
前回はMySQLWorkbenchの使い方を解説しました。
今回は、MySQL Workbenchを使ってスキーマとテーブルを作成する手順を解説します。
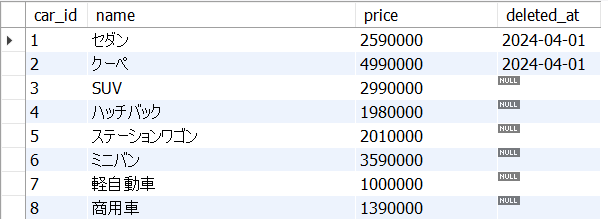
1. テーブルの完成イメージ
下図のようなテーブルを作成し、データを投入し、さらにはデータを更新したり削除したりしてみましょう。
なお、MySQLではテーブル名やフィールド名に日本語を使うことも可能です。しかし、一般的ではないため当社の新人エンジニア研修でも英語表記で進めていきます。
また、この研修のルールとしてテーブル名、フィールド名はスネークケース(例.car_id)を使用します。
2. スキーマの作成
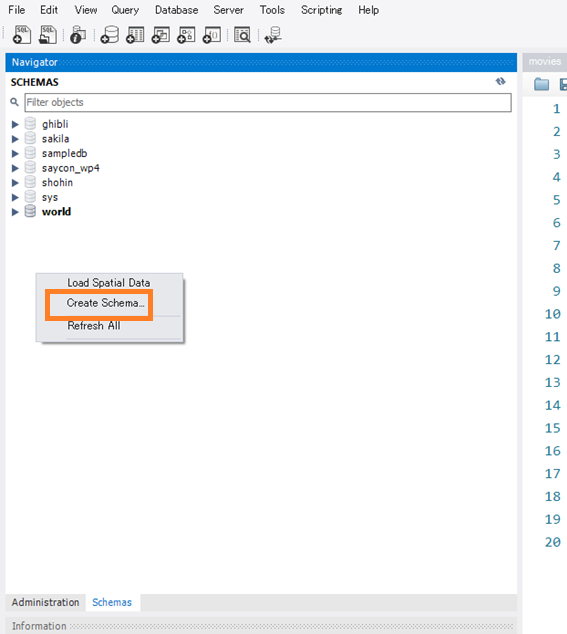
MySQL Workbenchを起動し、操作したいConnectionに接続します。下図の「Schemas」で右クリックして「Create Schema」を選択します。
下図でスキーマ名を入力して「Apply」ボタンを押下します。
なお、Charsetは文字コード、Collationは照合順序のことです。照合順序はレコードの検索や並べ替えをする際に関係してきます。
MySQL8.0からDefaultで「utf8mb4_0900_ai_ci」となっており、日本語対応のWebアプリケーションを作る際に都合が良いのでこのままにします。
utf8mb4が文字コードです。utf8mb4では、日本語のようなマルチバイト文字を最大4バイトで扱います。(通常マルチバイト文字は3バイト)
aiはAccent Insensitiveの略です。アクセントの違いを無視しますのでひらがなカタカナの「か」と「が」は同じ文字として評価されます。
ciはCase Insensitiveの略です。大文字と小文字の違いを無視しますので「a」と「A」は等しいと評価されます。
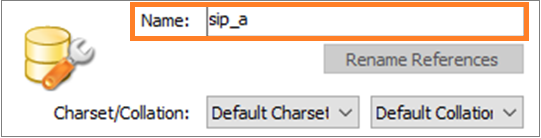
スキーマ名やテーブル名は一般的に小文字で統一することが推奨されます。この研修でも小文字に統一します。
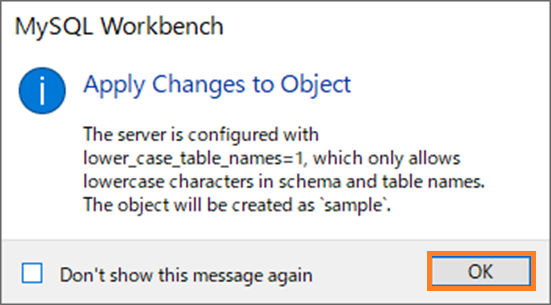
下図のようなダイアログが出たら「OK」ボタンを押下することで自動的に小文字になります。
下図の発行されるSQL文を確認して「Apply」ボタンを押下します。このとき、観察眼に優れた方は`sip_a`のようにスキーマ名が`(バッククォート)で囲まれていることに気づいたかもしれません。
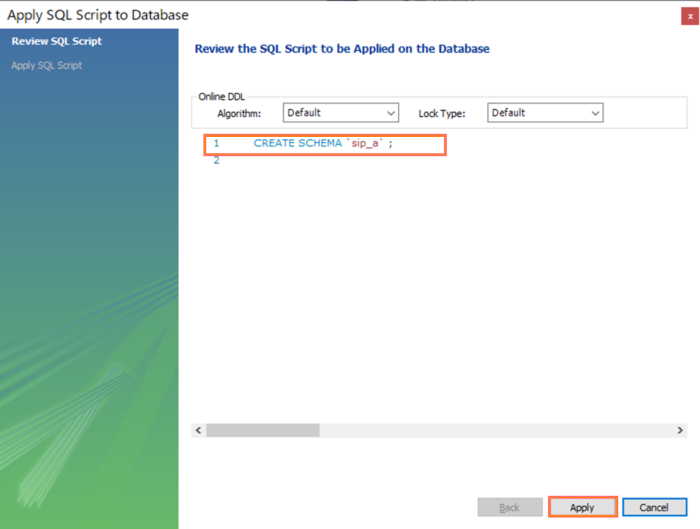
これは何のためにつけているかというとMySQLの予約語をエスケープするためです。Javaにも予約語がありましたね。例えば、「int int = 0」のように予約語を変数名などに使うことができませんでした。
MySQLにも予約語があります。下図で赤の波線が示すように予約語はそのままではスキーマ名、テーブル名、フィールド名に指定できないのです。しかし、エスケープすることで指定が可能になるのです。
バッククォートでエスケープされていたのは、念のためスキーマ名に予約語が使われても大丈夫なようにというworkbenchの親切機能なのでした。なお、予約語はWorkbenchで青字になります。

3. テーブルの作成
下図のようなcarsテーブルを作成します。この研修のルールとしてテーブル名には名詞の複数形(例えばcars)を使用することにします。複数形にする理由は同じもの(例えばcar)の集合であるということが明確に表現できるうえに、SQL文の中にあってすぐにテーブルだと識別できるからです。
