【初心者向け】機械学習のLog Lossとは?正解への"確信度"を測る評価指標を徹底解説!
 山崎講師
山崎講師こんにちは。ゆうせいです。
機械学習のモデルを評価するとき、どんな指標を使っていますか?
「やっぱり正解率(Accuracy)でしょ!」と答える方が多いかもしれません。もちろん、正解率はとても直感的で分かりやすい指標です。でも、それだけを見ていると、モデルの本当の実力を見誤ってしまう可能性があるとしたら…?
今回は、そんな正解率の弱点を補い、より深くモデルの性能を評価できる「Log Loss(対数損失)」という指標について、一緒に学んでいきましょう!
Log Lossって、そもそも何者?
Log Lossは、一言でいうと「モデルの予測が、どれだけ『確信をもって』正解/不正解を当てられているか」を測るための指標です。
機械学習の分野では「損失関数」の一つに分類されます。
損失関数と聞くと難しく感じるかもしれませんが、要は「モデルの成績の悪さを示すスコア」だと思ってください。ゴルフのスコアと同じで、この値が小さければ小さいほど、モデルの性能が良いということになります。
なぜ正解率だけではダメなの?
ここで一つ、簡単な例を考えてみましょう。
明日の天気を「晴れ」か「雨」かで予測する2つのAIモデルがあるとします。そして、実際の明日の天気は「晴れ」でした。
- モデルA:「明日は90%の確率で晴れでしょう!」と予測
- モデルB:「明日は60%の確率で晴れでしょう!」と予測
さて、この2つのモデル、正解率で評価するとどうなるでしょうか?
どちらも「晴れ」と予測して、結果も「晴れ」だったので、どちらも「正解」ですよね。正解率だけを見ると、2つのモデルの性能は同じに見えてしまいます。
でも、あなたはどちらのモデルをより信頼しますか?
おそらく、より高い確率で「晴れ」だと予測したモデルAの方ではないでしょうか。Log Lossは、この「予測の確信度」の違いをきちんと評価してくれる、とても賢い指標なのです!
Log Lossの心臓部!計算の仕組みを覗いてみよう
では、Log Lossはどのようにして「確信度」をスコアにしているのでしょうか。少しだけ数式が出てきますが、一つずつ丁寧に解説するので安心してくださいね!
二値分類(正解か不正解かの2択)の場合、Log Lossは以下の式で計算されます。

うわっ、と思った方、大丈夫です!記号の意味さえ分かれば怖くありません。
: Log Lossの値。私たちが最終的に求めたいスコアです。
: 予測したデータの総数です。
: シグマと読みます。「全部足し合わせる」という意味の記号です。
: i番目のデータの「正解ラベル」です。正解なら1、不正解なら0が入ります。
: i番目のデータが正解(1)であるとモデルが予測した「確率」です。0から1の間の値を取ります。
: 対数(ログ)です。Log Lossの最も重要な部分!
ポイントは、
対数には、「入力が0に近づくほど、出力がマイナスの無限大に近づく」という面白い性質があります。
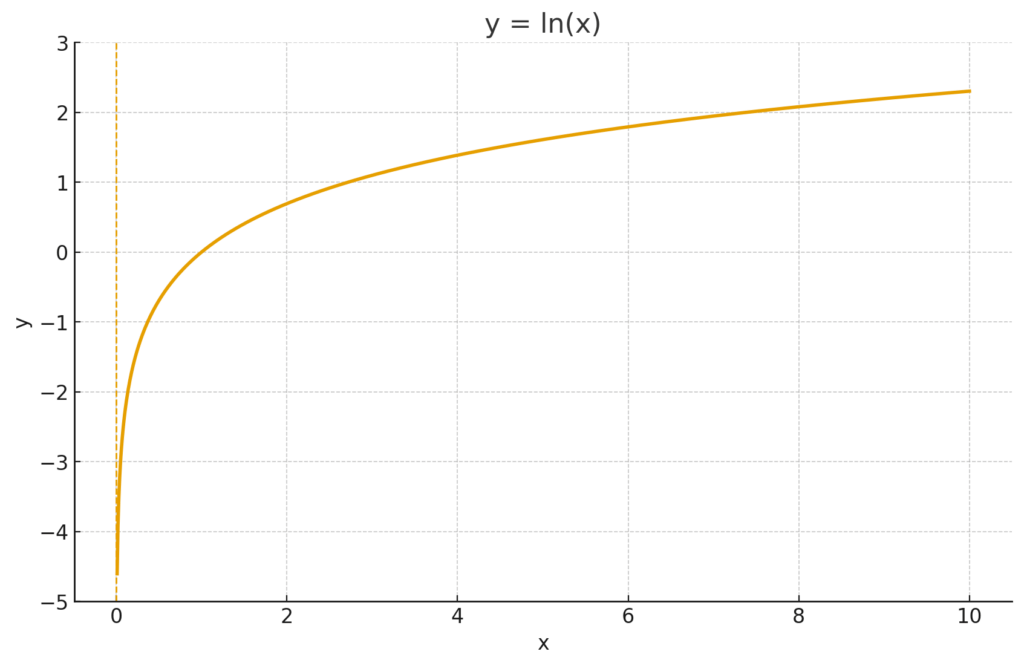
これを先ほどの天気予報の例で考えてみましょう。
正解は「晴れ」だったので、


- モデルAは「90%の確率で晴れ (
)」と予測しました。
は比較的小さなマイナスの値(約-0.1)になります。
- もしモデルが「10%の確率で晴れ (
)」と、自信なさげに間違った予測をしたらどうでしょう。
は-2.3となり、ペナルティが大きくなります。
- さらに、もし「1%の確率で晴れ (
)」と、確信をもって大外れな予測をしたら…?
