogleのトップページのHTML(ウェブサイトの設計図)を取得する」というプログラムを書いてみましょう。
requestsを使うと、たったこれだけです。
import requests
# アクセス先のURL (BBC) に指定します
target_url = 'https://www.bbc.com'
print(f"{target_url} にアクセスします...")
try:
# たった1行で、指定したWebサイトの情報を取得!
response = requests.get(target_url)
# 取得が成功したか確認(失敗したらエラーを発生させます)
response.raise_for_status()
# 取得したHTMLの中身を表示(最初の500文字だけ)
print("\n--- 取得したHTML (冒頭) ---")
print(response.text[:500])
print("---")
except requests.exceptions.RequestException as e:
print(f"エラーが発生しました: {e}")
実行すると、あなたのターミナルにGoogleのHTMLソースコードがズラッと表示されるはずです。もしこれを標準ライブラリ( urllib など)だけで書こうとすると、接続の管理、エラーの処理、データのエンコーディング(文字化け対策)など、もっと多くのことを自分で書かなければならず、コードは数倍に膨れ上がります。
requestsは、そうした面倒な処理をすべて裏側で引き受けてくれ、「Webサイトの情報を取る」という本質的な部分を、私たちにたった1行のコード( requests.get(...) )で実行させてくれるのです。
この「車輪の再発明(みんながやっている面倒なことを、自分でもう一度作ること)をしなくてよい」という強力なサポートこそが、外部ライブラリの真髄です。
この外部ライブラリの膨大で豊かな生態系こそが、Pythonがデータ分析からWeb開発、AI研究まで、あらゆる分野で世界中の開発者に愛用される最大の理由の一つなのです。
まとめ:巨人の肩の上に立とう!
お疲れ様でした!今回は、プログラムの部品を活用する方法について学びました。
- 組み込み関数:何も準備しなくても使える、基本的な道具。
- モジュール:専門的な関数群をまとめたファイル。importで読み込んで使う。
- パッケージ:複数のモジュールをフォルダで整理したもの。
- 外部ライブラリ:世界中の開発者が作った高性能な部品。pipでインストールして使う。
「巨人の肩の上に立つ」という言葉があります。これは、先人たちが築き上げた偉大な業績の上に立つことで、私たちはより遠くまで見通すことができる、という意味です。モジュールやライブラリを活用することは、まさにこの言葉をプログラミングで実践することに他なりません。すべてを自分で作ろうとせず、優れた部品を積極的に活用する。それが、優れたプログラマーへの近道です。
「最低限知っておきたいPythonの文法」最後までお読みいただきありがとうございます。
サンプルコードはGoogle Colabにも置いてあります。
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。