3.1. テーブルの作成手順
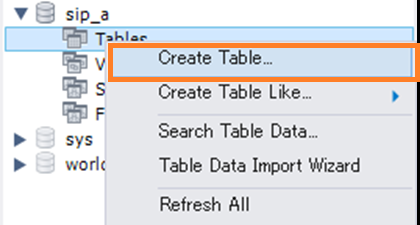
[Create Table…]メニューを選択します
下図のようにテーブルを作成したい「Schemas」の下の「Tables」を右クリックしてポップアップメニューを表示し[Create Table…]メニューを選択します。
テーブル名を入力します。
下図の「new_tableダイアログボックス」が表示されます。テーブル名やCollation、データベースエンジンを選択します。当社の新人研修では、テーブル名のみ入力し、ここでもCharset/Collationはデフォルトのままで結構です。Table Name:の欄に今回は「cars」と入力してください。また、Default/Expression には NULL と大文字で入力します。'NULL' のようにクォーテーションで囲むと文字列になるため注意してください。また、NULLは大文字のNULLを入れてください。(小文字のnullでは文字列の'null'になるのでダメ)

Column NameとDatatypeを設定します
Columnは列(フィールド)、Datatypeはデータ型のことです。
car_idとpriceはINT型としました。
nameはVARCHAR型で100文字としました。
VARCHAR とは【variable character】の略で可変長の文字列という意味です。100は純粋に文字数です。(本来、半角英数字と日本語ではバイト数が異なりますが、UTF-8で設定しているのでその点を考慮しなくてよいのは楽ですね)
可変長ですから固定長と違い、短い文字列の場合も空白がデータ容量を使用しません。できるだけ最小の文字数で設計すれば最小のバイト数になり、無駄なスペースを取らないため、効率的にデータを管理できます。
他方で、設定した文字数を超えて文字列を入れるとエラーになります。そのため、必要十分かつ最小の文字数になるように設計しなければなりません。また、同じデータベースでフィールドごとに文字数がバラバラですと毎回確認が必要になりますから、一律の長さにすることもあります。
deleted_atはレコードの削除日時でDATETIME型にしました。論理削除用のフィールドです。MySQLのDATETIME型は、日付と時刻を「YYYY-MM-DD HH:MM:SS」形式で保存する型です。範囲は1000年から9999年まで、作成日時や更新日時の記録に広く使われます。
なお、テーブル名やフィールド名はこの研修ではスネークケースを使用することにしたということは前述の通りです。
3.2. MySQLのデータ型
この後の最終課題でよく使うであろうMySQLのデータ型をまとめておきます。まずは、下表3. 1の3つの型をしっかり押さえてください。また、このあとWebアプリケーションを作成する際にJavaのデータ型を決めるときのために「Javaのデータ型との対応」を確認しておいてください。迷ったらひとまず(極論ですが)Javaの型は全てStringにするという手もありえます。
例えば、MySQLのINT型のフィールドに文字列の"1"をINSERTすることができます。それでもデータを取り出したときには数値の1として取り出されます。なぜなら、そのフィールドはINT型と型指定されているためMySQLが自動で文字列を整数に変換してくれるのです。
※ただし、データ型をDATETIMEにしておけば日付の加算・減算をすることもできますが、文字列型の場合はそのままでは実現できません。(参考記事:JavaのLocalDateTime型をMySQLのDATETIME型で扱う)
| データ型 | 意味 | 備考 | Javaのデータ型との対応 |
