
データ解析の救世主!主成分分析とt-SNEの違いを世界一わかりやすく解説
 山崎講師
山崎講師こんにちは。ゆうせいです。
データの海に溺れそうになったことはありませんか?現代は情報の時代ですが、あまりにも項目(変数)が多いと、人間には何が起きているのかさっぱり見えなくなってしまいます。
例えば、100科目のテスト結果を渡されて、その生徒の個性を瞬時に見抜けと言われても困りますよね。そんな時、複雑なデータをギュッと凝縮して、私たちの目に見える形にしてくれる魔法のような技術があります。
それが、今回ご紹介する主成分分析とt-SNEです。読み方から仕組み、使い分けまで、初心者の方に向けて丁寧にお話ししていきますね。
まずは読み方と正体を知りましょう
まずは基本の「キ」として、名前の呼び方から確認しておきましょう。
主成分分析(PCA)
読み方は、しゅせいぶんぶんせき、です。英語では Principal Component Analysis と呼ばれるため、頭文字を取って ピーシーエー と呼ぶのが一般的です。
t-SNE
こちらは、ティー・スニー と読みます。t-distributed Stochastic Neighbor Embedding の略ですが、現場で正式名称を言う人はほとんどいません。みんな親しみを込めて「ティースニー」と呼んでいます。
さて、この2つの技術を一言で表すと次元圧縮です。次元とは、データの項目の数のこと。100個ある項目を、2個や3個に減らしてグラフに描けるようにするのが次元圧縮の役割です。
あなたは、複雑な迷路をドローンで上空から見下ろしたことはありますか?次元圧縮は、まさにそのドローンの視点を与えてくれる道具なのです。
情報を要約する主成分分析(PCA)
主成分分析は、いわばベテランの編集者です。大量の原稿から、大事なポイントだけを抽出して要約を作るのが得意です。
この手法では、主成分 という概念を使います。
仕組みを例え話で理解する
例えば、ある学級の身体測定データ(身長、体重、座高、足のサイズ)があるとします。これらをまとめて、その子の体の大きさを表す新しい指標を作るとしたらどうでしょうか。
主成分分析は、身長や体重といったバラバラの数字を組み合わせて、最もデータの違い(分散)がはっきりと現れる方向を見つけ出します。
第1主成分 = 身長 
といった計算を行い、データの個性を一番よく表す物差しを新しく作り出すのです。
メリット
- 計算が非常に速く、大きなデータでもサクサク動きます。
- 結果の解釈がしやすいです。どの項目が結果に影響を与えたかが明確にわかります。
デメリット
- 直線的な関係しか捉えられません。複雑に絡み合ったデータだと、うまく特徴を掴めないことがあります。
似たもの同士を集めるt-SNE
一方で、t-SNEはパーティーの幹事のような役割を果たします。
主成分分析が全体の要約を作るのに対し、t-SNEは似ている人同士を近くに、似ていない人を遠くに配置し直すことに全力を注ぎます。
仕組みを例え話で理解する
たくさんの写真データがあると想像してください。犬、猫、車、飛行機の写真がバラバラに混ざっています。t-SNEは、1枚ずつの写真を見て、「この写真とこの写真は似ているな」という近所付き合いの関係を調べます。
そして、その関係性を保ったまま、2次元の地図上にプロットします。すると、不思議なことに、犬のグループ、猫のグループといった塊(クラスタ)が綺麗に浮かび上がってくるのです。
メリット
- 人間には見えない複雑で非線形な構造を、見事に可視化してくれます。
- データの塊がはっきりと分かれるため、直感的に理解しやすい図になります。
デメリット
- 計算に時間がかかります。
- 実行するたびに結果の形が少しずつ変わることがあります。
- 図の中の距離そのものに、数学的な厳密な意味がない場合があります。
結局、どっちを使えばいいの?
迷った時は、以下の基準で選んでみてください。
| 項目 | 主成分分析(PCA) | t-SNE |
| 目的 | データの全体像を要約する | 似たもの同士の集まりを見つける |
| 得意なこと | 大まかな傾向の把握 | 綺麗なグループ分けの可視化 |
| 計算速度 | 速い | 遅い |
| 変化 | 常に同じ結果が出る | 毎回少し形が変わる |
基本的には、まず主成分分析を試してデータの全体を確認し、もっと詳細にグループ分けを見たい場合にt-SNEを使う、という二段構えが王道ですよ!
実際にPython(パイソン)のコードを動かして、主成分分析とt-SNEの結果がどう違うのかを見てみましょう!
