
【初心者向け】情報理論の基礎!「驚き」と「予測」で学ぶエントロピーと相互情報量
 山崎講師
山崎講師こんにちは。ゆうせいです。
エンジニアとして勉強を始めると、「エントロピー」や「情報量」といった言葉に出会うことはありませんか。
数式が出てくると、どうしても難しそうに感じてしまいますよね。
でも、実はこれらは「驚きの度合い」や「予測の難しさ」という日常的な感覚に置き換えると、とてもスムーズに理解できるんです。
今回は、情報理論の入り口となる重要な概念について、数式アレルギーの方でも大丈夫なように、例え話を使って解説していきます。

情報理論ってなに?
情報理論は、情報を効率よく伝えたり、データの中にどれくらいの情報が含まれているかを計算したりするための学問です。
たとえば、スマホで写真を圧縮したり、AIが学習したりするときにも、この理論が基礎になっています。
では、さっそく中身を見ていきましょう。
1. 「驚き」を数値化する:自己情報量
まず最初に知ってほしいのが、自己情報量という言葉です。
これは、ある出来事が起きたときの「驚きの大きさ」を表しています。
ちょっと想像してみてください。
「明日、隕石が落ちてくる」と言われたらどう思いますか。
えっ!とすごく驚きますよね。これは起きる確率がとても低いからです。
逆に、「明日、日が昇る」と言われても、ふーんで終わりますよね。これは当たり前に起きることだからです。
つまり、珍しいこと(確率が低いこと)ほど、情報量(驚き)は大きくなり、ありふれたことほど、情報量は小さくなります。
これを数式で表すと、以下のようになります。

ここで出てくる 

2. 予測のしにくさを表す:エントロピー(平均情報量)
次は、エントロピーです。この言葉、物理などで聞いたことがあるかもしれませんね。
情報理論におけるエントロピーは、「結果がどれくらい予測しにくいか」を表す指標です。
たとえば、コイン投げをイメージしてください。
表と裏が完全に五分五分(50%ずつ)で出るコインがあるとします。
この場合、投げるまで結果が全くわかりませんよね。このとき「エントロピーが高い」と言います。
一方で、もし表が99%出るようなイカサマコインだったらどうでしょうか。
投げる前から「たぶん表だろうな」と予想がつきますよね。この状態は「エントロピーが低い」と言えます。
数式では、それぞれの確率と驚き(自己情報量)を掛け合わせて、合計したものになります。

記号の 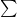
つまり、あらゆる可能性を考慮して、「平均的にどれくらい驚きがあるか(どれくらい予測できないか)」を計算しているのです。
3. 2つの事象の関係性を探る
ここまでは1つの出来事について見てきましたが、実際のエンジニアリングでは「送信したデータ」と「受信したデータ」のように、2つの関係を見ることが多いです。
これを理解するには、2つの円が重なっている「ベン図」をイメージすると分かりやすいですよ。
全体の不確実さ:結合エントロピー
結合エントロピー 


ベン図で言うと、2つの円を合わせた全体の面積(8の字のような形)に相当します。
ノイズの正体:条件付きエントロピー
通信をしていると、ノイズが入ることがありますよね。
条件付きエントロピー 
もし通信が完璧なら、受信データを見れば送信データが完全にわかるので、この値はゼロになります。
つまり、この値が大きければ大きいほど、ノイズが多くて元の情報がわかりにくい状態ということです。
数式では引き算で表せます。

共有された情報:相互情報量
最後に、機械学習などで最も重要なのが相互情報量です。
これは、「片方の情報を知ることで、もう片方のことがどれだけわかったか」を表します。
たとえば、「空が曇っている」という情報を知れば、「雨が降るかもしれない」という予測の精度が上がりますよね。
このように、2つの事象がお互いにどれくらい情報を共有しているかを示すのが相互情報量です。
ベン図で言うと、2つの円が重なっている真ん中の部分になります。

元のわからなさ 
関係性をまとめると、以下の美しい式が成り立ちます。

「元の不確実さ」は、「分かったこと」と「分からなかったこと」の合計である、と考えるとスッキリしますね。
計算問題
情報理論の計算では、「2を何乗したらその数になるか(
これだけ覚えておけば、今日の問題はすべて解けますよ。
(2は、2の1乗)
(4は、2の2乗)
(8は、2の3乗)
(確率は分数なのでマイナスがつきます)