| INT(m) | 整数型 | mは桁数 値の範囲(4バイト):-2147483648~2147483647 ただし、UNSIGNEDの場合の値の範囲:0~4294967295 | int, java.lang.String |
| VARCHAR(m) | 可変長文字型 | mは文字数(最大文字数は文字セットによって変わりますが、最大バイト数は65,535バイト) | java.lang.String |
| DATETIME | 日付時刻型 | 基本のフォーマットは 'YYYY-MM-DD HH:MM:SS' | java.time.LocalDateTime, java.lang.String |
3.3. テーブル列の設定
列を定義します。以下図のように設定してください。
それぞれの項目の意味は以下のとおりです。
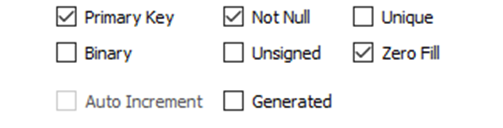
PK: Primary Key = 主キー
NN: Not Null = Nullを許容しない
UN:Unsigned = マイナス符号なし
AI: Auto Increment = 自動で採番する
Default/Expression = デフォルト表現としてデータ入力がない場合の値
それぞれの意味はWorkbenchの右下の下図の部分でも確認することができます。
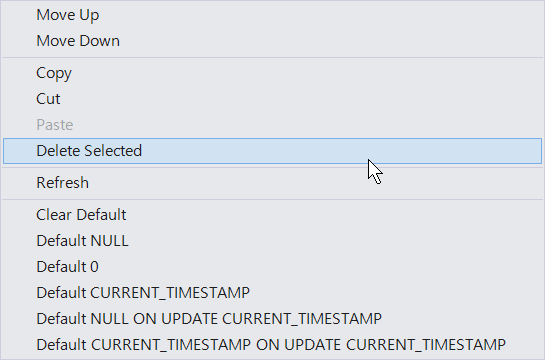
なお、カラムを右クリックすると以下のメニューが表示されますので、ここからDefaultの値を選択することも可能です。
3.4. インデックスの設定
インデックスが必要な場合は、[Indexes]タブからインデックスを定義するフィールドを選択します。今回は確認にとどめインデックスを設定しません。なお、主キーには自動的にインデックスが張られています。
下図の[Apply]ボタンを押します。
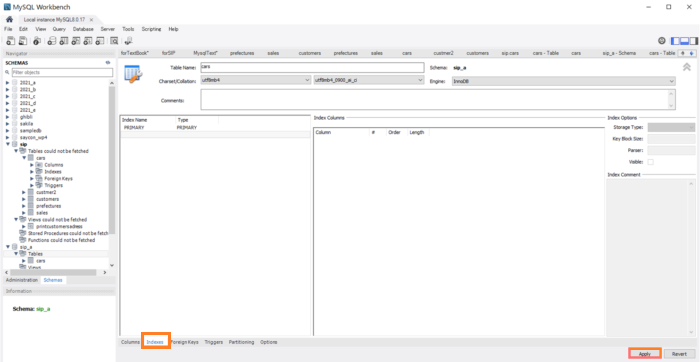
下図のように実行するSQL文が表示されます。内容を確認し問題がなければ[Apply]ボタンをクリックします。
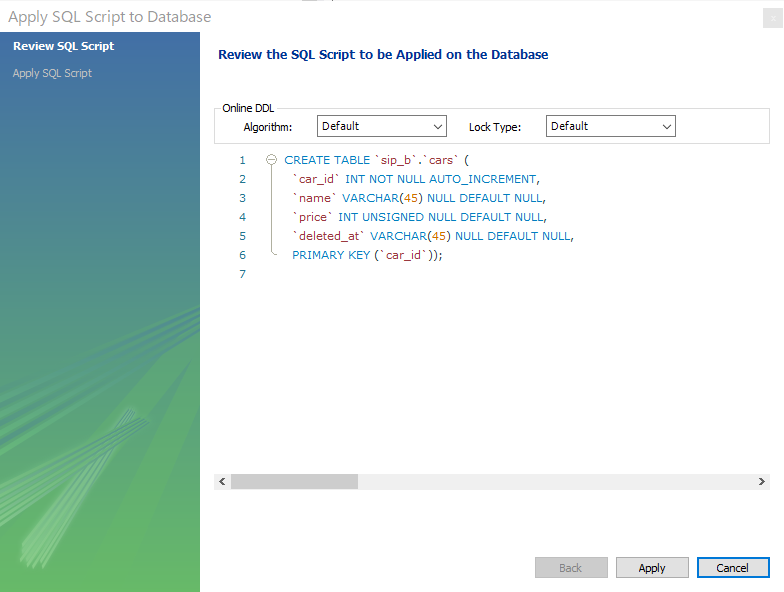
以下3_1sqlが実行されます。
<CREATE TABLE 文>
CREATE TABLE `sip_a`.`cars` (
`car_id` INT NOT NULL AUTO_INCREMENT,
`name` VARCHAR(45) NULL DEFAULT NULL,
`price` INT UNSIGNED NULL DEFAULT NULL,
`deleted_at` VARCHAR(45) NULL DEFAULT NULL,
PRIMARY KEY (`car_id`));なお、SQL文は単語の途中でなければ改行や空白を入れて見やすくすることができます。また、文末のセミコロン( ; )はJavaとは異なり必須ではないのですが、一つのファイルに複数のSQL文を記述する際には区切りとして必要になります。忘れずに付けるようにしましょう。
これでテーブルが作成されました。しかし、スキーマツリーには表示されていません。下図のスキーマツリーを右クリックして「Refresh All」を選択することで表示されます。
4. テーブルに1件のレコードを挿入する
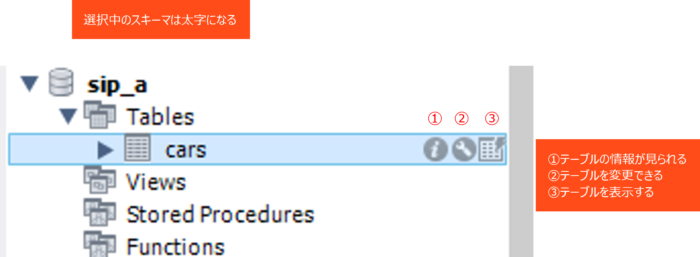
では、先に作成したcarsテーブルに1件のレコードを登録してみましょう。これまでの操作でテーブルが表示されていればそのままで結構です。表示されていない場合は下図のcarsテーブルの「③テーブルを表示するアイコン」をクリックします。
