【初心者向け】物体検出のデータセット入門!VOCやCOCOの特徴と選び方をわかりやすく解説
 山崎講師
山崎講師こんにちは。ゆうせいです。
新人エンジニアのみなさん、日々の学習お疲れ様です。機械学習やAI開発の世界に足を踏み入れると、最初にぶつかる壁のひとつが「データセット」ではないでしょうか。
「VOCってなに?」「COCOっておいしいの?」「とにかくデータ量が多ければいいんでしょ?」
そんなふうに思っていませんか?実は、データセットにはそれぞれ個性があり、得意なことと苦手なことがあります。これを知らずに適当に選んでしまうと、せっかくのAIモデルも実力を発揮できません。
今日は、AI開発の現場でよく使われる代表的なデータセットについて、クイズ形式の事例をもとに、その特徴や注意点を一緒に学んでいきましょう。高校生の数学レベルがあれば十分に理解できるように解説しますので、安心してくださいね。
そもそもデータセットってなに?
AIにとってのデータセットは、人間でいうところの「教科書」や「問題集」です。
例えば、AIに「猫」を教えたいとき、猫の写真だけを見せても不十分です。「この写真の、ここからここまでが猫だよ」という正解の情報(アノテーションといいます)をセットにして教える必要があります。
この正解情報の書き方や、含まれている画像の種類が、データセットごとに全く異なるのです。では、具体的な事例を見ながら、その違いを解き明かしていきましょう。
事例1:PASCAL VOCデータの座標形式
まず最初は、物体検出の歴史を作ったとも言える「PASCAL VOC(パスカル・ボック)」というデータセットについてです。
みなさんは、画像の中にある物体の場所を数字で表すとき、どうやって伝えますか?
- 「画像の中心から、幅と高さはこれくらい」と伝える
- 「画像の左上の角と、右下の角はここ」と伝える
実は、PASCAL VOC(VOC12など)では、2番目の方法が採用されています。
VOC形式の座標の仕組み
VOC形式では、物体を囲む四角形(バウンディングボックス)の位置を、以下の2つの点の座標で記録しています。
- 左上の座標
- 右下の座標


一方で、YOLO(ヨーロー)という有名なAIモデルや、別のデータセットでは、1番目の「中心座標 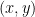

ここがポイント
もしあなたが「VOC形式のデータを使って、YOLOで学習させたい」と思ったとします。このとき、データの形式が違うのでそのままでは使えません。
左上の座標 
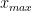


