
【AIの推敲術】一発で完璧を目指さない!質を劇的に高める「Iterative Refinement(反復的改善)」
 山崎講師
山崎講師こんにちは。ゆうせいです。
みなさんは、大事なメールやレポートを書くとき、書き殴った「下書き」をそのまま送信ボタンで送ったりしませんよね?
必ず読み返して、「ここはもっと分かりやすく」「この言葉は削ろう」「あ、大事な件を書き忘れた」と修正してから送るはずです。
これを「推敲(すいこう)」と言います。
実は、AIも同じなんです。
AIはいわば「超・早書きのライター」です。すごいスピードで文章を作りますが、その中身は人間でいう「最初の下書き」に過ぎません。
そこで必要になるのが、今回解説する「Iterative Refinement(反復的改善)」という考え方です。そして、その代表的なテクニックであり、情報の密度を極限まで高める魔法「Chain-of-Density(チェーン・オブ・デンシティ)」についてもお話ししましょう。
これを覚えれば、AIの出力が「まあまあ」から「プロレベル」へと進化しますよ!
Iterative Refinement(反復的改善)とは?
一言で言うと、「AIに自分で自分の答えをチェックさせて、何度も書き直させること」です。
通常、私たちはAIに質問して、返ってきた答えをそのまま受け取ります。
しかし、この手法では次のようなループを作ります。
- Generate(生成): まず、AIに答えを書かせる。
- Critique(批評): AIに「この答えの悪いところはどこ? 足りない情報は?」と自分でダメ出しさせる。
- Refine(改善): ダメ出しをもとに、答えを書き直させる。
これを繰り返すことで、人間が何度も原稿を修正するように、AIの回答の質がどんどん上がっていくのです。
究極の要約術「Chain-of-Density」
この「反復的改善」を最も効果的に使ったテクニックの一つが、前回少し触れた「Chain-of-Density(情報の密度を上げる連鎖)」です。
ニュース記事や議事録の要約をさせるときに、驚くべき威力を発揮します。
「カルピスの原液」を作るイメージ
普通の要約は、文章を短くするときに、細かい情報を捨ててしまいます。結果、薄味の要約になりがちです。
一方、Chain-of-Densityは、文字数を増やさずに、情報量だけを増やしていきます。まるで、水分だけを飛ばして味を凝縮する「煮込み料理」や、カルピスの原液を作るような作業です。
具体的なプロセスの解説
AIに次のようなステップで指示を出します。
ステップ1:初期要約
まず、普通に要約を書かせます。
AI:「A社が新製品を発表しました。とても便利です」
(これだとスカスカですね)
ステップ2:情報の抽出(Missing Entities)
次に、元の文章にはあるけれど、要約には含まれていない「重要なキーワード(実体)」を探させます。
AI:「『発売日』『価格』『製品名X』が含まれていません」
ステップ3:融合と再生成(Fusion)
ここが重要です。「文字数は増やさずに、さっきのキーワードをすべて盛り込んで書き直しなさい」と指示します。
AI:「A社は製品名Xを発売日に価格で発表し、利便性を向上させました」
これを数回繰り返す(Iterative)ことで、無駄な言葉が削ぎ落とされ、重要な情報だけがギチギチに詰まった「高密度な要約」が完成するのです。
品質の向上を数式でイメージしよう
このプロセスがなぜ品質を高めるのか、数式のイメージで見てみましょう。
通常の出力 

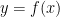
これは一発勝負なので、精度には限界があります。
一方、反復的改善(Iterative Refinement)は、漸化式(ぜんかしき)のようになります。

:今の原稿
:今の原稿に対する「ダメ出し」や「改善点」
:次の原稿
今の原稿に「改善点」を足し合わせることで、次の原稿が生まれます。
回数 
メリットとデメリット
「推敲」は素晴らしいことですが、コストもかかります。
メリット:人間を超える品質が出せる
一発書きでは人間より劣るかもしれないAIも、3回、5回と書き直させることで、人間が書くよりも精度の高い、抜け漏れのない文章を作成できるようになります。GPT-4などの高性能モデルでこれを行うと、専門家レベルのアウトプットが出ることが研究で示されています。
デメリット:とにかく遅い
単純に、書く量と処理回数が数倍になるため、答えが出るまでに時間がかかります。チャットボットのように「即答」が求められる場面では、ユーザーを待たせてしまうため不向きです。
今後の学習の指針
いかがでしたか?
Iterative Refinement(反復的改善)とは、AIに「職人のこだわり」を持たせる技術でした。
「一回でいい答えが出ない!」と諦める前に、「じゃあ、今の答えをどう直せばよくなる?」とAI自身に聞いてみてください。きっと、驚くような改善案を出してくれますよ。
今回で、3つの応用プロンプト(分解、行動、反復)の解説が終わりました。
ここまで学んだあなたは、もう立派なプロンプトエンジニアの入り口に立っています。
次は、これらの技術をどうやって実際のシステムに組み込むか、より実践的な「システム設計」や「評価(Evaluation)」の世界が待っています。
- Self-Correction(自己修正): 反復的改善の一種で、間違いを自分で直す技術です。
- Best-of-N: 答えをN個作らせて、一番いいものを選ぶ手法です。
- LLM-as-a-Judge: AIに、AIの回答を採点させる(評価者にする)技術です。
AIとの対話は、磨けば磨くほど光ります。ぜひ、泥臭く「推敲」を繰り返してみてください!
それでは、またお会いしましょう。ゆうせいでした。
あなたの次の一歩
ChatGPTに、あえて少し下手なメールの文面を入力し、こう頼んでみてください。
「このメールをより丁寧に書き直して。ただし、3回推敲を行って、そのたびに『前の案より良くなった点』を説明してから、次の案を出して」
AIが自分で進化していく過程を目の当たりにできますよ!
セイ・コンサルティング・グループの新人エンジニア研修のメニューへのリンク
投稿者プロフィール