準備はいいですか? それではスタートです!
第1問:驚きの大きさを計算しよう(自己情報量)
まずはウォーミングアップです。
「珍しいことほど情報量が大きい」という自己情報量の計算です。
問題
トランプが4枚あります。そのうち1枚だけが「ジョーカー」で、残りの3枚は普通のカードです。
裏返しにしてシャッフルし、1枚引いたときに「ジョーカー」が出ました。
この事象が持っている「自己情報量(ビット)」はいくつでしょうか?
解答と解説
正解は…… 2ビット です。
順を追って計算してみましょう。
まず、4枚のうち1枚がジョーカーなので、ジョーカーが出る確率 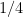
これを自己情報量の公式に当てはめます。

ヒントにある通り、 
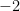
公式にはマイナスがついているので、マイナスとマイナスでプラスになります。

つまり、4回に1回しか起きない珍しい出来事には、「2ビット」分の驚きが含まれているということです。
もしこれが「コインの表(確率1/2)」だったら、驚きは「1ビット」になります。ジョーカーの方が珍しいので、数値が大きくなりましたね。
第2問:天気の予測しにくさは?(エントロピー)
次は、全体的な「予測の難しさ」を表すエントロピー(平均情報量)です。
問題
ある地域の明日の天気を予測します。過去のデータから、天気とその確率は以下のようになっています。
- 晴れ:50% (確率
)
- 雨 :25% (確率
- 曇り:25% (確率
この天予報の「エントロピー(平均情報量)」を求めてください。
解答と解説
正解は…… 1.5ビット です。
エントロピーは、「それぞれの確率 × それぞれの驚き」を全部足し合わせることで求められます。
- 晴れの場合確率は
- 雨の場合確率は
- 曇りの場合雨と同じく確率は
- 全部足す(合計する)



答えは1.5ビットとなります。
もし天気が「100%晴れる」なら、エントロピーは0になります。
逆に、晴れ・雨・曇り・雪が全部25%ずつで、何が起きるか全くわからない場合は、エントロピーは2ビットになります。
今回はその中間くらいの「予測しにくさ」だと言えますね。
第3問:ノイズと情報の関係(相互情報量)
最後は少し応用ですが、前回の「ベン図」を思い出せば引き算だけで解けます。
問題
あなたは友人に電話をかけましたが、電波が悪くノイズが入っています。
あなたが話したい内容(送信データ
しかし、ノイズのせいで相手にはうまく伝わりませんでした。
相手が聞いた内容(受信データ
さて、友人に実際に伝わった情報量(相互情報量 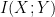
解答と解説
正解は…… 2ビット です。
これは以下の式で考えます。
「実際に伝わった情報」=「元の情報量」-「ノイズで消えてしまった(不明確な)情報量」
数式にするとこうです。

数値を当てはめてみましょう。

とてもシンプルですね。
元の情報量が3ビットあったけれど、1ビット分はノイズでよくわからなくなってしまった。
だから、クリアに伝わったのは残りの2ビット分だけ、ということです。
まとめ
お疲れ様でした。3問とも正解できましたか?
もし間違えてしまっても、解説を読んで「なるほど!」と思えればそれが一番の収穫です。
今回のポイントを整理します。
- 確率は低いほど、情報量(
)は大きくなる。
- エントロピーは、それぞれの情報量の「期待値(平均)」である。
- 相互情報量は、「全体の不確実さ」から「残った不確実さ」を引くことで求められる。
こうして計算してみると、抽象的だった概念が少し現実的な数字として見えてきたのではないでしょうか。
今後の学習の指針
いかがでしたか。
数式だけ見ると難解な情報理論も、「驚き」や「ベン図」でイメージすると、意外と親しみやすいものだと感じてもらえたのではないでしょうか。
ここからさらに学びを深めるなら、次は「クロスエントロピー」や「KLダイバージェンス」といった、機械学習の損失関数として使われる概念に進んでみてください。
Pythonなどのプログラミング言語を使って、実際に確率計算をシミュレーションしてみるのもおすすめです。
まずは、身の回りの「驚き」を探して、これは情報量が大きそうだな、と考えてみることから始めてみましょう。
ぜひ、新しい視点で世界を見てみてくださいね。
それでは、また次の記事でお会いしましょう。
セイ・コンサルティング・グループでは新人エンジニア研修のアシスタント講師を募集しています。
投稿者プロフィール


