「識別モデル」と「識別関数」って同じじゃないの?新人エンジニアがハマる罠を解説
 山崎講師
山崎講師こんにちは。ゆうせいです。
機械学習の勉強を始めると、似たような言葉がたくさん出てきて混乱しませんか?
特に「識別モデル(Discriminative Model)」と「識別関数(Discriminant Function)」。
「どっちもデータを分類するやつでしょ?」
「名前が違うだけで中身は一緒なんじゃないの?」
もしそう思っていたとしても、無理はありません。実際、現場でも文脈によっては混同して使われることがあるくらい、この二つは密接に関わっているからです。
でも、エンジニアとして正確な設計をするためには、この二つの「階層の違い」を理解しておくことが非常に大切です。
今日は、このややこしい二つの違いを、数式アレルギーの方でもわかるように、スッキリと整理して解説します。
1. 識別関数とは?=「白黒つける境界線」
まずは「識別関数」から見ていきましょう。
これは一言で言うと、「データをスパッと分けるための具体的な計算式」のことです。
イメージとしては、グラウンドに引かれた「ライン(白線)」を想像してください。
ボールがラインの右側にあれば「Aチームの陣地」、左側にあれば「Bチームの陣地」。
このように、入力されたデータ(ボールの位置)に対して、計算を行い、その結果の「プラスかマイナスか」だけでクラスを判定する道具です。
数式でイメージすると
もっとも単純な識別関数は、中学校で習った一次関数のような形をしています。
この式にデータ を入れたとき、
- 計算結果が プラス なら 「クラスA」
- 計算結果が マイナス なら 「クラスB」
と判定します。
識別関数の役割はこれだけです。「どっちのクラスか」という結果だけを返します。「たぶんAだと思う…」といった曖昧さは持ちません。
ポイント:
識別関数は、あくまで「境界線を引くための式(ツール)」です。
2. 識別モデルとは?=「確率を考える戦略家」
次に「識別モデル」です。
こちらは、関数というよりも「アプローチ(考え方)の枠組み」に近い言葉です。
識別モデルは、データ が与えられたとき、「それがクラス に属する確率はどれくらいか?」という事後確率を直接求めようとするモデルのことを指します。
数式風に書くと、 ( という条件のもとでの の確率)をモデリングするものです。
具体的な違い
識別関数が「右か、左か!」と断定するのに対し、識別モデル(特に確率的識別モデル)はこう言います。
「このデータは、80%の確率でクラスAだけど、20%の確率でクラスBかもしれないね」
このように、白黒つけるだけでなく、「どれくらい自信があるか(確信度)」まで扱えるのが、識別モデルの大きな特徴です(※ただし、確率を出さない識別モデルもあります)。
ポイント:
識別モデルは、「データと正解の関係性」を学習するためのシステムの総称です。
3. 二つの関係性は?
ここまでの説明で、「なんとなく違うのはわかったけど、関係性がよくわからない」と思いませんでしたか?
実は、この二つは対立するものではなく、「包含関係」や「構成要素」の関係にあります。
わかりやすく言うと、「識別モデルという大きなロボットの中に、識別関数というパーツが組み込まれている」と考えると良いでしょう。
- 識別モデル(ロボット): 「この画像を猫かどうか判定しよう」という目的を持ち、データから確率やルールを学習するシステム全体。
- 識別関数(パーツ): そのモデルの中で、実際に「ここから先は猫、こっちは犬」と線を引く計算処理の部分。
例えば、「ロジスティック回帰」という有名な手法があります。これは「識別モデル」の一種です。
このモデルは確率を計算しますが、最終的に「確率が50%以上ならA、それ以下ならB」と判断するとき、内部で「識別関数」の考え方を使って境界線を引いているのです。
メリットとデメリットで比較
それぞれの特徴を整理してみましょう。
識別関数(境界線を引くことだけに特化した場合)
- メリット: 計算がシンプルで高速。学習も比較的簡単。
- デメリット: 「どれくらい自信があるか」という確率が出ないため、際どい判定の信頼性がわからない。
識別モデル(確率を考慮する場合)
- メリット: 「80%の確率で正解」といった予測ができるため、リスク管理(間違いが許されない場面での判断保留など)に使える。
- デメリット: 確率分布を推定するため、計算が少し複雑になる場合がある。
今後の学習の指針
いかがでしたか。
- 識別関数 = データを分けるための「具体的な計算式(境界線)」
- 識別モデル = 入力からクラスを予測するための「システム全体の枠組み」
ざっくりと、このように覚えておけば現場での会話で困ることはありません。
皆さんがこれから学ぶ「ディープラーニング」も、基本的には巨大で複雑な識別関数を、大量のデータを使って作り上げる識別モデルの一種と言えます。
次は、識別モデルの対抗馬としてよく比較される「生成モデル」について学んでみると、AIの世界地図がよりハッキリと見えてくるはずです。
一つずつ、言葉の霧を晴らしていきましょう!
