
【初心者向け】正解率とF1スコアって何?〜精度評価の指標をやさしく解説〜
 山崎講師
山崎講師
こんにちは。ゆうせいです。
はじめに:モデルの「賢さ」って、どうやって測るの?
機械学習やAIの世界では、「このモデル、どれくらい正確なの?」という問いがとても大切です。
その答えを出すための代表的な指標が…
- 正解率(Accuracy)
- F1スコア(F1 Score)
今日はこの2つを、テストの採点やじゃんけんの勝率みたいな身近な例を交えて、分かりやすく解説します!
1. 正解率(Accuracy)とは?
🧠 定義
全体の中で「正しく当てたもの」の割合。
✏️ 数式

(日本語版:正解率 = 正解した件数 ÷ 全体の件数)
- TP:正しいものを「正しい」と判断した数(True Positive)
- TN:間違いを「間違い」と判断した数(True Negative)
- FP:間違いを「正しい」と誤判断(False Positive)
- FN:正しいものを「間違い」と誤判断(False Negative)
🎓 例え話:○×クイズの得点率
10問中、7問正解したら「正解率70%」ですよね。これがAccuracyのイメージです。
✅ 長所・短所
| 項目 | 内容 |
|---|---|
| 長所 | 単純で分かりやすい |
| 短所 | クラスの偏りに弱い!(例:病気の人が100人中1人しかいない場合など) |
2. F1スコアとは?
🧠 定義
Precision(適合率)とRecall(再現率)*のバランスを取った指標。
✏️ 数式

(日本語版:F1スコア = 適合率と再現率の調和平均)
こんにちは。ゆうせいです。
📏 調和平均とは?〜バランス重視の平均値〜
調和平均とは、「小さい値の影響を強く受ける平均」のことです。
特に割合や速度のような“逆数的な値”の平均を出すときに使われます。
たとえば、ある道を「時速30kmで行き、時速60kmで帰った」ときの平均速度は単純平均(45km/h)ではなく、調和平均(約40km/h)になります。
数式は以下の通りです:
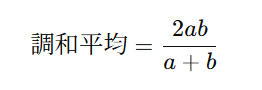
F1スコアでは「Precision(適合率)」と「Recall(再現率)」という2つの重要な要素のバランスを見るために、この調和平均が使われます。
なぜかというと、一方が極端に低いとF1スコア全体も低くなり、どちらか一方だけに偏らないようにする働きがあるからです。
🔍 じゃあ「適合率」と「再現率」って?
「適合率(Precision)」と「再現率(Recall)」という2つの指標は、混同行列(Confusion Matrix)を使うと、とてもわかりやすく理解できます。
🔢 混同行列とは?
ある2クラス分類の予測結果を整理すると、以下のような表になります:
| 実際は Positive | 実際は Negative | |
|---|---|---|
| 予測:Positive | TP(真陽性) | FP(偽陽性) |
| 予測:Negative | FN(偽陰性) | TN(真陰性) |
ここで使われる4つの略語は:
- TP(True Positive):正しく「陽性」と予測
- FP(False Positive):誤って「陽性」と予測(=偽アラート)
- FN(False Negative):誤って「陰性」と予測(=見逃し)
- TN(True Negative):正しく「陰性」と予測
🎯 適合率(Precision)
「予測が陽性だと言った中で、本当に陽性だった割合」
数式で書くと:
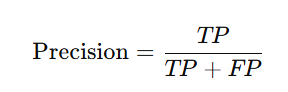
つまり、モデルが「当たり!」と判断したものの信頼度を示します。
誤検出を減らしたいとき(例:スパムメール判定)に重要です。
🔍 再現率(Recall)
「実際に陽性だった中で、どれだけ正しく予測できたか」
数式はこちら:
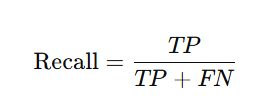
これは、実際に陽性だった人をどれだけ見逃さずに見つけたかを示します。
見逃しが許されない場面(例:がん検診)で重要です。
もちろんです、ゆうせいです!