下図のような空のテーブルが表示されました。

4.1. データの入力
テーブルに直接データを入力する
テーブル内をダブルクリックして編集状態にするとエクセルのように直接データを入力できます。下表3.2のようなレコードを1件挿入してみます。
| フィールド名 | 値 | 備考 |
| car_id | (空欄) | オートインクリメントで自動採番されるので何も入力しない |
| name | 'セダン' | 車の名前 |
| price | 2590000 | 車の価格 |
| deleted_at | '2024-04-01' | レコードが削除された日(販売終了日) |
以下の3_2.sqlを実行すると空のテーブルが右下のサーバー応答エリアに表示されます。
SELECT * FROM sip_a.cars;なお、スキーマ名を意味する「sip_a.」の部分はスキーマが選択された状態であれば省略することも可能です。ご自身で確かめてください。
サーバー応答エリアでテーブルのデータを下図のように直接入力します。

編集が完了しましたら、「Apply」ボタンをクリックします。
編集内容をテーブルに反映させる以下のようなINSERT文が表示されます。このSQL文は後で解説するのでご記憶ください。図のApplyをクリックし、次の画面でFinishをクリックします。
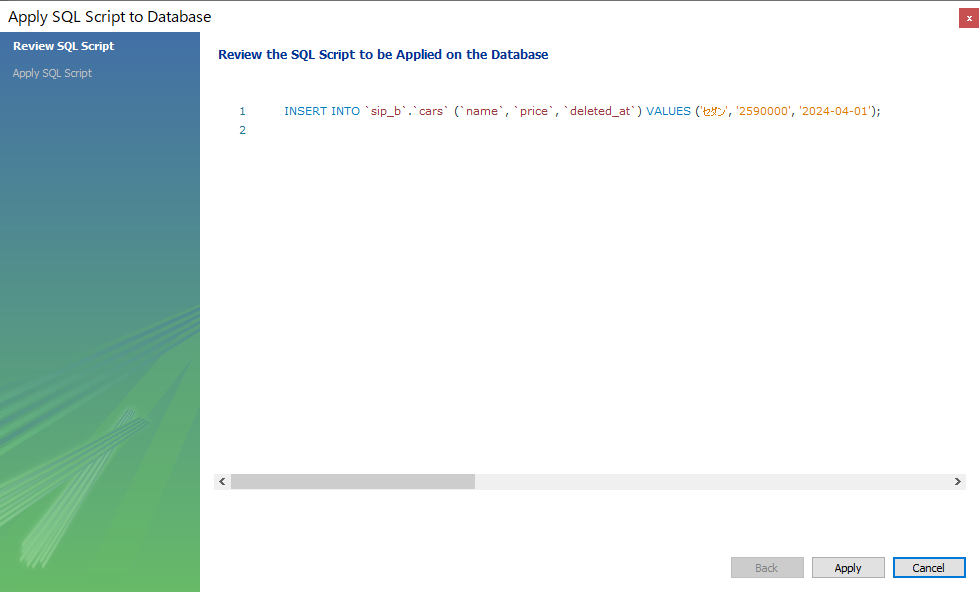
入力されたことを確認してください。
このようにGUIで操作ができることも、その背後ではSQLが働いていることを意識することは重要です。
5. 行の挿入
[書式]
INSERT INTO テーブル名 (カラム1, カラム2, …)
VALUES (値1, 値2, …);
レコードを挿入するINSERT文を確認してみます。以下の3_3.sqlを見てください。
INSERT INTO `sip_a`.`cars` (`name`, `price`, `deleted_at`)
VALUES ('セダン', '2590000', '2024-04-01');なお、テーブルに含まれるすべてのフィールドに値を指定してデータを追加する場合は、以下3_4.sqlのようにフィールド名の指定を省略できます。この場合、オートインクリメントの指定があるcar_idはNULLを指定します。
INSERT INTO `cars` VALUES (NULL, 'セダン', '2590000', '2024-04-01');また、フィールド名を指定することで特定の値のみ挿入して、それ以外の項目はデフォルト値とする以下3_5.sqlのような記述も可能です。
INSERT INTO sip_a.cars (name, price) VALUES ('セダン', '2590000');数値リテラルは シングルクォートで囲わなくて大丈夫です。上記の例では、「 '2590000' 」を「2590000」と書いても同じ結果になります。数値を文字列として入力しているという意味では上記の入力は間違っているのですが、MySQLはエラーにしません。なぜなら、先に見たようにフィールドにはデータ型が指定されているからです。MySQLは変換可能な入力であれば文字列を数値として扱ってくれるのです。
一方、文字列や日時データはシングルクォート(')またはダブルクオート (") で囲みます。一般的にはシングルクォートで囲むことが多いです。上記の例では、「 'セダン' 」や「 '2024-04-01' 」がその例です。Javaの文字列はダブルクオートでしか囲めなかったことと混同しないようにしましょう。
