
【初心者向け】AIの「成績表」を理解しよう!代表的な損失関数(MSE・MAE・交差エントロピー)を易しく解説
 山崎講師
山崎講師こんにちは。ゆうせいです。
みなさんは、テスト勉強をしているとき、どうやって自分の理解度を確認しますか。
答え合わせをして、「あ、間違えた」「惜しい」「全然違う」と一喜一憂しますよね。そして、間違いが多ければ多いほど「もっと勉強しなきゃ」と修正を図るはずです。
実は、AI(人工知能)の学習もこれと全く同じことをしています。
AIが予測した答えと、本当の正解。この2つがどれくらいズレているかを採点し、AIに「お前は今、これくらい間違っているぞ!」と叱ってくれる存在。それが今回解説する 損失関数 です。
この損失関数の選び方ひとつで、AIの性格(学習の進み方)はガラリと変わります。
「厳しく叱る先生」がいいのか、「優しく諭す先生」がいいのか。今日はそんな視点で、代表的な損失関数の世界を覗いてみましょう。
数学が苦手な方も安心してください。数式の意味を言葉で噛み砕いて説明します。
損失関数とは何か
損失関数とは、一言で言えば 「AIの予測の『ダメさ加減』を数値化する計算式」 です。
AIモデルの学習におけるゴールは、この損失関数の値(ロス)をできる限り「0」に近づけることです。
損失が大きければ「全然わかっていない」、損失が小さければ「かなり賢くなった」と判断します。
では、具体的にどのようにズレを計算するのでしょうか。
AIが解く問題の種類によって、使う計算式(関数)が違います。大きく分けて「数値を当てる問題(回帰)」と「種類を当てる問題(分類)」の2つを見ていきましょう。
数値を予測するときに使う損失関数(回帰)
まずは、「明日の気温」や「家の価格」など、連続する数値を予測する場合です。ここでは代表的な2人の「先生」を紹介します。
1. 平均二乗誤差(MSE)
一つ目は、もっともポピュラーな 平均二乗誤差 です。英語では Mean Squared Error といい、略して MSE と呼ばれます。
これは「正解とのズレを2乗して、その平均を取る」という計算方法です。
数式で見るとこうなります。
( 



なぜ、わざわざ「2乗」するのでしょうか。
単に引き算をしただけだと、プラスのズレとマイナスのズレが打ち消し合ってゼロになってしまうかもしれませんよね。2乗することで、マイナスをプラスに変えているのです。
この関数の性格(メリット・デメリット)
このMSE先生は、「大きな失敗に対してめちゃくちゃ厳しい」 という性格を持っています。
たとえば、ズレが「2」なら、2乗して罰則は「4」です。
しかし、ズレが「10」になると、罰則は「100」に跳ね上がります。
つまり、「惜しい間違い」には寛容ですが、「大外れ」をすると雷を落とすのです。
- メリット: 学習が進みやすく、数学的な扱い(微分)が簡単です。
- デメリット: 異常値(外れ値)に弱いです。データの中に一つでも極端な変な値が混じっていると、それに引きずられて学習全体がおかしくなることがあります。
2. 平均絶対誤差(MAE)
二つ目は、 平均絶対誤差 です。英語では Mean Absolute Error 、略して MAE です。
こちらは「正解とのズレの絶対値を取り、その平均を取る」という計算方法です。
絶対値とは、プラスマイナスを無視した「距離」のことですね。
数式はこうなります。

この関数の性格(メリット・デメリット)
MAE先生は、「誰に対しても公平に接する」 性格です。
ズレが「2」なら罰則は「2」、ズレが「10」なら罰則は「10」です。MSEのように、大間違いをしたからといって罰則が爆発的に増えることはありません。
- メリット: 異常値(外れ値)の影響を受けにくいです。データにノイズが混じっていても、淡々と学習を続けられます。
- デメリット: 正解に近づいたとき(誤差が0に近いとき)の計算が少し厄介です。数学的に言うと、0の地点でグラフが尖っているため、学習の最後の一押しがスムーズにいかないことがあります。
種類を分類するときに使う損失関数(分類)
次は、「犬か猫か」や「メールがスパムかどうか」を当てる分類問題です。
ここでは「確率」を扱うため、少し特殊な計算を使います。
3. 交差エントロピー誤差
分類問題の定番中の定番、 交差エントロピー誤差 (Cross-Entropy Loss)です。
これは、前回お話しした「エントロピー(驚きの大きさ)」の概念を使っています。
AIが出した「確率」が、正解のラベルとどれくらい離れているかを計算します。
数式は少し怖く見えるかもしれませんが、やっていることは単純です。