🎓「適合率」と「再現率」の覚え方:PとRに注目して記憶しよう!
🔤 まずは語の意味からおさらい
- Precision(適合率):
「予測した Positive のうち、どれだけ本当に Positive だったか?」
→ “当たりの正確さ” - Recall(再現率):
「実際の Positive を、どれだけ見つけられたか?」
→ “拾い上げ力”
🧠 Precision の覚え方(Pの法則)
✅ 3つの“P”に注目!
| 覚えるポイント | 単語 | 意味 |
|---|---|---|
| Precision | 評価指標の名前 | 「当てた中で本物だった割合」 |
| Predicted Positive | 予測した陽性(TP + FP) | モデルが「陽性」と言った全体 |
| True Positive | 実際に正解だった陽性 | 本当に正しかった部分だけカウント |
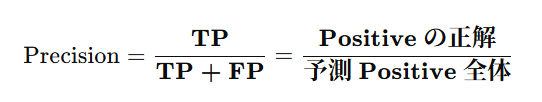
→ 「予測Positiveの中の真のPositive」=正解率の“質”を測る!
🧠 Recall の覚え方(Rの法則)
✅ “R”は“Real(実際)”のR!
| 覚えるポイント | 単語 | 意味 |
|---|---|---|
| Recall | 評価指標の名前 | 「見逃していないか」を測る指標 |
| Real Positive | 実際の陽性(TP + FN) | 本当は陽性だったもの全体 |
| True Positive | 正しく当てられたもの | 成功した検出部分 |
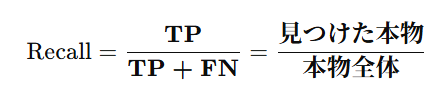
→ 「本物(Real Positive)をどれだけ拾えたか」
💬 まとめのゴロ合わせ
- Precision(P)=「Pが多すぎたら危険」
→ 「陽性だ!」と言い過ぎて外れ(FP)が多いと、Precisionは下がる。 - Recall(R)=「RはReal(本物)を取りこぼすな」
→ 実際に陽性だった人をちゃんと見つけられないと、Recallは下がる。
🎯 一言で整理!
Precision = Positive に「当たり」がどれだけ含まれていたか
Recall = Real Positive をどれだけ取りこぼさなかったか
🎓 まとめ
- 適合率:予測の正しさ(当てた中でどれだけ当たりか)
- 再現率:見逃しの少なさ(本物をどれだけ拾えたか)
状況に応じてどちらを重視すべきかが変わるため、混同行列で全体像を確認しながら、PrecisionとRecallのバランスを見るのがプロフェッショナルな評価方法です。
✅ 長所・短所
| 項目 | 内容 |
|---|---|
| 長所 | 偏ったデータ(例:陽性が少ない医療データ)でも、バランスよく評価できる |
| 短所 | 正解率と比べて直感的にはわかりにくい |
まとめ:いつどっちを使うべき?
| 状況 | 向いている指標 |
|---|---|
| 全体の中でクラス(カテゴリ)の数がバランス良い | 正解率(Accuracy)で十分なことも |
| クラスの偏りが激しい(例:不良品1%、スパムメール3%など) | F1スコアがおすすめ |
| 「当てるだけでなく、見逃しや誤診も困る!」 | Precision/RecallやF1で評価すべき |
🌱 最後に:まずは混同行列を描こう!
「正解率もF1も分からない…」と思ったら、まず混同行列(confusion matrix)を描いてみましょう!
- どこで当ててるのか?
- どこで外してるのか?
- どれが間違いで、どれが惜しいのか?
それを見ながら、「今どの指標が重要なのか?」を考えるのが、プロの思考です!
生成AI研修のおすすめメニュー
投稿者プロフィール

