
木構造
 山崎講師
山崎講師木構造は、ノードと枝から成るデータ構造の一つです。ノードとは、データを格納する要素であり、枝とは、ノード同士を結ぶ線のことです。
木構造は、一つのノードをルートノードとして、その下に複数の子ノードがあり、子ノードの下に更に子ノードがあるという階層的な構造を持ちます。ただし、親ノードを持たない最上位のノードがルートノードであり、一つのノードに対して、複数の親ノードを持つことはありません。
例えば、以下のような木構造を考えてみましょう。
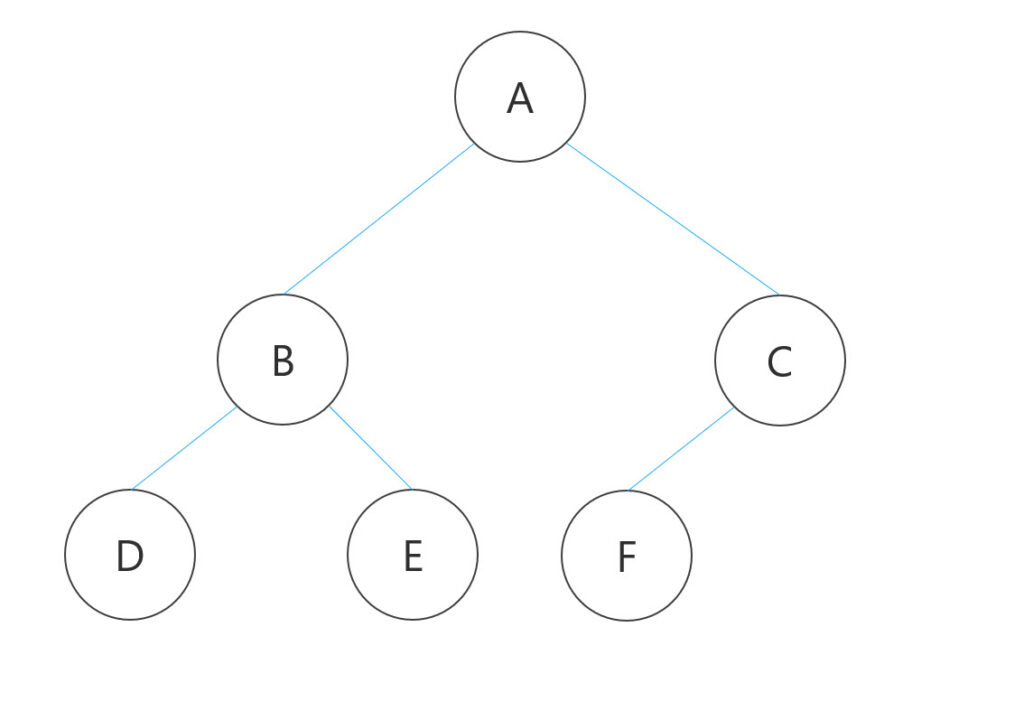
この木構造では、ノードAがルートノードであり、BとCがAの子ノードとなっています。また、Bの子ノードはD、E、であり、CはFという子ノードを1つだけを持っています。なお、D、E、Fはそれぞれ葉ノードと呼ばれます。
木構造は、階層的なデータを表現するために使われることが多く、ファイルシステムのディレクトリ構造や、Webページのドキュメントツリーなどが代表的な例です。また、木構造はグラフ理論においても重要な概念であり、様々なアルゴリズムやデータ構造の基礎となっています。
木の走査【tree traversal】とは、木構造内のすべてのノードを順番に訪問することを指します。木の走査は、木構造内のノードを探索するために非常に重要であり、多くのアルゴリズムやデータ構造において利用されます。
木の走査には、主に以下の2つの方法があります。
深さ優先探索【DFS: Depth-First Search】
深さ優先探索は、子ノードから訪問するノードを優先的に選択する方法であり、再帰的な処理を用いることが一般的です。具体的には、あるノードを訪問した後、そのノードの子ノードを再帰的に訪問していきます。深さ優先探索には、前順走査、中順走査、後順走査の3種類があります。
1.先行順走査【Pre-order traversal】
先行順走査は、根ノードを最初に訪問し、左の子ノードを訪問し、次に右の子ノードを訪問することで、全体を探索する方法です。具体的には、以下のような順番で探索を行います。
1. 根ノードを訪問
2. 左の子ノードを訪問
3. 右の子ノードを訪問
<以下に訪問の順番を書き入れましょう>
2.中間順走査【In-order traversal】
中間順走査は、左の子ノードを最初に訪問し、次に根ノードを訪問し、右の子ノードを訪問することで、全体を探索する方法です。具体的には、以下のような順番で探索を行います。
1. 左の子ノードを訪問
2. 根ノードを訪問
3. 右の子ノードを訪問
<以下に訪問の順番を書き入れましょう>
3.後行順走査【Post-order traversal】
後行順走査は、左の子ノードを最初に訪問し、次に右の子ノードを訪問し、最後に根ノードを訪問することで、全体を探索する方法です。具体的には、以下のような順番で探索を行います。
1. 左の子ノードを訪問
2. 右の子ノードを訪問
3. 根ノードを訪問
<以下に訪問の順番を書き入れましょう>
幅優先探索【BFS: Breadth-First Search】
幅優先探索は、同じ深さにあるノードを優先的に訪問する方法であり、キューというデータ構造を利用して実現されます。具体的には、ルートノードから始まって、同じ深さにあるノードを全て訪問した後、その次の深さのノードを訪問します。
<以下に訪問の順番を書き入れましょう>
木の走査は、コンピュータサイエンスの様々な分野で利用されています。以下にその一部を示します。
- プログラミング言語のコンパイラやインタプリタでは、構文解析に木の走査を利用して、ソースコードの構文解析を行います。