Auto Increment設定のあるフィールド(car_id)はNULLのままで構わないのでしたね。したがって上記のSQL文は以下3_6.sqlのようにcar_idには未定義を意味するnullを指定しても同じことになります。
【car_idにnullを指定した場合のINSERT文】
INSERT INTO sip_a.cars (car_id, name, price) VALUES (null, 'セダン', '2590000');このとき、未定義を意味するNULLはシングルクォートで囲んではいけません。もしも、'null'としてしまうと「nullという文字列」という意味になってしまいます。
このあたりのnullの挙動はWebアプリケーションで重要になるのですが、おそらくその頃には忘れていると思いますので、またここに戻ってきて確認してください。
6. 行の更新
テーブルの内容を直接書き換えることでレコードの更新ができます。
[書式]
UPDATE テーブル名
SET カラム名1 = 値1, カラム名2 = 値2
WHERE 条件;
このときのSQL文は以下の3_9.sqlの通りです。(deleted_atを'2024-05-01'へ変更した場合)
UPDATE `sip_a`.`cars` SET `deleted_at` = '2024-05-01' WHERE (`car_id` = '1');このSQL文の意味は、
sip_a.cars の「car_id = '1' のレコードのフィールドdeleted_at を '2024-05-01 00:00:00'」に更新しなさい。という意味です。(時間は省略することも可能)
7. 行の削除
行を削除するには、下図のように対象行を右クリックして「Delete Row(s)」を選択します。
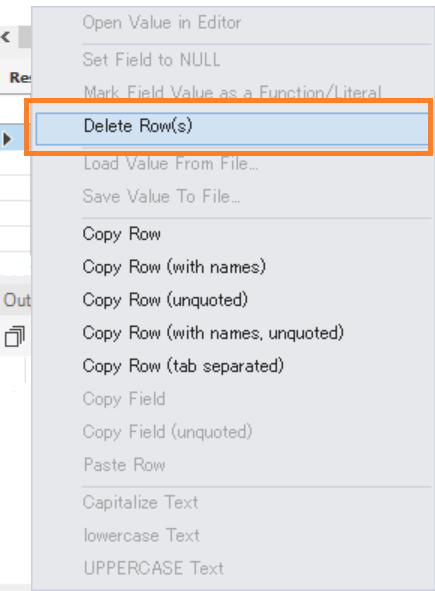
ただし、データベースの役割は事実を記録することです。もし、上記の方法でレコードを削除してしまうと事実が失われてしまいます。したがって、レコードの削除は、極めて限定的な場面でしか使いません。限定的な場面とは、間違ったデータを削除するとか個人情報保護の対応など、削除が必要な場面でのみ使用します。
レコードを削除する代わりに今回のcarsテーブルのようにdeleted_at(販売終了日)のフィールドを用意するというのはよく使われる方法です。このフィールドがNULLではなく値が入っているときにすでに販売が終了されていると見なすわけです。
あるいは、テーブルにBoolean型の削除フラグというフィールドをつくり、そのTRUE/FALSEで削除をされたかどうかを判定する方法もあります。削除フラグにはデフォルトでFALSEにしておき、レコードを削除したら削除フラグをTRUEにするという運用です。
delete文で削除することを物理削除、実際には削除しないことを論理削除とも言います。
8.複数レコードの一括挿入
手入力することが困難な量のデータをテーブルに入力する方法を解説します。例えば、下図のように1件しかないテストデータを増やす方法です。
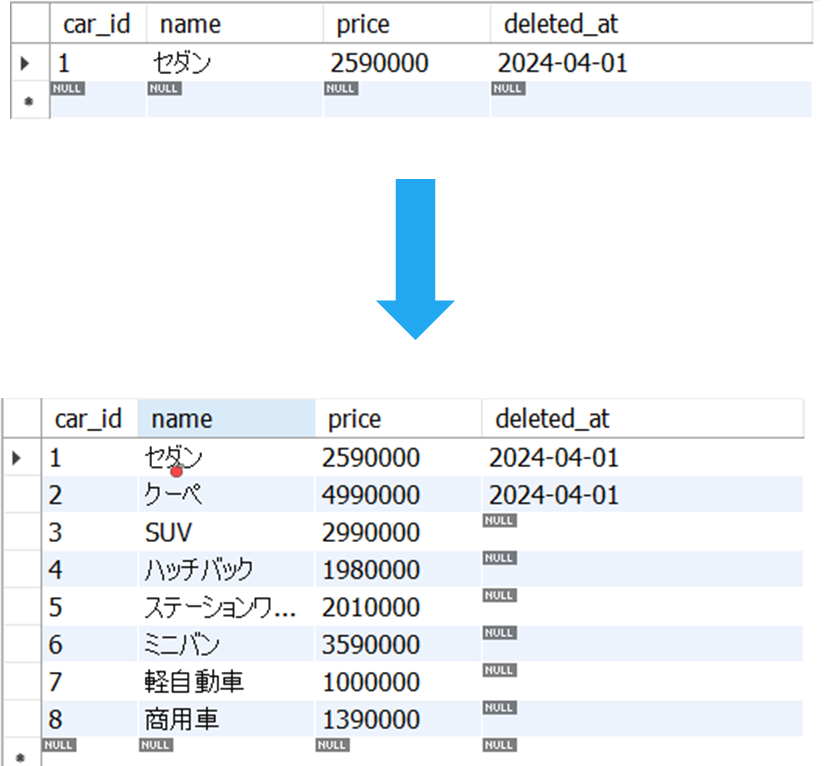
SQLのinsert文を使う方法
必要なSQLのinsert文の確認
今回記述したいSQL文は3_10.sqlのとおりです。全体が一文になっているのがお分かりになるでしょうか?
この書き方はバルクインサート【bulk insert】という方法です。データが増えても速度が速いという特徴があります。あとの3_11.sqlと比較してみてください。英語でも一括注文を【bulk order】といったりしますね。
INSERT INTO `sip_a`.`cars` (`name`, `price`, `deleted_at`)
VALUES