ここで登場する 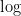

この式にはマイナスがついているので、逆にプラス無限大に急上昇します。
つまり、AIが「これは100%猫だ!」と自信満々に予測したのに、正解が「犬」だった場合、 
この関数の性格(メリット・デメリット)
この先生は、「自信満々で間違えることを許さない」 という性格です。
- メリット: 分類問題において、学習が非常にスムーズに進みます。正解の確率を上げるように強く圧力をかけることができます。
- デメリット: 確率の計算を含むため、回帰問題(数値予測)には使えません。
まとめ:どう使い分ければいいの?
たくさんの損失関数が出てきて混乱したかもしれません。
新人エンジニアのみなさんは、まずは以下の指針を持っておけば大丈夫です。
- 数値を当てたい(回帰) なら、まずは MSE(平均二乗誤差) を使う。
- もしデータに 異常値がたくさん混じっている なら、 MAE(平均絶対誤差) を検討する。
- カテゴリーを当てたい(分類) なら、迷わず 交差エントロピー誤差 を使う。
損失関数は、AIに対する「教育方針」そのものです。
「どんな間違いを減らしたいのか」を考えることが、適切な関数を選ぶ第一歩になります。
第1問:家賃予測で学ぶ「回帰」の損失関数
あなたは「駅からの徒歩分数」をもとに「家賃(万円)」を予測するAIを作りました。
テストデータとして、以下の3つの物件があります。
| 物件 | 本当の家賃 latexy | AIの予測 latexy^ |
| A | 8 | 7 |
| B | 10 | 10 |
| C | 12 | 16 |
物件Aは少し安く予測し、物件Bはピッタリ正解。しかし、物件Cは大外ししてしまいました。
このとき、2つの損失関数で計算結果がどう違うかを見てみましょう。
問題1-1
平均絶対誤差(MAE) を計算してください。
ヒント:単純なズレ(距離)の平均です。
問題1-2
平均二乗誤差(MSE) を計算してください。
ヒント:ズレを2乗してから平均します。
第1問の解答と解説
計算できましたか。では答え合わせをしましょう。
解答1-1:MAE(平均絶対誤差)
まずは、それぞれの「ズレの大きさ(絶対値)」を計算します。
物件A:

物件B:

物件C:

これらを足して、データの個数(3つ)で割ります。
MAE

答えは 約1.67 です。
ズレの平均がそのまま反映されている感じがしますね。
解答1-2:MSE(平均二乗誤差)
次に、ズレを「2乗」してみましょう。
物件A:

物件B:

物件C:

これらを足して、3で割ります。
MSE

答えは 約5.67 です。
ここがポイント
MAE(1.67)に比べて、MSE(5.67)の値がかなり大きくなりましたよね。
原因は物件Cです。ズレが「4」だったのが、2乗されて「16」という巨大なペナルティになりました。
このように、「たった一つの大失敗が、全体の成績を大きく引き下げる(損失を増やす)」 のがMSEの特徴です。
AIに「平均的にそこそこ当てる」よりも「とんでもない大外しだけは絶対に避けてほしい」と教えたいときは、このMSEが効果的なのです。
第2問:犬か猫か?分類の損失関数
次は分類問題です。
画像が「犬(正解ラベル 
今回は計算しやすいように、自然対数( 
( 

問題2-1
「これは犬だ!」と、AIが 0.6(60%) の確率で予測したときの 交差エントロピー誤差 を計算してください。
問題2-2
「これは犬じゃないかも…」と、AIが自信なく 0.1(10%) の確率で予測してしまったときの 交差エントロピー誤差 を計算してください。
※正解ラベル
数式:

第2問の解答と解説
解答2-1:まあまあ正解の場合
AIの予測は0.6です。正解のラベル
損失

ヒントの値を使うと、

答えは 0.5 です。
解答2-2:大外しした場合
AIの予測は0.1です。実は犬だったのに「犬である確率は10%」と言ってしまった状態ですね。
損失

ヒントの値を使うと、

答えは 2.3 です。
ここがポイント
予測確率が0.6から0.1へと下がると、損失は0.5から2.3へと 4倍以上 に跳ね上がりました。
もしAIが「確率は0.01(1%)」なんて言おうものなら、損失は4.6を超えてさらに急上昇します。
このように交差エントロピー誤差は、「正解を低い確率でしか予測できなかったとき、猛烈に厳しい罰を与える」 という性質があります。
これにより、AIは「正解のラベルには、できるだけ100%に近い高い確率を出さなきゃ!」と必死に学習するようになるわけです。
計算問題のまとめ
お疲れさまでした。
計算自体は単純な四則演算ですが、数字の変化を見ることで、それぞれの「先生(損失関数)」の性格がわかったのではないでしょうか。
- MAE: 淡々と事実(距離)を積み上げる公平な先生。
- MSE: 大きなミスを許さない、大外れに厳しい先生。
- 交差エントロピー: 「自信を持って正解しろ」と、確率の低さに雷を落とす先生。
今後の学習の指針
損失関数によって「間違いの大きさ(ロス)」が計算できることはわかりました。
では、そのロスを減らすためには、具体的にどうやってAIの中身(パラメータ)を修正すればいいのでしょうか。
そこで次に学ぶべきキーワードは 「勾配降下法(こうばいこうかほう)」 です。
損失関数のグラフの「坂道」を下っていくことで、正解への最短ルートを探す手法です。これを知れば、AIが学習する仕組みの全体像が完全に見えるようになりますよ。
セイ・コンサルティング・グループでは新人エンジニア研修のアシスタント講師を募集しています。
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。
最新の投稿
 新人エンジニア研修講師2026年6月19日Spring BootでセッションIDがアドレスバーに表示される理由と対策|新人エンジニア向けにJSESSIONIDを解説
新人エンジニア研修講師2026年6月19日Spring BootでセッションIDがアドレスバーに表示される理由と対策|新人エンジニア向けにJSESSIONIDを解説- 新人エンジニア研修講師2026年6月18日JavaのOptionalでnullを安全に扱う方法|NullPointerExceptionを防ぎ、DAOの戻り値をわかりやすくする
- 新人エンジニア研修講師2026年6月18日ローカルSMTPを使って問い合わせ完了メールを送る方法|新人エンジニア研修向けにSpring BootとJavaMailSenderを解説
- 新人エンジニア研修講師2026年6月18日DevToolsでHTTP通信・エラー・DOMを確認する方法|新人エンジニア向けにブラウザ開発者ツールを解説