- データベース管理システムでは、データを木構造で表現し、木の走査を利用して、データの検索や更新を行います。
- グラフ理論において、木構造はグラフの一種であり、グラフの探索に木の走査を利用して、グラフアルゴリズムを実現します。
- 人工知能分野において、決定木分類器は、分類を行うために木の走査を利用します。
- コンピュータネットワークにおいて、ルーターやスイッチは、パケット転送に木の走査を利用します。
以上のように、木の走査は様々な分野で利用されています。
<サンプルプログラム>
import java.util.LinkedList;
import java.util.Queue;
class Node {
String val;
Node left;
Node right;
public Node(String val) {
this.val = val;
this.left = null;
this.right = null;
}
}
public class TreeTraversal {
public static void main(String[] args) {
Node root = new Node("A");
root.left = new Node("B");
root.right = new Node("C");
root.left.left = new Node("D");
root.left.right = new Node("E");
root.right.left = new Node("F");
System.out.println("深さ優先探索 (先行順):");
depthFirstTraversalPreorder(root);
System.out.println("\n\n深さ優先探索 (中間順):");
depthFirstTraversalInorder(root);
System.out.println("\n\n深さ優先探索 (後行順):");
depthFirstTraversalPostorder(root);
System.out.println("\n\n幅優先探索:");
breadthFirstTraversal(root);
}
public static void depthFirstTraversalPreorder(Node node) {
if (node == null) {
return;
}
System.out.print(node.val + " ");
depthFirstTraversalPreorder(node.left);
depthFirstTraversalPreorder(node.right);
}
public static void depthFirstTraversalInorder(Node node) {
if (node == null) {
return;
}
depthFirstTraversalInorder(node.left);
System.out.print(node.val + " ");
depthFirstTraversalInorder(node.right);
}
public static void depthFirstTraversalPostorder(Node node) {
if (node == null) {
return;
}
depthFirstTraversalPostorder(node.left);
depthFirstTraversalPostorder(node.right);
System.out.print(node.val + " ");
}