今回は、データサイエンスの世界で最も有名な「アヤメのデータセット(Iris)」を使います。アヤメという花の種類を、ガクの長さや幅など4つの項目で分類したデータです。これを2次元にギュッと圧縮して、画面に表示させてみますね。
事前準備:ライブラリの読み込み
まずは、計算やグラフ作成に必要な道具を揃えます。
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.decomposition import PCA
from sklearn.manifold import TSNE
# アヤメのデータを読み込みます
iris = datasets.load_iris()
X = iris.data
y = iris.target主成分分析(PCA)でデータを要約する
主成分分析は、データの散らばりが最も大きい方向を見つけるのが得意でしたね。
# PCAモデルを作ります。2次元に圧縮したいので n_components は 2 です
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
# グラフに描画します
plt.figure(figsize=(8, 6))
for i, name in enumerate(iris.target_names):
plt.scatter(X_pca[y == i, 0], X_pca[y == i, 1], label=name)
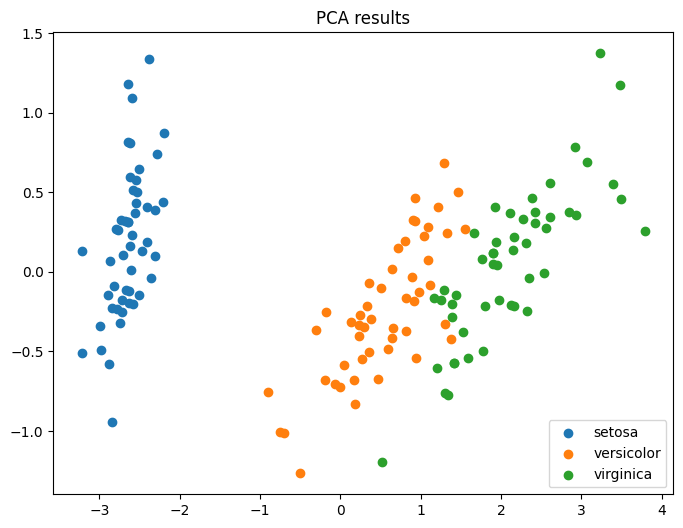
plt.title("PCA results")
plt.legend()
plt.show()主成分分析の結果はどう見えるでしょうか?データ全体がふわっと広がっていて、それぞれのグループがどこに位置しているのか、全体の位置関係がよく分かりますね。
t-SNEで似たもの同士を固める
次に、t-SNEを使ってみましょう。こちらは「近所付き合い」を重視する手法です。
# t-SNEモデルを作ります
tsne = TSNE(n_components=2, random_state=0)
X_tsne = tsne.fit_transform(X)
# グラフに描画します
plt.figure(figsize=(8, 6))
for i, name in enumerate(iris.target_names):
plt.scatter(X_tsne[y == i, 0], X_tsne[y == i, 1], label=name)
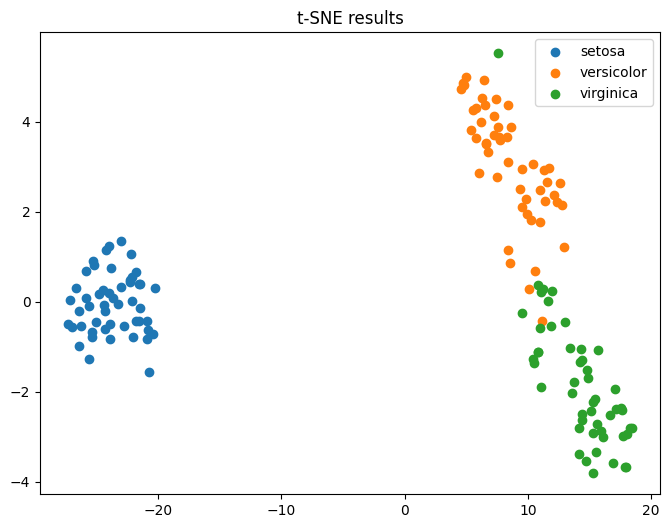
plt.title("t-SNE results")
plt.legend()
plt.show()
主成分分析の図と見比べてみてください。t-SNEの方が、グループごとに「島」のように固まって分かれて見えませんか?似ているもの同士を近くに集める力が強いため、このようにハッキリとした塊になりやすいのが特徴です。
コードを理解するためのポイント
ここで、数式的な処理がどのように行われているか、少しだけ覗いてみましょう。
主成分分析では、新しい軸を作るときに次のような計算が行われています。
第1主成分の値 = 変数1
これに対してt-SNEは、データ点同士の「近さ」を確率として計算します。
データ点1と2の近さ =

難しい記号が出てきましたが、今は「近くにあるものほど大きなスコアを与える仕組みなんだな」と理解しておけば十分です!