('セダン', '2590000', '2024-04-01'),
('クーペ', '4990000', '2024-04-01'),
('SUV', '2990000', NULL),
('ハッチバック', '1980000', NULL),
('ステーションワゴン', '2010000', NULL),
('ミニバン', '3590000', NULL),
('軽自動車', '1000000', NULL),
('商用車', '1390000', NULL);上記バルクインサートは、以下3_11.sqlの通常のinsert文と比較すると速度が速くなります。
INSERT INTO `sip_a`.`cars` (`name`, `price`, `deleted_at`)
VALUES ('セダン', '2590000', '2024-04-01');
INSERT INTO `sip_a`.`cars` (`name`, `price`, `deleted_at`)
VALUES ('クーペ', '4990000', '2024-04-01');
INSERT INTO `sip_a`.`cars` (`name`, `price`) VALUES ('SUV', '2990000');
INSERT INTO `sip_a`.`cars` (`name`, `price`) VALUES ('ハッチバック', '1980000');
INSERT INTO `sip_a`.`cars` (`name`, `price`) VALUES ('ステーションワゴン', '2010000');
INSERT INTO `sip_a`.`cars` (`name`, `price`) VALUES ('ミニバン', '3590000');
INSERT INTO `sip_a`.`cars` (`name`, `price`) VALUES ('軽自動車', '1000000');
INSERT INTO `sip_a`.`cars` (`name`, `price`) VALUES ('商用車', '1390000');9. データベースのエクスポートとインポート
データベースのエクスポートは、データを外部ファイルとして保存したいときに使います。この研修での主な用途は、バックアップの作成、別のPCへの移行などです。作業前にエクスポートしておくことで、誤操作やトラブルが起きても元の状態に戻しやすくなります。
1. データベースのエクスポート
MySQL Workbenchを起動し、接続しているデータベースに移動します。
メニューバーの「Server」をクリックし、「Data Export」を選択すると「Export Options」ダイアログボックスが表示されます。以下の手順で設定を行います。
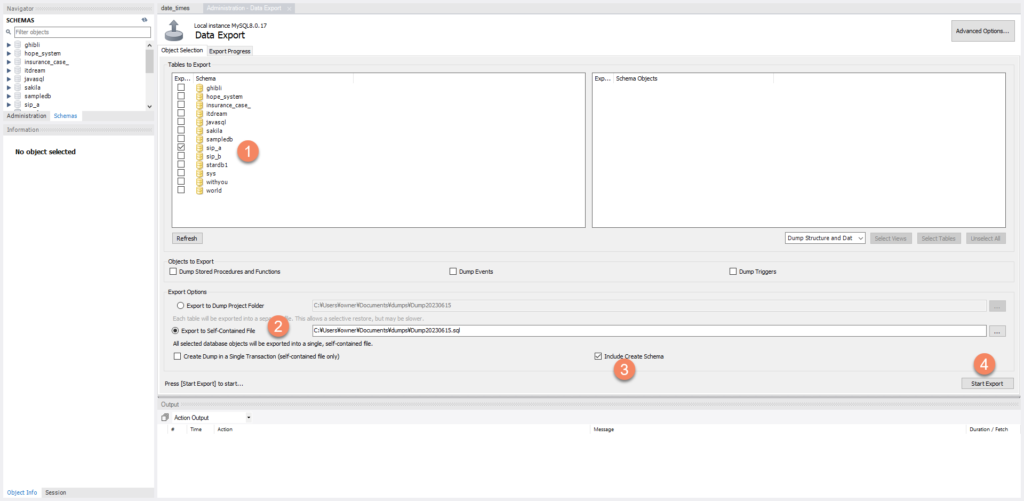
- 「Tables to Export」でエクスポートしたいスキーマにチェックを入れます。( ストアドプロシージャも含めたい場合は「Dump Stored Procedures and Functions」にチェックを入れます)
- 「Export to Self-Contained File」オプションを選択し、保存するファイルの場所と名前を指定します。保存するファイルの場所はデスクトップ、名前は今日の日付などの分かりやすい名前で.sqlファイルを作成すると良いでしょう。(例:0501.sql)
- 「Include Create Schema」オプションを選択すると、テーブルのスキーマ(構造)がエクスポートされます。このオプションを選択しない場合、インポート先のデータベースを事前に作成する必要があります。自動でスキーマを作成したい場合やデータベース構造を再現したい場合は、このオプションを選択する必要があります。
