
私たちはデータベースに囲まれて暮らしている
これは決して大げさな表現ではありません。
例えば、グーグルの検索エンジン、SNSのタイムライン、オンラインショッピングの購入履歴、スマートフォンの連絡先、そして日常的に利用する多くのアプリケーションの裏側で動いているのが、データベースです。
現代社会では、データベースは情報の保管、整理、検索の中心的な役割を果たします。私たちが瞬時に情報を取得できるのは、データベースの高い効率性によるものです。
新人エンジニアの皆さんにとって、データベースは避けて通れない技術領域の一つです。なぜなら、あらゆるシステムやアプリケーションがデータを必要とし、そのデータを効果的に管理・運用するためには、データベースの知識が不可欠だからです。皆さんが将来どのようなプログラミング言語を必要とするかは分かりません。しかし、ほとんどの方は何らかのデータベースを扱うのではないでしょうか。
このテキストでは、基本的な概念から、その設計の方法をMySQLというデータベースを使って学んでいきます。この知識をしっかりと身につけることで、今後のエンジニアとしてのキャリアをより確固たるものとしてください。
1. データベースの基本
データベースは、情報やデータの集合を保存・管理するためのシステムです。より正確にはデータベース管理システム【DBMS:Database Management System】と呼ぶべきですが、通例でデータベースと呼ぶことがありますのでここでもそう呼びたいと思います。
データベースは、コンピュータ上でデータを組織化し、効率的にアクセス・操作するための仕組みを提供します。テキスト、数値、画像、音声など、さまざまな種類のデータを保存することができます。
データベースの主な目的は、データを一元管理し、整合性を確保することです。データベースは、複数の関連するデータを関連付け、効率的に検索、追加、更新、削除するための機能を提供します。
データベースは、テーブルと呼ばれる表形式で情報を表現します。テーブルは、行と列から成り、それぞれの行がデータのレコードを表し、列がデータの属性(フィールドまたはカラム)を表します。ちょうどJavaでもフィールドという言葉は属性を意味していました。本テキストでも積極的にフィールドと言う言葉を使っていきたいと思います。
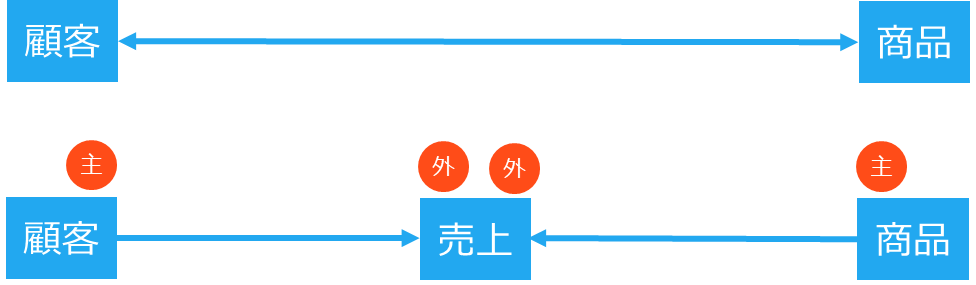
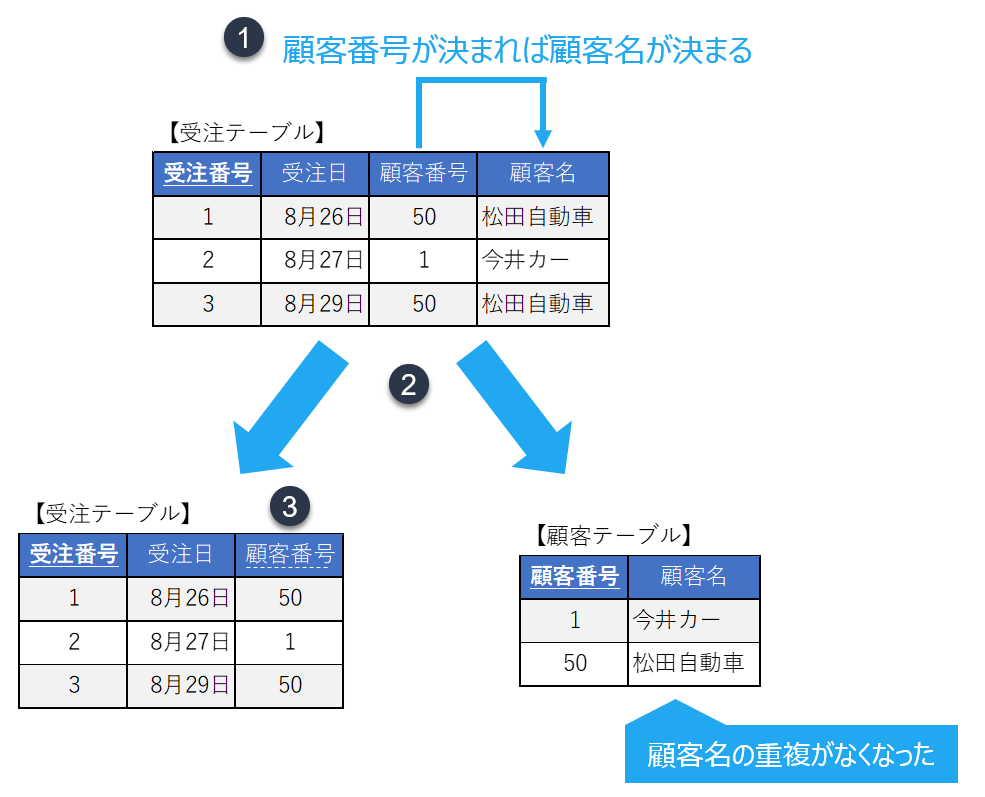
さらにリレーショナルデータベースでは、テーブル間の関係(リレーション)を定義することができます。以下の図は受注テーブルと顧客テーブルの関係を表現しています。受注テーブルの受注番号と顧客テーブルの顧客番号は主キーと呼ばれます。(下線がついています)それに対して、受注表の顧客番号は外部キーと呼ばれます。(点線がついています)
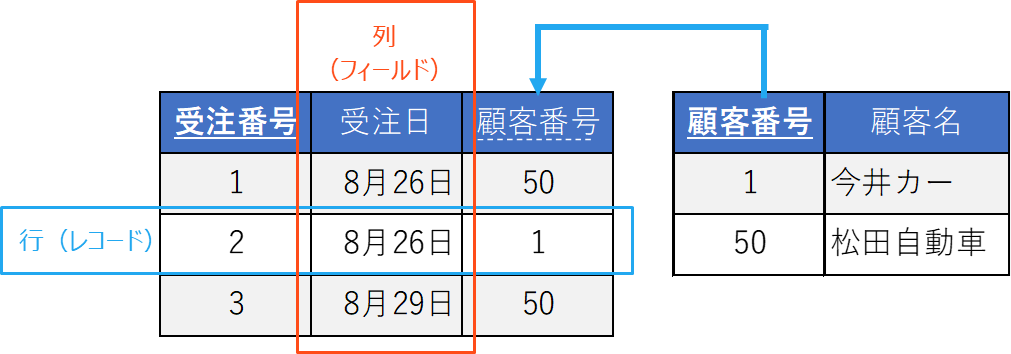
- ①「受注番号1」の顧客名を答えなさい。
| あなたの答え: |
- ②「8月26日の受注」という条件で顧客名を特定できますか?