まとめとアドバイス
2つのコードを実行してみると、同じデータでも「切り取り方」によって見え方が全く違うことに気づくはずです。
- PCAは「全体のバランス」を保ちながら要約する
- t-SNEは「似ているもの同士の絆」を強調して可視化する
どちらが正解ということはありません。大切なのは、両方を試してみて「このデータはどんな形をしているんだろう?」と観察する姿勢です。
t-SNEを使いこなす上で一番の鍵となるのが、パープレキシティ(Perplexity)という設定です。これは直訳すると「困惑度」という意味ですが、データ解析の世界では「一つのデータ点に対して、何人くらいの近所付き合いを考慮するか」という目安を指します。
この値を変えるだけで、データの見え方が魔法のように変わってしまうのです。実際にPythonコードで比較してみましょう!
パープレキシティを変えて実験!
同じアヤメのデータを使って、パープレキシティの値を 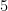
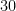
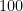
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.manifold import TSNE
# データの準備
iris = datasets.load_iris()
X, y = iris.data, iris.target
# 3パターンの設定でグラフを並べて表示します
perplexities = [5, 30, 100]
plt.figure(figsize=(15, 5))
for i, p in enumerate(perplexities):
tsne = TSNE(n_components=2, perplexity=p, random_state=0)
X_tsne = tsne.fit_transform(X)
plt.subplot(1, 3, i + 1)
for j, name in enumerate(iris.target_names):
plt.scatter(X_tsne[y == j, 0], X_tsne[y == j, 1], label=name)
plt.title(f'Perplexity = {p}')
plt.show()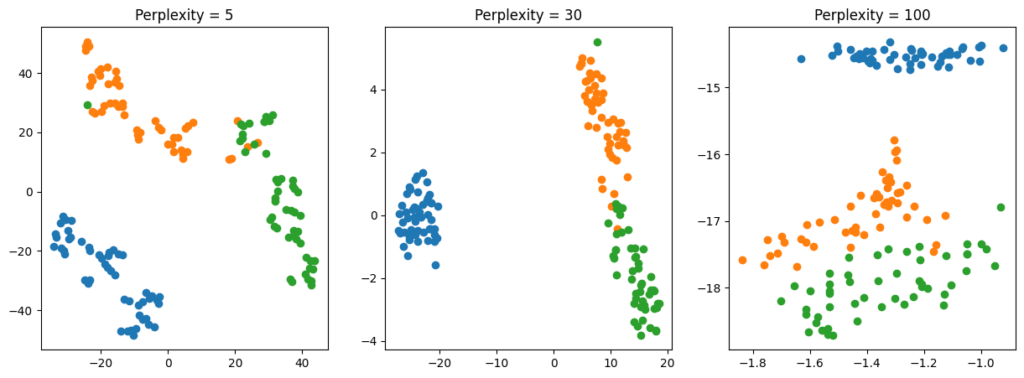
結果からわかること
グラフをよく見てみると、値によって形が全然違いますよね。
パープレキシティが小さい場合(例:5)
ごく少数の近所の人しか見ないので、データがバラバラの小さな塊になりやすいです。細かい構造は見えますが、全体としてどう集まっているのかが分かりにくくなることがあります。
パープレキシティが標準的な場合(例:30)
多くの教科書で推奨される設定です。ほどよくグループがまとまり、アヤメの種類ごとの違いが綺麗に浮かび上がります。
パープレキシティが大きい場合(例:100)
クラス全員を近所の人として扱うような状態です。全体を一つの大きな塊として捉えようとするため、せっかくのグループ分けが潰れて、主成分分析(PCA)の結果に似たような丸い形に近づいていきます。
メリットとデメリットの整理
この設定をいじることで、私たちはデータを多角的に観察できます。
メリット
- データの密度や隠れた構造に合わせて、最適な見え方を探ることができます。
- 小さな値にすることで、ノイズの中に隠れた極小のグループを発見できるかもしれません。
デメリット
- 適切な値はデータの数によって変わるため、正解が一つではありません。
- 値が大きすぎると計算量が増え、処理に時間がかかるようになります。
データ解析の練習台として世界中で愛されている「MNIST(エムニスト)」というデータセットを使ってみましょう。