- 中心座標

このように、使いたいデータセットが「どの形式で座標を持っているか」を確認することは、エンジニアとしての第一歩ですよ。
事例2:フリマアプリの画像認識とCOCOデータセット
次は、実際の開発現場でありそうなシチュエーションです。
「フリマアプリに出品された商品画像をAIで自動認識させたい!よし、有名なCOCO(ココ)データセットで学習させれば完璧だ!」
これ、実はうまくいかない可能性が高いんです。なぜだかわかりますか?
COCOデータセットの得意・不得意
COCO(Common Objects in Context)は、非常に有名なデータセットです。中には、人、車、犬、椅子、バナナなど、日常生活でよく見る80種類の一般的な物体が含まれています。
しかし、フリマアプリに出品されるものを想像してみてください。
- 特定のブランドの限定バッグ
- 最新のコスメ用品
- 手作りのアクセサリー
- マイナーな漫画の全巻セット
これらは、COCOが知っている「一般的なカバン」や「本」とは見た目の特徴が異なる場合が多いですし、そもそもCOCOの80種類の中に「特定のブランド品」というカテゴリはありません。
ドメイン(領域)の違い
専門用語でいうと「ドメインが異なる」といいます。
- メリットCOCOはデータが綺麗で、物体検出の基礎力をつけるための事前学習(転移学習の最初の重み)としては非常に優秀です。
- デメリット特定の専門分野(フリマの商品、工場の部品、医療画像など)を直接認識させたい場合、COCOだけで学習しても精度は上がりません。
結局、フリマアプリ専用のAIを作りたいなら、フリマアプリの画像を集めて、自分たちで正解ラベルを作って学習させる(ファインチューニングする)必要があるのです。
事例3:ImageNetとインスタンスセグメンテーション
続いては「ILSVRC(ImageNet)」という巨大なデータセットについてです。
「ImageNetは世界最大級の画像データセットだから、これを使えば物体の形をピクセル単位で切り抜く(インスタンスセグメンテーション)学習もできるよね?」
残念ながら、これは誤りです。
「場所」と「形」は違う
AIのタスクにはレベルがあります。
- 画像分類(Classification): この画像には何が写っている?(例:猫)
- 物体検出(Detection): その猫はどこにいる?(四角い枠で囲む)
- インスタンスセグメンテーション: その猫の形は?(画素単位で塗りつぶす)
ImageNet(ILSVRC)は、主に1番の「画像分類」と2番の「物体検出」のために作られたデータセットです。四角い枠の情報は持っていますが、猫の耳の形や尻尾の曲線に沿った「塗り絵のマスク情報」は持っていません。
道具選びを間違えないために
もし、あなたが「背景を綺麗に切り抜きたい」といったセグメンテーションの仕事をしたいなら、ImageNetではなく、マスク情報を持っている「COCOデータセット」などを選ぶ必要があります。
「大は小を兼ねる」とは言いますが、データセットに関しては「持っていない情報は学べない」ということを覚えておきましょう。
事例4:Open Imagesとクラス数の罠
最後は「データセットは大きければ大きいほどいいのか?」という問題です。
「Open Images(OICID18など)は500種類以上の物体クラスを持っている巨大データセットだ。クラス数が少ないデータより、常にこっちを使ったほうが賢いAIになるはずだ!」
これ、実はエンジニアが陥りやすい罠なんです。
「常に」正しいとは限らない
例えば、あなたが「道路上の歩行者と車だけを見つけるAI」を作りたいとします。このとき、500クラスもある巨大なデータセットを使うとどうなるでしょうか?
そのデータセットには、以下のような今回の目的には不要な画像も大量に含まれているはずです。
- キッチンにあるトースター
- 動物園のキリン
- 海を泳ぐイルカ
ノイズと無駄遣い
不要なデータが多すぎると、以下のようなデメリットが発生します。
- 学習時間の無駄: 不要な画像を処理するために、高価なGPUと時間を浪費します。
- 精度の低下: AIが「車」を覚えようとしているのに、「トースター」の特徴が邪魔をして、学習がスムーズに進まないことがあります(クラス間の不均衡問題など)。
「常にクラス数が多いほうが良い」わけではありません。目的に対して「必要十分なデータ」を選ぶことこそが、優秀なエンジニアの腕の見せ所です。
今後の学習の指針
いかがでしたか?
データセットは単なる「画像の集まり」ではなく、それぞれに設計思想や役割があることがわかっていただけたでしょうか。
- VOC は、座標が「左上と右下」で定義されている。
- COCO は、日常的な物体には強いが、専門的な商品にはそのままでは使えない。
- ImageNet は、分類は得意だが、形の切り抜き(セグメンテーション)の情報は持っていない。
- クラス数 は、多ければいいわけではなく、目的に合ったものを選ぶ必要がある。
これから物体検出を学ぶ皆さんに、私から次のステップを提案します。
「実際にPASCAL VOCやCOCOのデータセットを少量だけダウンロードして、中身のテキストファイル(アノテーション)を自分の目で見てみましょう」
プログラムを書く前に、データそのものを眺めてみる。遠回りのようで、これがデータセットを理解する一番の近道です。
応援しています!一緒に頑張りましょう。

セイ・コンサルティング・グループでは新人エンジニア研修のアシスタント講師を募集しています。
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。
最新の投稿
 山崎講師2026年8月2日指数と対数は何が違うのか:逆の関係を理解する
山崎講師2026年8月2日指数と対数は何が違うのか:逆の関係を理解する- 山崎講師2026年8月2日自然対数eはどこから生まれたのか:歴史から理解する定数の意味
- 山崎講師2026年8月2日片側検定と両側検定の使い分け方を具体例から学ぶ
- 山崎講師2026年8月1日コンピューターが数値計算の誤差に対処する仕組みと精度管理の方法