
「p値」だけで満足していませんか?統計学の真実が見える「効果量・信頼区間・検定力」を完全攻略
 山崎講師
山崎講師こんにちは。ゆうせいです。
統計学を勉強し始めると、どうしても「p値」や「有意差」という言葉ばかりに目がいってしまいませんか?
「有意差が出た!やったー!」と喜んで終わりにしてしまうこと、実はとっても危険なんです。
例えば、あるダイエットサプリを飲んで「体重の変化に有意差があった」とします。でも、その変化がたったの「10グラム」だったらどうでしょう。
統計的には意味があっても、ダイエットとしてはあまり嬉しくないですよね。
そこで登場するのが、今日解説する3つのヒーロー、「効果量」「信頼区間」「検定力」です。
これらを知ることで、データの「本当の意味」が見えてきますよ。
高校生でもわかるように、数式は最小限にしてイメージで掴めるように解説していきますね。
さあ、一緒に統計の深い世界へ足を踏み入れてみましょう!
効果量(Effect Size):その変化、どれくらい凄いの?
まず最初は「効果量」です。
これは一言でいうと、「その違いや変化がどれくらい大きいか」を表す数値です。
効果量のイメージ
先ほどのダイエットサプリの話を思い出してください。
たくさんの人を集めれば、わずか10グラムの差でも「統計的に有意(偶然ではない)」という結果が出ることがあります。でも、私たちが知りたいのは「どれくらい痩せるのか」というインパクトの大きさですよね。
この「インパクトの大きさ」を数値化したものが効果量です。
有名なものに「Cohen's d(コーエンのd)」という指標があります。
数式で書くとこんな感じです。

難しそうに見えますが、要は「平均値の差」を「データのばらつき」で割っているだけなんです。
これが「0.2なら小」「0.5なら中」「0.8なら大」といった目安があります。
メリットとデメリット
メリットは、サンプルサイズ(データの数)に左右されずに、純粋な「差の大きさ」を評価できることです。
何千人ものデータを集めて無理やり有意差を出すような「p値ハッキング」に惑わされなくなります。
デメリットとしては、分野によって「どれくらいなら大きいと言えるか」の基準が違うことです。
医療の薬と、Webサイトのクリック率改善では、期待される効果量の大きさは全く異なります。
信頼区間(Confidence Interval):真実はどの範囲にある?
次は「信頼区間」です。
ニュースの世論調査などで「信頼区間95%」という言葉を聞いたことがありませんか?
信頼区間のイメージ
これは「投げ網漁」に例えるとわかりやすいです。
池の中にいる魚(真の平均値)を捕まえたいとします。でも、池の水は濁っていて魚の正確な位置は見えません。
そこで、私たちは網(区間)を投げます。
「95%信頼区間」というのは、「同じやり方で100回網を投げたら、95回はその網の中に魚(真の値)が入るだろう」という広さの網を使うことです。
例えば、「このクラスの平均身長は170cmです」と言い切るよりも、「168cmから172cmの間にありそうです」と言われたほうが、どれくらい確実なのか実感が湧きますよね。
数式での表現は少し複雑になりますが、イメージとしては以下のような範囲を示します。

メリットとデメリット
メリットは、推定の「精度」がわかることです。
区間の幅が狭ければ狭いほど、ピンポイントで予測できていることになり、データへの信頼度が増します。
デメリットは、解釈を間違えやすいことです。
よく「95%の確率で真の値がこの中にある」と説明されますが、厳密な統計学の定義では少し違います(ここは少し哲学的になるので、まずは「それくらい信頼できる範囲」と捉えておいて大丈夫です)。
検定力(Power):見逃しを防ぐ探知機の性能
最後は「検定力」です。英語ではパワーと言います。
なんだか強そうな名前ですよね。
検定力のイメージ
これは「金属探知機」の性能だと思ってください。
砂浜に埋まっているコイン(本当に差があること)を見つけたいとします。
性能の悪い探知機(検定力が低い)だと、深く埋まっているコインや小さなコインを見逃してしまい、「ここには何もありません(差はありません)」と誤った判断をしてしまいます。
逆に、性能の良い探知機(検定力が高い)なら、ちゃんと「ここにありますよ!」と反応できます。
つまり検定力とは、「本当に差があるときに、正しく『差がある』と見抜ける確率」のことです。
一般的には「80%以上」を目指すのが望ましいとされています。
数式的には、「第二種の過誤(本当は差があるのに見逃す確率)」を 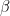

メリットとデメリット
メリットは、実験や調査をする前に「どれくらいのデータを集めればいいか」を計画できることです。
検定力を計算せずに実験を始めるのは、ゴールの距離を知らずにマラソンを走るようなものです。
デメリットは、計算が少し面倒なことと、事前の設定(どれくらいの効果量を期待するか)が必要なことです。
しかし、ここをサボると、せっかくの実験が無駄になってしまうかもしれません。
まとめと今後の学習ステップ
いかがでしたか?
p値という「有無」の判定だけでなく、
- 変化の大きさを見る 効果量
- 推定の幅を見る 信頼区間
- 発見する力を見る 検定力
この3つをセットで考えることで、データ分析の質は格段に上がります。
これらは互いに関連し合っていて、例えばデータをたくさん集めれば信頼区間は狭くなり、検定力は上がります。
さて、基礎的な概念がわかったところで、次は実際に手を動かしてみましょう。
今後の学習の指針として、以下のステップをおすすめします。
- G*Powerなどのツールを触ってみる無料のソフトを使って、サンプルサイズと検定力の関係をシミュレーションしてみてください。
- 自分の興味のある論文を読んでみるp値だけでなく、信頼区間や効果量が書かれているかチェックしてみましょう。
- PythonやR言語での計算に挑戦するコンピュータを使えば、複雑な計算も一瞬で終わります。
統計学は、道具として使いこなしてこそ意味があります。
焦らず、一つずつ武器を増やしていきましょう!
また次回の記事でお会いしましょう。
セイ・コンサルティング・グループの新人エンジニア研修のメニューへのリンク
投稿者プロフィール