これは、人間が手書きした 
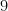

MNISTをt-SNEで可視化するコード
MNISTはデータ量が非常に多いため、今回は計算時間を短縮するために最初の 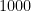
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.manifold import TSNE
# 手書き数字データを読み込みます
digits = datasets.load_digits()
X, y = digits.data, digits.target
# t-SNEを実行します。perplexityは30に設定してみましょう
tsne = TSNE(n_components=2, perplexity=30, random_state=42)
X_tsne = tsne.fit_transform(X)
# グラフに描画します
plt.figure(figsize=(10, 8))
scatter = plt.scatter(X_tsne[:, 0], X_tsne[:, 1], c=y, cmap='jet', alpha=0.6)
plt.colorbar(scatter)
plt.title('t-SNE visualization of MNIST (Digits)')
plt.show()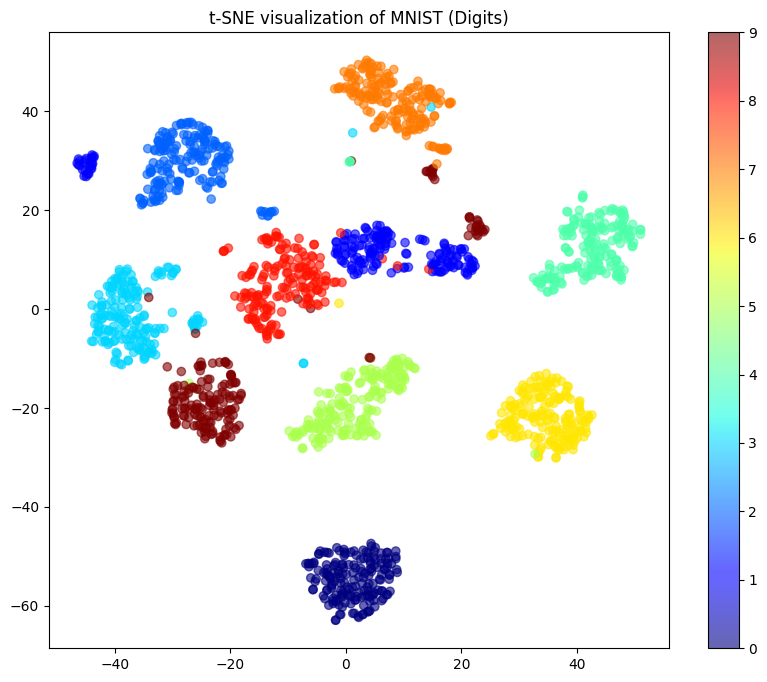
このグラフから何がわかる?
実行結果を見ると、虹色に彩られた綺麗な「島」がたくさん現れたはずです。それぞれの島は、一つの数字に対応しています。
専門用語の解説:高次元データ
画像データは、1ピクセル(点)ごとの明るさが一つの項目になります。MNISTの場合、縦 

これを高校生に例えるなら、784科目もある超ハードな中間試験の結果表のようなものです。t-SNEは、その膨大な成績表から「この子たちは文系」「この子たちは体育会系」といった個性を瞬時に見抜き、グループごとに席替えをしてくれたような状態です。
メリット
- 数字の「似ている度合い」が視覚的にわかります。
- 例えば、
と
の島が近くにあったら、「機械もこの2つを見分けるのは苦労しているんだな」といった洞察が得られます。
デメリット
- データが
枚、
枚と増えていくと、計算にかかる時間が雪だるま式に増えてしまいます。
- 遠く離れた島同士の距離感にはあまり意味がないので、「
今後の学習の指針
主成分分析とt-SNEの違い、イメージできましたか?
データ解析の世界は、自分で手を動かして図が出てきた瞬間が一番楽しいものです。ぜひ、恐れずに挑戦してみてくださいね。
セイ・コンサルティング・グループでは新人エンジニア研修のアシスタント講師を募集しています。
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。
最新の投稿
 新人エンジニア研修講師2026年6月22日ソリューション営業と御用聞き営業の違い|IT営業担当者が提案型営業へ成長するための考え方
新人エンジニア研修講師2026年6月22日ソリューション営業と御用聞き営業の違い|IT営業担当者が提案型営業へ成長するための考え方- 新人エンジニア研修講師2026年6月22日ITソリューション営業でよくある反論への対応方法|お金・時期・権限・必要性・不安を商談につなげる考え方
- 新人エンジニア研修講師2026年6月19日Spring BootでセッションIDがアドレスバーに表示される理由と対策|新人エンジニア向けにJSESSIONIDを解説
- 新人エンジニア研修講師2026年6月18日JavaのOptionalでnullを安全に扱う方法|NullPointerExceptionを防ぎ、DAOの戻り値をわかりやすくする