| あなたの答え: |
- ③顧客テーブルに「顧客番号」という列が無いとどのような不都合がありますか?
| あなたの答え: |
- ④受注テーブルに「顧客番号」という列が無いとどのような不都合がありますか?
| あなたの答え: |
主キーと外部キーについては後で詳述しますが、ここでも簡単に説明すると、
主キー【Primary Key】 はデータベースにおけるテーブルで、各行(レコード)を一意に識別するために使われるフィールド(またはフィールドの組み合わせ)です。主キーに設定されたフィールドは、そのテーブル内で重複する値を持つことができず、また、null(空の値)を含むこともできません。受注テーブルの受注番号、顧客テーブルの顧客番号は主キーの例です。
外部キー 【Foreign Key】はテーブルのフィールドで、別のテーブルの主キーを参照するために使われます。外部キーを使うことで、異なるテーブル間でデータの整合性を保つことができます。例えば、上記の例では「顧客テーブルの顧客番号」と「受注テーブルの顧客番号」のリレーションによって各注文がどの顧客に関連しているかを識別できています。

1件のレコードを特定するカギとなるフィールドなのでキーと呼ばれます。
2. データベースの利点
単なるファイル(例えばエクセルファイル)と比較して、データベースには多くの利点があります。
データの信頼性
データベースは、データの整合性と一貫性を確保するための仕組みを提供します。データベースに保存されるデータは、あらかじめ定義されたルールに従って整合性がチェックされます。例えば、「商品マスタテーブルに存在しない限りは商品を売り上げテーブルに挿入できない」といった仕組みによりデータの正確性と信頼性が維持されます。単なるファイルの場合は、そのようなルールを設定することが困難です。
データの共有と一元管理
データベースを使用すると、複数のユーザーが同じデータにアクセスし、データを共有できます。また、データの重複や不整合を防ぐことができます。複数のアプリケーションやシステムが同じデータベースを共有することで、データの一元管理が可能になります。例えば、人事データベース、勤怠管理システム、給与計算システムは同じ社員情報を管理するデータベースにアクセスするかもしれませんね。
データの効率的な検索
データベースは高速なデータの検索と処理を可能にします。データベースには処理の最適化などの機能が組み込まれており、大量のデータの検索や集計、分析などを迅速に行うことができます。単なるファイルの場合は、別途、プログラムを書かないとそのようなことはできません。
データのセキュリティ
データベースはデータのセキュリティを確保するための機能を提供します。アクセス制御や権限管理により、権限を持つユーザーのみがデータベースにアクセスできるようにできます。また、データのバックアップと復旧機能も備えており、データの喪失や破損からデータを保護することができます。単なるファイルの場合は、きめ細かなアクセス制御をすることは困難です。
プログラムとの連携
データベースは、JavaやPython、Webアプリケーションなどのプログラムから簡単に利用できます。SQLを使ってデータの登録・検索・更新・削除を行えるため、画面で入力された注文情報を保存したり、会員情報を検索して表示したりできます。単なるファイルよりも、システム開発で安全かつ効率的にデータを扱いやすい点が大きな利点です。
3. リレーショナルデータベース
現在最も多く使われているのはリレーショナルデータベース【Relational Database】です。データをテーブルの形式で表現するデータベースです。
リレーショナルデータベースでは、データは複数のテーブルに分割されます。各テーブルは、行(レコード)と列(フィールドまたは属性)から構成されます。テーブルはエンティティ(実世界の実体や概念)を表し、エンティティの属性はテーブルの列に対応します。テーブル間の関係は、関連するデータの結びつきを表現します。
以下のような特徴があります。
テーブルと関連性
テーブル間の関連性を定義することができます。例えば、“顧客”テーブルと“受注”テーブルの間には、一人の顧客が複数の注文を持つ“1対多”の関係があります。関連は主キーと外部キーの組み合わせで表現されます。主キーや外部キーについては後で詳述します。
データの構造化と整理
データをテーブルの形式で論理的に組織化するため、データの整理が容易です。ちょうどエクセルなどの表計算ソフトの表のような形です。テーブルと関連性により、データの重複や冗長性を削減し、データの一貫性と信頼性を高めることができます。
データの柔軟な操作
SQLという言語を使用してデータベースに対する操作や問い合わせを行うことができます。SQLは強力な言語であり、データの検索、挿入、更新、削除などさまざまな操作を行うことができます。SQLにより、データの取得や分析、レポートの生成などが効率的に行えます。
データの拡張性と保守性
リレーショナルデータベースは拡張性があります。新しいデータや要件に対応するためにデータベースを柔軟に拡張できます。テーブルの追加や変更などが比較的容易であり、データベースの構造を簡単に変更できます。また、データの保守性も高く、データの修正や更新が容易です。
このような特徴から、現在最も広く使用されています。おそらく皆さんのアルバイト先でもリレーショナルデータベースが使われていたのではないでしょうか?