- 上記の設定を行ったら、「Start Export」ボタンをクリックします。エクスポートが開始され、指定した場所に.sqlファイルが保存されます。
なお、このとき保存された拡張子がsqlのファイルはダンプファイルと呼ばれる形式です。その中身は以下のようなSQL文です。(英語の【dump】にはダンプカーの語源である「どさっと降ろす」という意味があります)

②のところで、「Export to Dump Project Folder」を選択することもできます。この2つのオプションの違いは以下の通りです。
- Export to Dump Project Folderは、データベースを個別のファイルに分割してエクスポートします。細かく管理したい場合や部分的なインポートが必要な場合に適しています。
- Export to Self-contained Fileは、すべてのデータベース内容を1つのファイルにまとめてエクスポートします。簡単にバックアップやリストアを行いたい場合に適しています。
2. データベースのインポート
MySQL Workbenchを起動し、接続しているデータベースに移動します。
メニューバーの「Server」をクリックし、「Data Import」を選択すると「Import Options」ダイアログボックスが表示されます。以下の手順で設定を行います。

- 「Import from Self-Contained File」オプションを選択し、インポートする.sqlファイルを選択します。この選択肢はエクスポートの際の「Export to Self-Contained File」オプションに対応しています。
- 「Default Target Schema」でインポート先のスキーマ(データベース)を選択します。ドロップダウンメニューから、インポートしたデータをどのスキーマにインポートするかを選択します。もしインポートしたいスキーマが存在しない場合は、「New...」のボタンから新しいスキーマを作成することもできます。
- 上記の設定を行ったら、「Start Import」ボタンをクリックします。インポートが開始され、データベースにデータがインポートされます。
10. テーブルの削除と変更
当社の新人エンジニア研修では、作ったテーブルを変更することは良くあります。また、データを空にしたり、テーブルそのものを削除することもあります。ここでその方法を見ていきましょう。
下図のようにテーブルを右クリックしてコンテキストメニューを表示します。
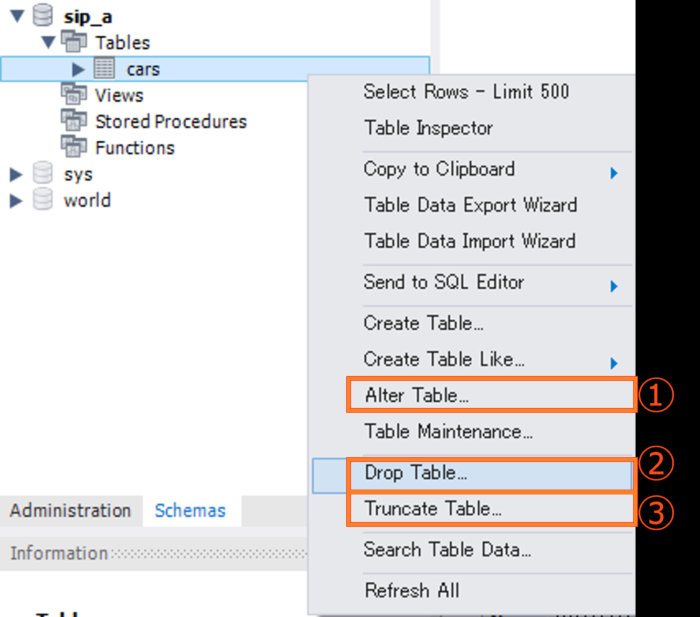
①のAlter Table...を選択するとテーブルの変更画面に移ります。
あとは、テーブルを変更してapplyボタンを押せば変更が反映されます。
②テーブルをスキーマごと削除してしまいたいときはDrop Table...を選びます。
以下3_10.sqlのようなSQL文が発行され、テーブルが削除されます。
DROP TABLE sip_a.cars;③テーブルの構造(スキーマ)を残して全てのレコードを削除したいときはTruncate Table...を選びます。
以下3_11.sqlのようなSQL文が発行され、全てのレコードが削除されます。
TRUNCATE sip_a.cars;なお、TRUNCATE TABLE 文を使用するとデータの削除だけではなく AUTO_INCREMENT もリセットされることを覚えておくと良いでしょう。
その他の便利なコンテキストメニュー