public static void breadthFirstTraversal(Node root) {
if (root == null) {
return;
}
Queue<Node> queue = new LinkedList<>();
queue.add(root);
while (!queue.isEmpty()) {
int levelSize = queue.size();
for (int i = 0; i < levelSize; i++) {
Node node = queue.poll();
System.out.print(node.val + " ");
if (node.left != null) {
queue.add(node.left);
}
if (node.right != null) {
queue.add(node.right);
}
}
}
}
}<出力結果>
| 深さ優先探索 (先行順): A B D E C F 深さ優先探索 (中間順): D B E A F C 深さ優先探索 (後行順): D E B F C A 幅優先探索: A B C D E F |
練習問題
基本情報技術者試験 平成26年春期 午前問6
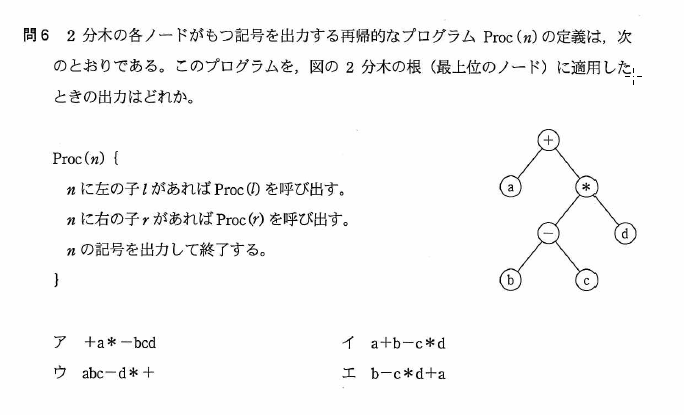
木に関連して基本情報技術者試験で重要なのは二分探索木とヒープです。
二分探索木
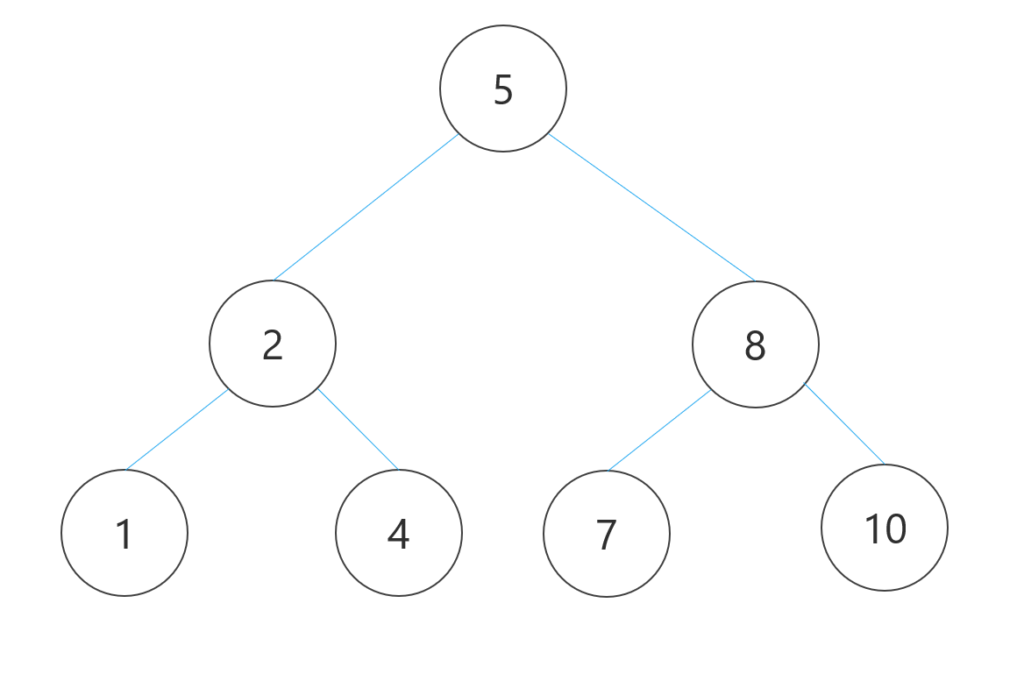
二分探索木【binary search tree】は、二分木の一種で、各ノードが値を持ち、その値はそのノードの左側のサブツリーにあるノードの値よりも小さく、右側のサブツリーにあるノードの値よりも大きいという特徴があります。この特徴により、二分探索木は非常に高速な検索が可能です。
二分探索木は、挿入、削除、検索などの操作に適したデータ構造であり、データベースの索引や、プログラム言語のシンボルテーブルなど、多くのアプリケーションで使用されています。
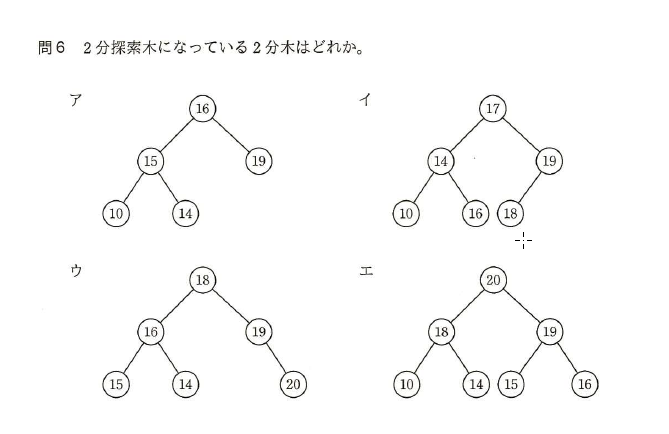
練習問題
基本情報技術者試験 平成28年秋期 午前問6
二分探索木のサンプルプログラムです。
public class BinarySearchTree {
// ノードクラス
private static class Node {
int value;
Node left;
Node right;
Node(int value) {
this.value = value;
}
}
private Node root;
// 要素の挿入
public void insert(int value) {
root = insert(root, value);
}
private Node insert(Node node, int value) {
if (node == null) {
return new Node(value);
}
if (value < node.value) {
node.left = insert(node.left, value);
} else if (value > node.value) {
node.right = insert(node.right, value);
}
return node;
}
// 要素の検索
public boolean contains(int value) {
return contains(root, value);
}
private boolean contains(Node node, int value) {
if (node == null) {