4. データベースの設計
この章では、データベースをどのような考え方に基づいて設計するのかを解説しています。特に「正規化とER図はデータの重複を排除するためにテーブルを分割する」という考え方は重要であり、正規化とER図の目指すところは同じであるということをご理解ください。正規化はボトムアップでER図はトップダウンでテーブルを分割します。
設計の前提
ここで、自動車の販売管理データベースを例にとってER図を使った設計の流れを確認しましょう。あなたは自動車メーカーA社のために販売管理システムを作るという設定です。ただし、顧客は個人ではなく法人であり自動車販売会社だということにしたいと思います。以下のような注文書が発行できる販売管理システムのためのデータベースをイメージします。
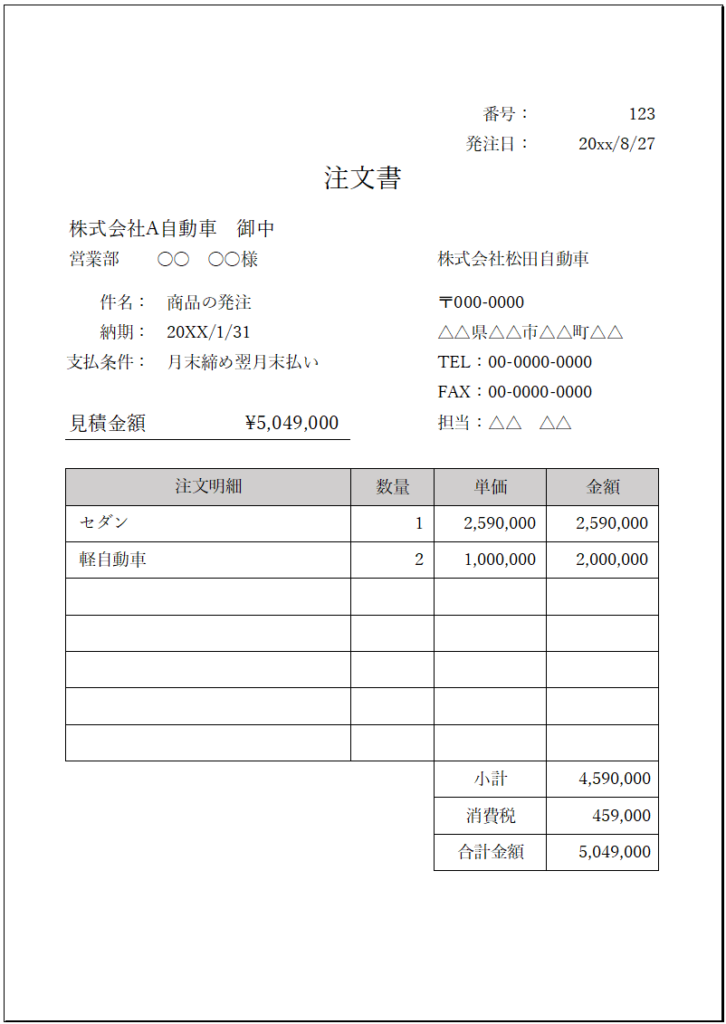
- ①「松田自動車の伝票」や「軽自動車の伝票」といった表現でこの1枚を特定することはできますか?
| あなたの答え: |
- ②この1枚の注文書を確実に特定するための情報はなんですか?
| あなたの答え: |
- ③注文書の番号(123)が決まれば顧客名(松田自動車)は決まりますか?
| あなたの答え: |
- ④軽自動車の数量(2台)を特定するために最低限必要な情報の組み合わせを答えなさい。
| あなたの答え: |
- ⑤このような注文書が複数あったときに注文明細にセダンと書かれているのはこの1枚だけでしょうか?
| あなたの答え: |
主キー
主キー【Primary Key】は、リレーショナルデータベースにおいて特定のテーブル内の各レコード(行)を一意に識別するために使用される列(フィールド)です。主キーはそのテーブル内で一意であり、重複する値を持つことはありません。
主キーは以下の特徴を持ちます。
- 主キーの値は、そのテーブル内の他のレコードと重複することはありません。つまり、主キーはそのテーブル内の各レコードを一意(ユニーク)に特定します。
- テーブル内の他の列との組み合わせでも、主キーの値は一意である必要があります。つまり、主キーはそのテーブル内で重複する値を持つことはありません。
- 主キーの値はNULL(欠損値)を許容しません(非NULL)。各レコードは主キーの値を持つ必要があります。
主キーはテーブルの設計段階で選択されます。一般的には、唯一性と一意性を保証するために、意味のあるフィールドや一意な識別子(ID)を主キーとして使用します。例えば、顧客テーブルの主キーには"顧客番号"という列を使用するかもしれませんね。
主キーはデータベース内のデータを特定するために使用されます。他のテーブルとの関連性を確立するためにも使用され、外部キーとの関係を形成することがあります。また、主キーを基準にデータの整列やインデックスの作成など、データの高速な検索や操作にも利用されます。
主キー制約
主キー制約【Primary Key Constraint】は、リレーショナルデータベースにおいて主キーの一意性と非NULL制約を強制するための制約です。主キー制約はテーブルの設計時に定義され、主キー列に適用されます。
主キー制約の適用により、データベース管理システム(DBMS)は主キーの一意性と非NULL性を自動的に強制します。もし主キー制約に違反するデータが挿入されようとすると、エラーが発生します。
主キー制約はデータの完全性と一貫性を保つために重要です。一意性制約により、データベース内のデータを正確に特定できます。また、非NULL制約により、重要なデータが欠落することを防ぎます。
主キー制約は主キーに関連する操作にも影響を与えます。例えば、関連するテーブル間での参照整合性の維持や、外部キーとの関係の確立に使用されます。(後述)