次のステップ
今回登場した「識別関数」の具体例として、最もシンプルで歴史のある「パーセプトロン」というアルゴリズムがあります。
このパーセプトロンがどのように「線を引く」のか、簡単なPythonコードで紹介します。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Perceptron
from sklearn.datasets import make_blobs
# 1. データの作成
# 2つのグループ(クラス)に分かれたデータを50個生成します
X, y = make_blobs(n_samples=50, centers=2, random_state=42)
# 2. パーセプトロン(識別モデル)の学習
# ここでAIがデータを分類するための「直線の引き方」を学習します
clf = Perceptron(max_iter=100, random_state=42)
clf.fit(X, y)
# 3. 学習した「識別関数」の情報を取得
# 識別関数 f(x) = w1*x + w2*y + b = 0 のパラメータを取り出します
w = clf.coef_[0] # 重み(線の傾きに関係)
b = clf.intercept_[0] # バイアス(線の位置に関係)
# 4. 境界線(識別関数)の描画準備
# グラフの端から端まで線を引くための計算です
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x_values = np.linspace(x_min, x_max, 100)
# 式を変形して y = ... の形にします
# w0 * x + w1 * y + b = 0 => y = -(w0 * x + b) / w1
y_values = -(w[0] * x_values + b) / w[1]
# 5. グラフの描画
plt.figure(figsize=(8, 6))
# データの点をプロット(グループごとに色分け)
plt.scatter(X[y == 0][:, 0], X[y == 0][:, 1], color='red', label='Class A')
plt.scatter(X[y == 1][:, 0], X[y == 1][:, 1], color='blue', label='Class B')
# 識別関数(境界線)をプロット
plt.plot(x_values, y_values, 'k--', linewidth=2, label='Discriminant Function')
# グラフの装飾
plt.title('Perceptron Decision Boundary')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.legend()
plt.grid(True)
# 表示
plt.show()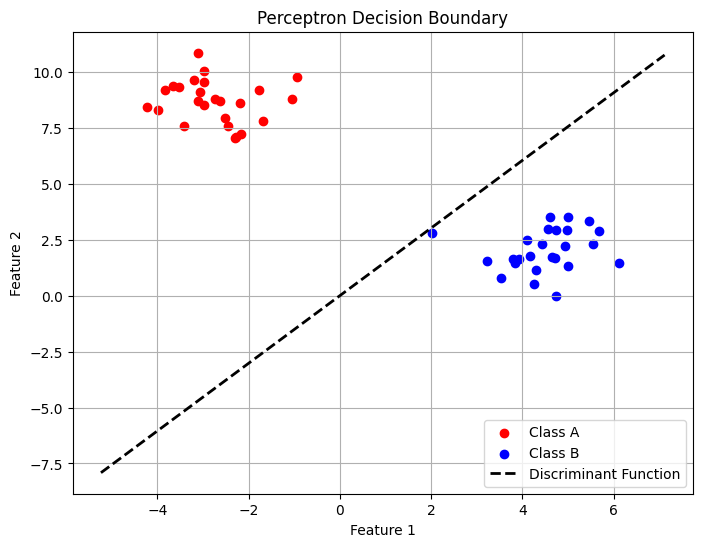
セイ・コンサルティング・グループの新人エンジニア研修のメニューへのリンク
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。