は-4.6となり、ペナルティはさらに跳ね上がります!
つまりLog Lossは、「間違った予測を、高い確信度で行うほど、非常に大きなペナルティ(損失)を与える」という仕組みになっているのです。これにより、ただ正解を当てるだけでなく、より確信度の高い、質の良い予測をするようにモデルを導くことができるわけですね。
(数式の先頭についているマイナス記号は、対数の計算結果がマイナスになるので、それをプラスに直して「損失」として分かりやすくするためのものです。)
Log Lossのメリット・デメリット
ここで、Log Lossを使うことのメリットとデメリットをまとめておきましょう。
メリット
- 予測の「確信度」まで評価できる: これが最大のメリットです。モデルがどれくらい自信を持って予測しているかを評価に含めることができます。
- モデルの確率出力を改善できる: 大きなペナルティを避けるため、モデルはより正確な確率を出力するように学習していきます。
- 最適化しやすい: Log Lossは数学的に微分しやすい形をしているため、モデルを学習させる際の計算(勾配降下法など)と相性が良いという技術的な利点もあります。
デメリット
- 値の解釈が直感的ではない: 「Log Lossが0.3です」と言われても、正解率80%のように、どれくらい良いのかを直感的に把握するのは少し難しいかもしれません。
- 外れ値に敏感: もしモデルがたった一つのデータに対してでも「100%こちらが正解だ!」と確信して大外れした場合、Log Lossの値が極端に大きくなってしまうことがあります。
まとめと次のステップへ
今回は、機械学習の評価指標であるLog Lossについて解説しました。
Log Lossは、単に正解か不正解かを見るだけでなく、モデルの予測が持つ「確信度」という、より深い部分にまで踏み込んで評価するためのパワフルな指標です。
もしあなたがこれから分類モデルを作ることがあるなら、ぜひ実行してみてください!
「まずは、正解率と合わせてLog Lossも必ず確認する!」
この習慣をつけるだけで、モデル評価の解像度が格段に上がるはずです。
さらに興味が湧いた方は、「クロスエントロピー誤差」というキーワードで調べてみることをお勧めします。実は、Log Lossはこのクロスエントロピーという情報理論の概念と深いつながりがあり、学ぶことでさらに理解が深まるでしょう。
評価指標はLog Loss以外にも、F値やAUCなど、様々なものが存在します。解きたいタスクやデータの特性によって最適な指標は変わってきます。色々な指標を知り、使いこなせるようになって、一歩先のエンジニアを目指していきましょう!
セイ・コンサルティング・グループの新人エンジニア研修のメニューへのリンク
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。
最新の投稿
 新人エンジニア研修講師2026年6月19日Spring BootでセッションIDがアドレスバーに表示される理由と対策|新人エンジニア向けにJSESSIONIDを解説
新人エンジニア研修講師2026年6月19日Spring BootでセッションIDがアドレスバーに表示される理由と対策|新人エンジニア向けにJSESSIONIDを解説- 新人エンジニア研修講師2026年6月18日JavaのOptionalでnullを安全に扱う方法|NullPointerExceptionを防ぎ、DAOの戻り値をわかりやすくする
- 新人エンジニア研修講師2026年6月18日ローカルSMTPを使って問い合わせ完了メールを送る方法|新人エンジニア研修向けにSpring BootとJavaMailSenderを解説
- 新人エンジニア研修講師2026年6月18日DevToolsでHTTP通信・エラー・DOMを確認する方法|新人エンジニア向けにブラウザ開発者ツールを解説