例えば、以下の顧客テーブルにおいての主キーは顧客番号です。この場合、顧客番号の1番や50番は他の顧客に割り振ることができません。また、NULLも許されません。

複合キー
複合キーは、複数のフィールドを組み合わせて一つのユニーク(一意)なキーとして利用することです。単一のフィールドだけでは一意性を確保することができない場合に使用されます。例えば、以下のテーブルにおいて1つのレコードを特定するには受注番号だけでも、商品番号だけでも足りません。しかし、受注番号と商品番号を組み合わせれば、どの注文のどの商品で総額いくら売れたのかという1レコードが特定されることになります。
例えば、「受注番号1番で商品番号1番のレコードは8月26日の受注で、顧客番号50番の松田自動車への販売、商品名はセダンで単価は2,590,000円、数量は1台、金額は2,590,000円」といった具合に1行のレコードが特定できます。
ナチュラルキーとサロゲートキー
ナチュラルキー【Natural Key】とは、データベース設計において自然に存在するデータの属性を主キーとして利用することです。例えば学生番号や社員番号がその例です。ナチュラルキーは、ビジネス上の意味を持つキーであり、そのデータ自体が一意で変更されにくいものを指します。
例えば、社員情報のデータベースにおいて「社員番号」がナチュラルキーとして利用されることが考えられます。社員番号はビジネス上の意味を持ち、各社員に一意に割り当てられるため、主キーとして利用するのは自然です。
ナチュラルキーの利点
- ビジネスの文脈での意味がある。例えば、2024年に入社した12番めの社員であれば「202412」など。
- 外部のシステムやユーザーとの連携がしやすい。「202412」の社員といえば誰のことか容易に分かる。
ナチュラルキーの欠点
- 値が変わる可能性がある場合、それに伴う変更の影響が大きい。例えば、企業合併により社員コードを振り直す必要性が発生したなど。
- 一意性の保証が難しい場合がある。
ナチュラルキーと対照的なものに、サロゲートキー【Surrogate Key】があります。サロゲートキーは、データベース内部で自動的に生成される一意の識別子(例: 自動インクリメントのID)で、ビジネス上の意味は持ちませんが、一意性や変更の問題が少ないという利点があります。
例えば、社員テーブルで、社員番号をキーとしている場合、何らかの理由で社員番号が変わることがあったら、それに関連するすべてのテーブルのデータも変更する必要が出てきます。しかし、サロゲートキーを使用すると、そのような変更の影響を受けずにデータを安定して管理できます。また、A社とB社が統合し、両社の顧客テーブルを1つにまとめる場合、もしナチュラルキーを使用していると、同じキーの顧客が存在する可能性があります。しかし、サロゲートキーを使用すると、各顧客に一意のIDが割り当てられ、問題を避けられるのです。

ちなみに、【Surrogate】には、代理という意味があります。代理母は英語で【surrogate mother】といいます。
使ってもよいナチュラルキーの条件として「変更される可能性が非常に低い」というものがあります。例えば、「JP,US,UK」といった国コード、「01:北海道、02:青森県」といった都道府県コードは変更される可能性が低く、使用しても問題ないと考えられます。
外部キー
外部キー【Foreign Key】は、2つのテーブル間の関連性を表現するための制約です。外部キーは、あるテーブルの(子テーブル)が他のテーブルの主キー(親テーブル)を参照することを指定します。
外部キー制約
外部キー制約により、データベース管理システム(DBMS)は以下の点を自動的に管理します。
- 子テーブルの外部キー列には、親テーブルの存在する値のみが許可されます。
