
【初心者向け】Q学習とSARSA(サルサ)とは?
 山崎講師
山崎講師
こんにちは。ゆうせいです。
〜行動して学ぶ!強化学習の基本2大アルゴリズムをやさしく解説〜
はじめに:強化学習とは?
まず土台として、「強化学習(Reinforcement Learning)」とは何かを簡単に説明すると…
エージェント(学習する存在)が環境と対話しながら、最適な行動を学んでいく方法です。
- 「行動」をして
- 「報酬」をもらって
- 「うまくいくパターン」を覚えていく
まるでゲームのプレイヤーが“トライ&エラー”で攻略を覚えるような学習法ですね。
🔤 そして登場するのが Q学習とSARSA
この強化学習の中で、代表的な学習アルゴリズムが:
- Q学習(Q-learning)
- SARSA
どちらも「行動ごとの価値(Q値)を学習していく」という点は同じですが、学び方(更新ルール)が少し違います。
✅ 共通する考え方:Q値とは?
Qとは、「状態(State)で、ある行動(Action)をしたとき、将来的に得られる報酬の期待値」のこと。
これを Q(s, a) と書きます。
Q値の「Q」は、「Quality(質・価値)」の頭文字です。
具体的には、ある状態 sで特定の行動 aを選んだときに、将来得られる報酬の質(期待値)を意味します。
つまり Q(s, a) は、「この行動はどれくらい価値があるか?」を数値で表すもの。
状態だけでなく、「行動」にも依存する点が、価値関数(V値)との違いです。
Q学習では、このQ値を繰り返し更新して最適な行動を学習していきます。
ちなみに価値関数(Value Function)とは、ある状態 sにおいて、そこから将来どれだけの報酬を期待できるかを示す関数です。
これは状態の良し悪し(=価値)だけに注目しており、具体的な行動は含みません。
一方で Q値は、「状態と行動の組み合わせ」に対する価値です。
つまり、「状態だけ」=V値、「状態+行動」=Q値という関係になります。
🎯 Q学習(オフポリシー学習)
● 特徴
- 「最適な行動を基準にQ値を更新」するアルゴリズム
- 実際に何を選んだかにかかわらず、理論的に一番良い行動を想定して学習
● 数式(やさしく)
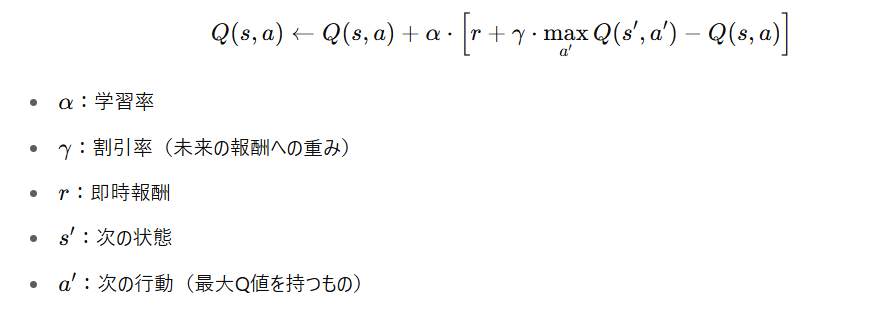
● イメージ
実際は「右へ行ったけど」、
「次に“もし左に行っていたら”一番良かったとして学習」する。
✅ SARSA(オンポリシー学習)
SARSAという名前は、このアルゴリズムがQ値(行動価値)を更新する際に使う「5つの要素」の頭文字を並べたものです。それぞれ以下のような意味を持ちます:
S:State(現在の状態)
A:Action(その状態で選んだ行動)
R:Reward(行動に対する報酬)
S':Next State(次の状態)
A':Next Action(次の状態で選んだ次の行動)
この順番に従って学習が進むため、アルゴリズム全体が「SARSA」と名付けられました。
SARSAはオンポリシー型の強化学習手法で、「実際にエージェントが選んだ行動」に基づいて学習します。つまり、“もしこうしたら…”ではなく、“実際にこうした”という経験に基づいて価値を更新するのです。
Q学習が「理想的な最適行動に基づいて学ぶ(オフポリシー)」のに対して、SARSAは「現実にとった行動の結果を素直に反映する」ため、より安定的で現実的な学習が可能とされています。
このように、SARSAという名前そのものが「何をもとに学んでいるか」を端的に表している点が、この手法の特徴でもあります。
● 特徴
- 「実際に選んだ行動に基づいてQ値を更新」する
- より現実に忠実な学習
● 数式(やさしく)
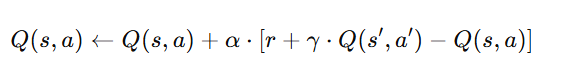
このとき、a' は「実際に次のステップで取った行動」になります。
● イメージ
「実際に右へ行って、その結果をそのまま反映」*する。
🔍 Q学習 vs SARSAの違い
| 比較項目 | Q学習 | SARSA |
|---|---|---|
| タイプ | オフポリシー(最適行動に基づく) | オンポリシー(実際の行動に基づく) |
| 安全性 | 理論上の最善を追う → 攻め型 | 現実に忠実 → 守り型 |
| 学習の安定性 | やや不安定だが早く収束 | 安定しやすいが収束は遅め |
| 向いている場面 | 最短ルートなどを探すゲーム系 | ノイズが多い環境・ロボット制御など |
🎓 例え話:迷路での学び方
- Q学習:
→ 「次にこっちに行ったけど、地図上ではあっちの方がよさそうだったな。次はそう覚えておこう!」 - SARSA:
→ 「実際にこっちへ行ってこの報酬だった。次もこの経験をもとに学ぼう。」
🔚 一言まとめ
Q学習は“理想ベース”、SARSAは“現実ベース”の学習法!
どちらも Q(s, a) を学ぶが、「何を信じてアップデートするか」が違うんです。
生成AI研修のおすすめメニュー
投稿者プロフィール