コンテキストメニューを紹介したのでその他の便利な機能を紹介します。当社の新人エンジニア研修ではこの後、さまざまなSQL文を学んでいきます。その際に確実にキーボードからコマンドを打てるようになることが最も望ましいのですが、限られた研修期間中には難しいものです。そこで、コンテキストメニューを使ってSQL文の雛形を書く方法をお伝えします。具体的なSQL文の意味は次回以降に回して、まずはどのような機能があるのかだけを見ていきます。
下図のようにテーブル名を右クリックして、「Send to SQL Editor」を選びSQLエディターにSQL文を送ることができます。
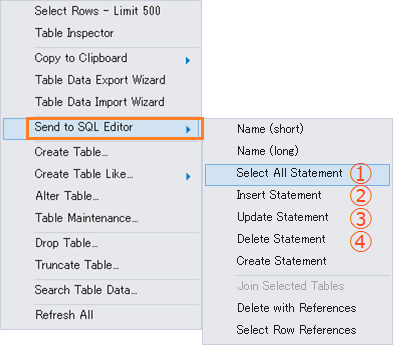
①以下3_12.sqlは全てのレコードを選択するSELECT文です。
SELECT `cars`.`car_id`,
`cars`.`name`,
`cars`.`price`,
`cars`.`deleted_at`
FROM `sip_a`.`cars`;②以下3_13.sqlは1件のレコードを挿入するINSERT文です。以下の<{name: }>のところを具体的な値(例えば「セダン」)などに書き換えて使ってください。
INSERT INTO `sip_a`.`cars`
(`car_id`,
`name`,
`price`,
`deleted_at`)
VALUES
(<{car_id: }>,
<{name: }>,
<{price: }>,
<{deleted_at: }>);
SELECT * FROM sip_a.cars;③以下3_14.sqlはレコードを更新するUPDATE文です。
UPDATE `sip_a`.`cars`
SET
`car_id` = <{car_id: }>,
`name` = <{name: }>,
`price` = <{price: }>,
`deleted_at` = <{deleted_at: }>
WHERE `car_id` = <{expr}>;④以下3_15.sqlは特定の条件のレコードを削除するDELETE文です。
DELETE FROM `sip_a`.`cars`
WHERE <{where_expression}>;
このようにひな形を書き換えることで、SQL文を暗記しなくても使うことはできます。ただし、繰り返しになりますが、暗記してあればそれだけ早く、確実に、確信を持って使うことができます。
参考:本研修で使用するSQLの記号一覧
| 記号 | 読み方 | 主な用途 |
|---|---|---|
* | アスタリスク(口頭ではスターと呼ぶこともある) | すべての列を指定 |
= | イコール | 値の一致を比較 |
<>, != | ノットイコール | 値が等しくないかの比較 |
<, >, <=, >= | 小なり・大なり | 数値の大小比較 |
, | カンマ | 複数項目の区切り |
' | シングルクオート | 文字列リテラル |
" | ダブルクオート | 識別子(※MySQLでは非推奨の場合あり) |
` | バッククォート | テーブル名・列名の囲い(予約語対策) |
() | 丸かっこ | 関数・サブクエリ・IN句など |
% | パーセント | ワイルドカード(LIKE句) |
_ | アンダースコア | 任意の1文字(LIKE句) |
; | セミコロン | SQL文の終了 |
-- | ダッシュ2つ | コメント(1行) |
/* */ | スラッシュ・アスタリスク | コメント(複数行) |
. | ドット | テーブルとカラムの区切り |
以上、今回は、新人エンジニア研修で使うテーブルを作成し編集する方法について学びました。
次は、 「検索を使い様々な角度からデータを分析する」方法について学んでいきましょう。