- 親テーブルで主キーの変更(更新または削除)が行われた場合、それに関連する子テーブルのデータも削除(または適切に更新)されます。
例えば、以下のようなテーブルにおいて、子テーブルの顧客番号には親テーブルの顧客番号である1か50しか入れることができません。また、親テーブルから1番の「今井カー」のレコードを削除した場合には、子テーブルの該当する2番のレコードも削除されなくてはなりません。
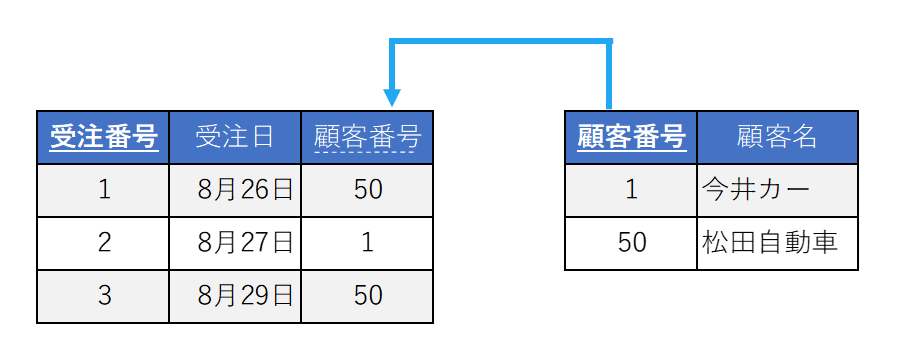
外部キー制約を使用することで、データベース内の関連データの整合性を確保し、参照の一貫性を維持することができます。
外部キー制約は、データの参照整合性を保つために重要です。テーブル間のデータ整合性を確保し、意味のあるデータを維持するために使用されます。ただし、当社の新人研修ではあえて外部キー制約を外してシステム開発をすることもあります。なぜなら、ダミーデータを入力する上で外部キー制約が邪魔になることがあるからです。
なお、以下の図解(ER図:後述)では矢印の向きで一方の主キーが他方に外部キーとして入り込むことを表現します。
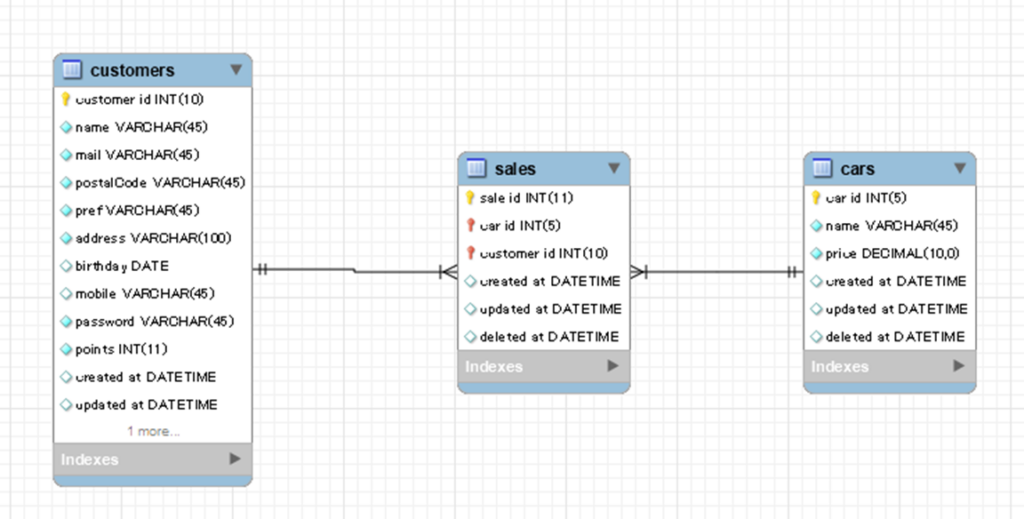
4.1 正規化
正規化【Normalization】は、データの冗長性や依存関係を減らし、データの整合性と効率性を向上させる手順です。なお、正規化を施したテーブルを正規形といいます。
正規化の目的は、データの重複を排除し、データの依存関係を最小限に抑えることです。データベース内のデータが一貫性を持ち、データの変更や操作が容易になります。
正規化は通常、以下の一連の手順に従って行われます。
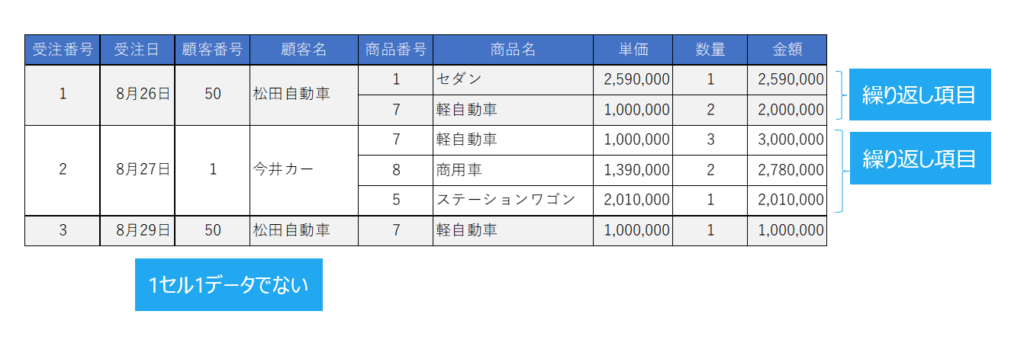
- 非正規形
- 繰り返し項目のある状態です。
- 第一正規形
- テーブル内の各列が単一の値を持ち、データの重複が無い状態です。
- 第二正規形
- 複合キーがある場合に、そのうちの1つのみにおいて決まる項目があればそれらを独立させて別のテーブルにします。つまり複合キーがない場合はこのステップはスキップされます。
- 第三正規形
- 主キー以外の項目で、これが決まればあれが決まるという項目があれば、それらを独立させて別のテーブルにします。
それ以上の正規化も存在しますが、通常は第三正規形までが一般的に使用されます。正規化を進めることでデータの整合性が向上しますが、テーブルの分割により問い合わせの複雑さが増すこともあります。
正規化により、データの冗長性や更新の問題を減らし、データの一貫性と信頼性を高めることができます。また、データの効率的な検索と操作が可能になり、データベースのパフォーマンスが向上します。
以下のように正規化されていないテーブルを非正規形といいます。

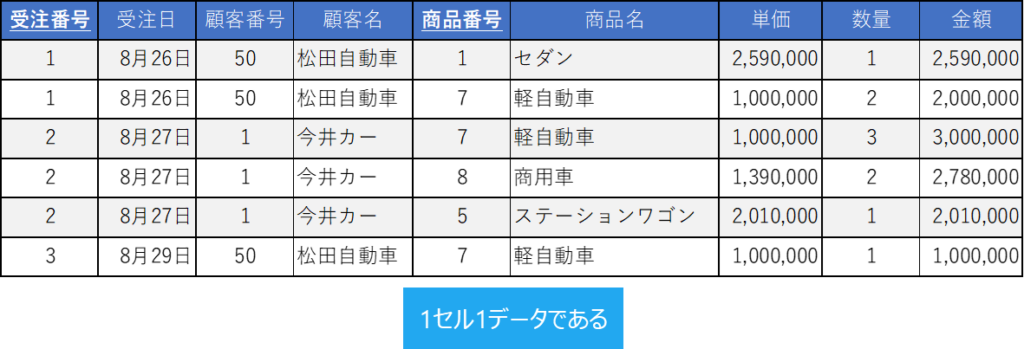
第一正規化
第一正規化は、正規化の最初のステップです。第一正規化では、1セル1データである以下のようなテーブルです。
第一正規化の要点は以下の3点です。
- 個々のセルには単一の値が格納される。テーブル内の各セルには、複数の値が含まれることはありません。セル内のデータは1つの値のみを保持するようにします。
- 列(フィールド)は一意である。テーブル内の各フィールドは、異なる属性を表す必要があります。つまり、重複するフィールド名や同じ属性を表すフィールドを持つことはありません。上記の例で言えば、「商品名」のフィールドは1つだけで、横に複数の「商品名」のフィールドが並ぶことはありません。
- レコード(行)は一意である。テーブル内の各レコードは、一意の識別子(主キー)によって区別されます。レコードの重複は許されず、一意性を保つ必要があります。なお、この場合の主キーは複合キーであっても良いです。上記の例では、「受注番号が1番」で「商品番号が1番」のレコードは1件だけしか許されません。