return false;
}
if (value == node.value) {
return true;
} else if (value < node.value) {
return contains(node.left, value);
} else {
return contains(node.right, value);
}
}
// 木のサイズ
public int size() {
return size(root);
}
private int size(Node node) {
if (node == null) {
return 0;
}
return 1 + size(node.left) + size(node.right);
}
public static void main(String[] args) {
BinarySearchTree bst = new BinarySearchTree();
// 要素の挿入
bst.insert(5);
bst.insert(2);
bst.insert(8);
bst.insert(1);
bst.insert(4);
bst.insert(7);
bst.insert(10);
// 要素の検索
System.out.println(bst.contains(7)); // true
System.out.println(bst.contains(3)); // false
// 木のサイズ
System.out.println(bst.size()); // 7
}
}<出力結果>
| true false 7 |
<二分探索木のイメージ>
ヒープ
ヒープとは、データ構造の一種であり、特定の順序に従って並べられた要素の集合を管理するために使用されます。ヒープは、最大値または最小値を迅速に検索することができるため、特に優先度付きキューなどのアルゴリズムで広く使用されています。
一般的に、ヒープは完全二分木として実装されます。ヒープは、通常、次の2つの種類に分類されます。
1.最小ヒープ:最小値が根に位置し、各親ノードの値は、子ノードの値より小さいことが保証されています。
2.最大ヒープ:最大値が根に位置し、各親ノードの値は、子ノードの値より大きいことが保証されています。
ヒープは、要素の挿入、削除、検索などの操作を効率的に実行することができます。具体的には、要素の挿入と削除はO(log n)の時間で実行することができ、最大値または最小値の検索はO(1)で実行することができます。
<ヒープのサンプルプログラム(最大ヒープ)>
public class MaxHeap {
private int[] heap;
private int size;
private int maxSize;
private static final int FRONT = 1;
public MaxHeap(int maxSize) {
this.maxSize = maxSize;
this.size = 0;
heap = new int[this.maxSize + 1];
heap[0] = Integer.MAX_VALUE;
}
private int parent(int pos) {
return pos / 2;
}
private int leftChild(int pos) {
return (2 * pos);
}
private int rightChild(int pos) {
return (2 * pos) + 1;
}
private boolean isLeaf(int pos) {
return pos >= (size / 2) && pos <= size;