第一正規化により、データの冗長性を排除し、データの一貫性と効率性を向上させることができます。複数の属性を含むセルや重複したデータの使用を避けることで、データの更新や検索が容易になります。
では、第一正規形にはどのような問題があるのでしょうか?
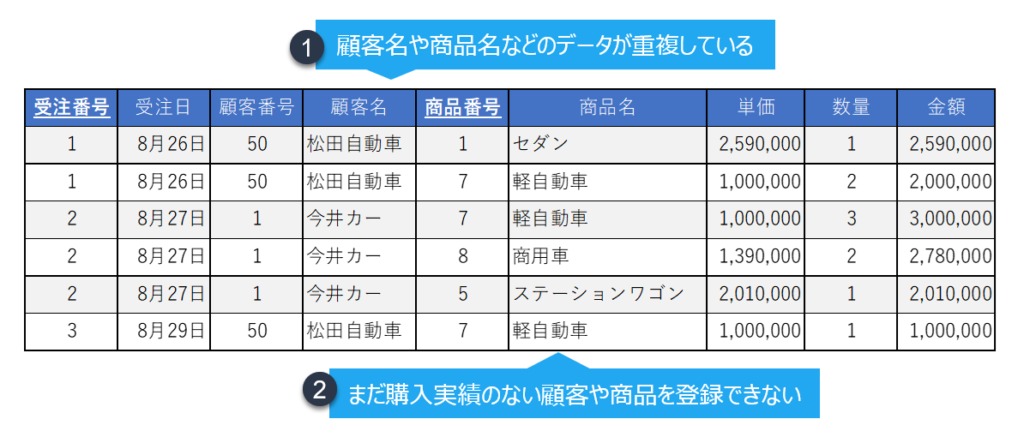
例えば、上記の例では、
- 顧客名や商品名に重複があり、データ容量を余分に消費しているのみならず、名称を変更する際に漏れが発生する可能性があります。
- まだ商品を買っていない顧客、まだ買われていない商品をデータベースに登録するすべがありません。
といった問題があります。そこでさらに正規化を進めることになります。
今からペアに非正規形のテーブルを第一正規化する説明をしていただきます。講師の説明を元に以下に準備のためのメモをしてください。
| ノート |
第二正規化
第二正規化は、正規化の2番目のステップです。第二正規化では、テーブル内のデータをより適切に分割し、非キー列がキーに完全に依存する状態にします。
第二正規化の要点は以下の通りです。
主キーが複合キーである場合に、その複合キーの一部によって特定可能な項目は別テーブルにする。
第二正規化の手順は以下のとおりです。
- テーブル内の部分関数従属を特定します。部分関数従属とは、テーブル内の非キー列が主キーの一部(つまり複合キーの一部)だけに依存している状態を指します。逆に言えば複合キーがない場合は第二正規化は問題になりません。
- 部分関数従属を持つフィールドを新しいテーブルに分割します。部分関数従属を解消するために、中間テーブルを作成し、非キー列がそれぞれのテーブルの主キーに依存するようにします。
- 中間テーブル間の関連性を確立するために、主キーと外部キー制約を使用します。データの参照整合性が維持されます。
具体例で見てみましょう。以下のテーブルを使って第二正規化を進めます。
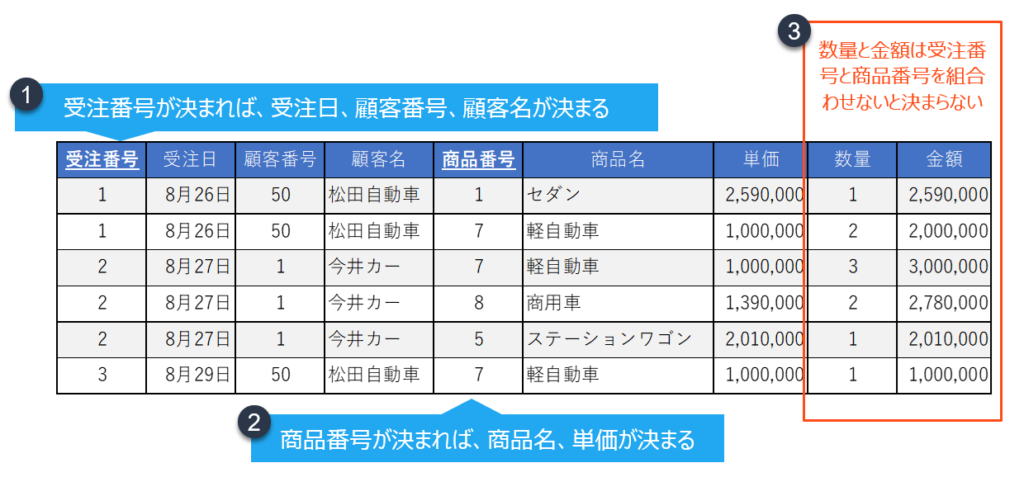
- 受注番号が決まれば、受注日、顧客番号、顧客名が決まりますので、この部分を独立したテーブルにします。
- 商品番号が決まれば、商品名、単価が決まりますので、この部分を独立したテーブルにします。
- しかし、数量と金額は受注番号と商品番号を組み合わせないと決まらないためそれら4つは一つのテーブルにする必要があります。
よって以下のように「受注テーブル」「商品テーブル」「受注明細テーブル」の3つのテーブルになります。
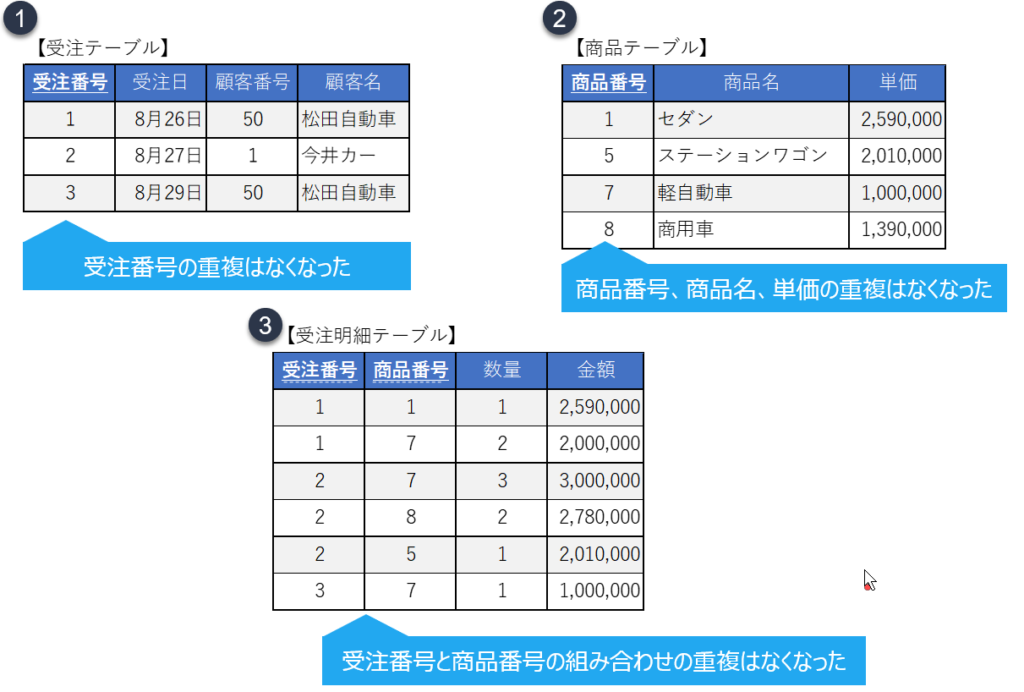
このようにデータの重複をなくすことを「1 Fact, 1 Place」と呼ぶことがありますのでご記憶ください。
※なお、このとき一行を特定するために受注明細テーブルに明細番号(主キー)を設けるとなお好都合です。
第二正規化により、テーブル内の非キー列が正規化され、データの重複や冗長性が減少します。中間テーブルの作成により、データの整合性が高まり、データの更新や操作が容易になります。
今からペアに第一正規形のテーブルを第二正規化する説明をしていただきます。講師の説明を元に以下に準備のためのメモをしてください。
| ノート |
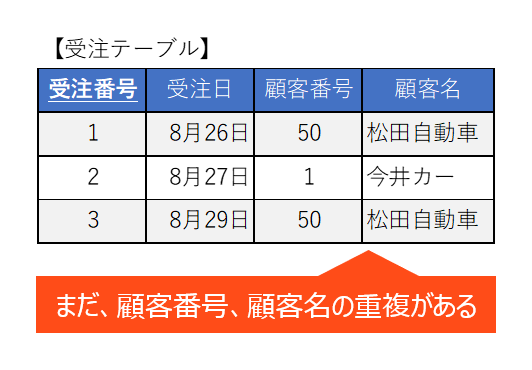
第二正規形の問題点は何でしょうか?
それは以下のように「受注テーブル」において顧客番号と顧客名に重複があることです。この問題を解消するのが第三正規化です。
第三正規化
第三正規化では、テーブル内の「非キー列間の推移的な依存関係」を解消し、データの冗長性を排除します。
「非キー列間の推移的な依存関係」とは何でしょうか?
例えば、上記の受注テーブルにおいて顧客番号は主キーではありませんでした。なぜなら、受注番号が決まれば、顧客番号も決まるからです。
しかし、非キーである顧客番号が決まれば、顧客名は決まるという関係があります。これを「非キー列間の推移的な依存関係」といいます。「顧客番号」と「顧客名」を独立したテーブルにするのが第三正規化です。
第三正規化の手順は以下のとおりです。
- テーブル内の推移的な依存関係を特定します。つまり、あれが決まればこれが決まるといった関係、非キー列が他の非キー列に依存している関係を見つけます。
- 推移的な依存関係を解消するために、中間テーブルを作成し、非キー列をそれぞれのテーブルに移動します。
- 中間テーブル間の関連性を確立するために、主キーと外部キー制約を使用します。それによりデータの参照整合性が維持されます。つまり、先の例で、顧客番号と顧客名からなるテーブルを独立させても、元のテーブルに顧客番号を残す必要があります。なぜなら、そうしないとテーブルを結合する手がかり(キー)が失われてしまうからです。
また、計算して求まる導出項目は第三正規化の時点で削除されます。例では「金額」は「数量 × 単価」で求められるため導出項目です。
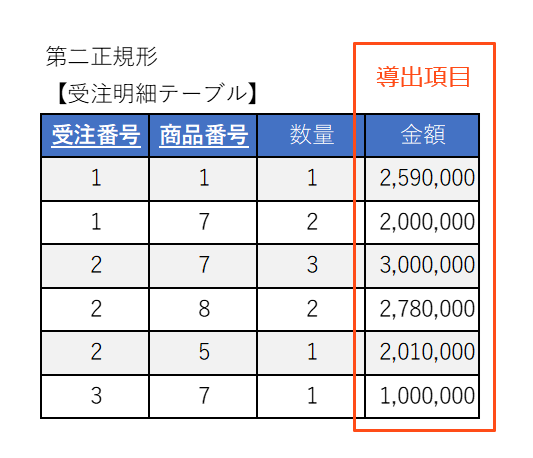
第三正規化により、テーブル内の非キー列間の推移的な依存関係が解消されます。データの冗長性や重複が減少し、データの一貫性と効率性が向上します。
ただし、全てのテーブルが第三正規化の要件を満たす必要はありません。第三正規化は、非キー列間に推移的な依存関係が存在するテーブルに適用されます。テーブルの設計時にデータの依存関係を考慮し、必要に応じて正規化を適用することが重要です。
今からペアに第二正規形のテーブルを第三正規化する説明をしていただきます。講師の説明を元に以下に準備のためのメモをしてください。
| ノート |
第三正規形のテーブルは以下のようになります。

なお、正規化の要請ではありませんが、受注明細テーブルに「受注明細番号」のようなサロゲートキーをつけることが一般的です。そうすることで主キー1つで1レコードが選択できるため、後で学ぶSQLがシンプルに書けるからです。
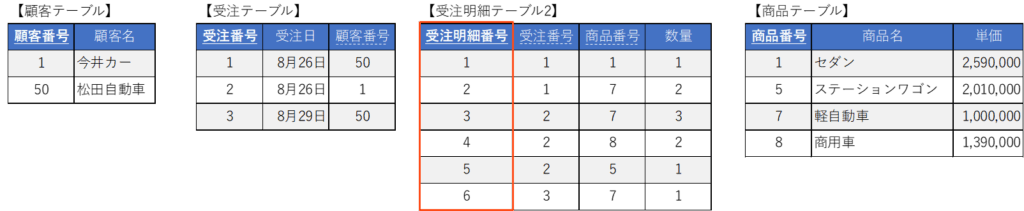
受注明細テーブルに「受注明細番号」をつける
第三正規形まで進めたテーブルはER図で作成するテーブルと同じになります。いわば正規化はテーブル設計のボトムアップ・アプローチ、ER図はテーブル設計のトップダウン・アプローチと呼ぶことができるでしょう。
4.3 非正規化
非正規化(Denormalization)とは、正規化されたデータベース構造の一部を意図的に解除し、情報の重複や冗長性を許容することで、データの検索効率や履歴保持機能を向上させる設計手法です。通常は、正規化によりデータの整合性や保守性が保たれますが、処理速度や記録性を優先する場合、非正規化が有効です。
正規化と非正規化の違い
正規化(Normalization)は、データの重複を排除し、論理的に分割された構造でデータの整合性を保つための設計手法でした。
一方、非正規化はあえてこれらの正規化ルールを緩和し、以下のような目的で使用されます。
- 複雑な結合(JOIN※後述)を回避して検索効率を上げる
- 時系列における情報の履歴を保持する
- 集計やレポート作成を高速化する
マスターテーブルとトランザクションテーブル
データベース設計において、情報は主に「マスターテーブル」と「トランザクションテーブル」に分けられます。
- マスターテーブル(Master Table):顧客、商品、社員など、比較的変更頻度の低い基礎データを管理します。
- トランザクションテーブル(Transaction Table):注文、請求、ログイン履歴など、日々発生する取引や操作履歴を記録します。
マスターテーブルのデータが変更された場合、正規化された構成ではトランザクションテーブルの過去データにもその変更が反映されてしまう可能性があります。当時の正確な記録を保持できないという課題が発生します。
トランザクションでは、過去の記録をそのまま残すことが大切なので、あえて非正規化(情報を埋め込む)することがあるのです。
非正規化と履歴保持の関係
非正規化を用いると、トランザクションテーブル側に当時のマスター情報(例えば顧客名や商品の単価)を直接保存できるため、マスターテーブルが後から変更されても、注文当時の記録に影響を与えません。
以下に例を示します。
正規化された構成(再掲)
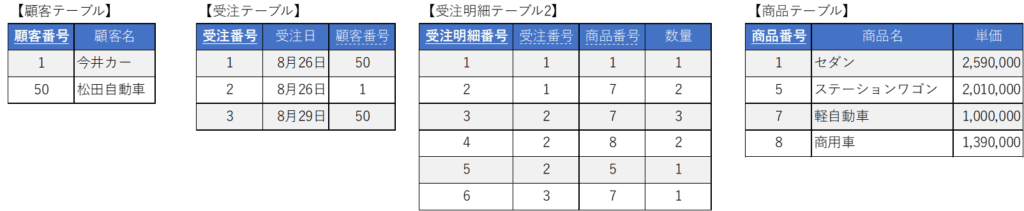
この構成では、顧客名が変更されたり、商品の単価が改定(例:軽自動車が1,200,000円に値上げ)されたりした場合、過去の受注履歴を参照した際に現在のマスタ情報が表示されてしまい、当時の正確な売上金額がわからなくなります。
非正規化された構成(履歴保持)
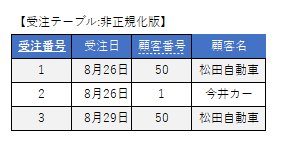
このように、注文時点のマスタ情報をコピーして保持しておくことで、後日「松田自動車」が「松田カー」に社名変更してマスタデータが更新されても、8月26日時点の請求書の表記を変更せずにすみます。
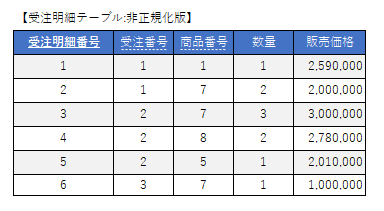
また、同様に「8月26日時点ではいくらで販売したか」という情報を正しく保持し続けることができます。
非正規化の利点
- 処理効率の向上
JOINを使わずに単一テーブルでデータが取得できるため、検索や集計処理が高速化されます。 - 履歴の保持が容易
トランザクション側でマスタ情報を複写することで、当時の情報が失われることなく保存されます。 - 分析・報告用途に適している
売上分析やレポート作成において、当時の単価や担当者名などが重要な情報として使えます。
非正規化の注意点
- 情報の重複により、保存容量が増加する
- 類似情報の更新時に整合性を保つためのロジックが必要
- データの矛盾が生じやすく、保守性が低下する可能性がある
このため、非正規化を採用する場合は、用途やパフォーマンス要件を明確にしたうえで判断する必要があります。
4.2 ER図
ER図【Entity-Relationship Diagram】は、データベースの設計や分析に使用される図形表現の一種です。ER図は、エンティティ【Entity】とエンティティ間の関係【Relationship】をグラフィカルに表現します。
ER図の主要な要素
エンティティは、データベース内で独立して存在する実世界の実体や概念を表します。例えば、"顧客"や"商品"などがエンティティとなります。エンティティは四角形で表現され、エンティティ名が記載されます。エンティティはリレーショナルデータベースではテーブルになります。