}
private void swap(int fpos, int spos) {
int tmp;
tmp = heap[fpos];
heap[fpos] = heap[spos];
heap[spos] = tmp;
}
private void maxHeapify(int pos) {
if (isLeaf(pos))
return;
if (heap[pos] < heap[leftChild(pos)] || heap[pos] < heap[rightChild(pos)]) {
if (heap[leftChild(pos)] > heap[rightChild(pos)]) {
swap(pos, leftChild(pos));
maxHeapify(leftChild(pos));
} else {
swap(pos, rightChild(pos));
maxHeapify(rightChild(pos));
}
}
}
public void insert(int element) {
if (size >= maxSize) {
return;
}
heap[++size] = element;
int current = size;
while (heap[current] > heap[parent(current)]) {
swap(current, parent(current));
current = parent(current);
}
}
public void print() {
for (int i = 1; i <= size / 2; i++) {
System.out.print(
" PARENT : " + heap[i] + " LEFT CHILD : " + heap[2 * i] + " RIGHT CHILD :" + heap[2 * i + 1]);
System.out.println();
}
}
public int remove() {
int popped = heap[FRONT];
heap[FRONT] = heap[size--];
maxHeapify(FRONT);
return popped;
}
public static void main(String[] args) {
MaxHeap maxHeap = new MaxHeap(10);
maxHeap.insert(5);
maxHeap.insert(17);
maxHeap.insert(10);
maxHeap.insert(84);
maxHeap.insert(19);
maxHeap.insert(6);
maxHeap.insert(22);
System.out.println("The Max Heap is ");
maxHeap.print();
System.out.println("The Max val is " + maxHeap.remove());
}
}<出力結果>
| The Max Heap is PARENT : 84 LEFT CHILD : 19 RIGHT CHILD :22 PARENT : 19 LEFT CHILD : 5 RIGHT CHILD :17 PARENT : 22 LEFT CHILD : 6 RIGHT CHILD :10 The Max val is 84 |
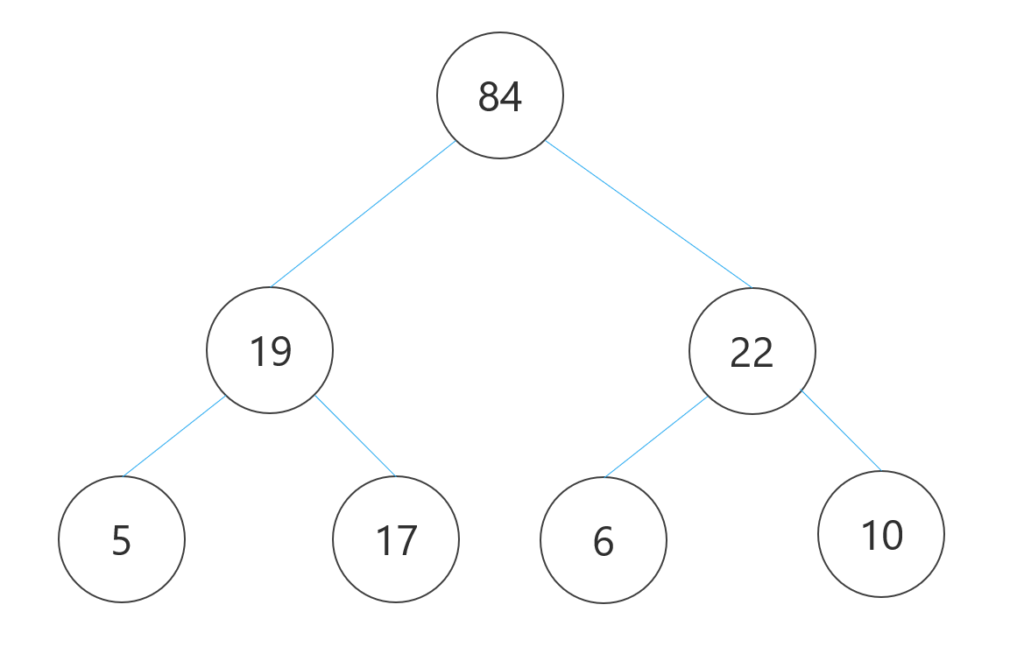
<ヒープのイメージ>
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。