属性は、エンティティが持つ特性や情報のことです。属性はテーブルのフィールドになります。
関係とは、エンティティ間の関係を表現します。テーブルでは主キーと外部キーで関係を表現できます。
カーディナリティ【Cardinality】は、エンティティ間の関係がいくつのインスタンスを持つかを示します。エンティティ間の関係には1対1、1対多、多対多の関係があります。多対多の場合には中間テーブルが必要になります。

1対1は、例えば、日本のように一夫一婦制を採用している国の夫婦の関係です。夫を一人(1レコード)選べば自動的にその妻は一人(1レコード)に決まります。また、妻をひとり選べば自動的にその夫は決まります。
他にも「人と本籍地」や「人と居住地」、「人と免許証番号」なども1対1の関係です。1対1の関係は通常は同じテーブルの中に収めれば大丈夫です。

1対多は、例えば、生物学上の親子の関係です。親をひとり選んでも自動的にその子供は(一人っ子でない限り)決まりません。しかし、子供を一人(1レコード)決めればその生物としての親は1組のカップル(1レコード)に決まります。
他にも「担任の先生と生徒」などの関係がそうです。1対多の関係は同じテーブルの中では表現できず、別テーブルが必要になります。

多対多は、例えば、友達同士の関係です。人をひとり(Aさんとする)選んでも自動的にその友達は一人(1レコード)に決まりません。さらにAさんの友達の一人(Bさんとする)を選んでもその友達は一人(1レコード)に決まりません。
他にも「学生と授業」、「商品と注文の」関係がそうです。多対多の関係は、間に中間テーブルを作る必要があります。

以下の流れでER図を考えてみましょう。
- エンティティを抽出する
- エンティティ間の関係(カーディナリティ)を考える
- 多対多の場合には中間テーブルを用意する
1. エンティティを抽出する
エンティティを抽出するには管理したいものの名詞を挙げていきます。Javaの時にオブジェクト指向を学んだ方ならおなじみのやり方ですね。ここでは「顧客(企業)」と「商品(車両)」という二つのエンティティが思いついたとしましょう。

2. エンティティ間の関係を考える
この2つの関係は多対多といえます。なぜなら、「顧客」を1社(1レコード)つかまえても「商品」を1台(1レコード)に特定することはできません。なぜなら、上記の注文書を見る限り「顧客」は複数の「商品」を購入する可能性があるからです。同様に、「商品」を1台(1レコード)つかまえても「顧客」を一人(1レコード)に特定することはできません。なぜなら、「商品」は複数の「顧客」によって購入されることがあるからです。

3. 多対多の場合には中間テーブルを用意する
今回は多対多の関係なので中間テーブルが必要です。中間テーブルは受注としましょう。「顧客」から見て「受注」は多です。なぜなら、1社の「顧客」は複数回注文することがあるからです。しかし、「受注」から見て「顧客」は1です。1回の「受注」をした「顧客」は1社に決まるからです。
また、「受注」から見て「商品」は多です。なぜなら、上記の注文書を見る限り1回の「受注」で複数の「商品」を注文することが可能だからです。また、「商品」から見た「受注」も多です。なぜなら1台(種類)の「商品」が複数の「受注」を受けることがあるからです。
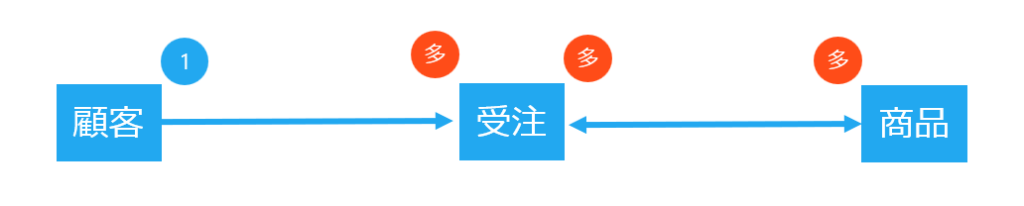
したがって、まだ設計は終わりではありません。「受注」と「商品」との間に中間テーブルが必要です。テーブルの名前は「明細」としましょう。「受注」から見て「明細」は多です。なぜなら、1回の受注で複数の明細(どんな商品を何台買ったか)というレコードは複数あるからです。逆の「明細」から見た「受注」は1です。なぜなら、1つの「明細」レコードはかならず1つの「受注」レコードに属するからです。さらに「明細」レコードから見た「商品」レコードは1です。「明細」レコードごとに「商品」は1台に決まるからです。逆に、「商品」レコードから見た「明細」レコードは多です。1つの「商品」は「明細」テーブルで複数購入されている可能性があるからです。

結果的に4つのテーブル、「顧客」、「受注」、「明細」、「商品」というテーブルができました。この結果は第三正規形のつのテーブルと同じです。
講師の説明を受けて、ご自身でも上記のER図を使った設計を再現してみましょう。また、ペアの方に説明をしてみましょう。
| ノート |
5. SQL
SQL(Structured Query Language)とは、データベース管理システム(DBMS)に問い合わせ【Query 】、データの検索、挿入、更新、削除を行うための標準化【Structured】された言語【Language】です。リレーショナルデータベースに対する操作や管理を効率的に行います。
SQLは大別してDDL【Data Definition Language】とDML【Data Manipulation Language】に別れます。
DDLは「Definition=定義」ということで、データ定義言語と呼ばれます。DDLは、データベースの構造やスキーマを定義・変更するためのコマンドです。主なDDLコマンドには以下のようなものがありますが、研修ではMySQLWorkbenchの機能を使いますので覚える必要はありません。
| CREATE(作成) | テーブルやビュー、インデックスなどのデータベースオブジェクトを作成します。 |
| ALTER(変更) | 既存のデータベースオブジェクト(テーブル、フィールドなど)の構造や属性を変更します。 |
| DROP(削除) | データベースオブジェクトを削除します。 |
| TRUNCATE(切り捨て) | テーブル内のデータをすべて削除しますが、テーブル構造は保持されます。 |

一方、DMLは「Manipulation=操作」ということでデータ操作言語と呼ばれます。DMLは、データベース内のデータの操作や問い合わせを実行するためのコマンドです。この研修ではDMLを中心に学びますのでしっかり覚えましょう。
| INSERT(挿入) | データベースに新しいデータを挿入します。 |
| SELECT(選択) | データベースからデータを検索します。問い合わせの結果としてデータを取得します。 |
| UPDATE(更新) | データベース内の既存のデータを更新します。 |
| DELETE(削除) | データベース内のデータを削除します。 |
なお、上記4つの操作を総称してCRUD【Create, Read, Update, Delete】と呼ぶことがありますので知っておきましょう。
具体的なSQL文の書き方はこれ以降の章で詳しく学んでいきます。
以上、今回はデータベースとは何か?について学びました。
次は「MySQLWorkbenchを使い効率的にMySQLを扱う」を学びます。