
データ分析の魔法使い!K-means法の進化系バリエーションを徹底解説
 山崎講師
山崎講師こんにちは。ゆうせいです。
皆さんは、大量のデータを目の前にして「これを似たもの同士でグループ分けしたいな」と思ったことはありませんか?そんなときに活躍するのがK-means法というアルゴリズムです。
しかし、基本のやり方だけでは解決できない弱点もいくつか存在します。今回の研修では、その弱点を克服するために生まれた進化系の手法について、皆さんに分かりやすくお伝えしますね。準備はいいですか?
そもそもK-means法のおさらいをしましょう
まずは基本を確認しましょう。K-means法は、データを指定した数(K個)のグループに分ける手法です。
例えば、100人の生徒をテストの点数に基づいて3つのクラスに分けるとします。まず適当に3つの中心点を決め、それぞれの生徒が一番近い中心点のグループに所属します。次に、グループ内の生徒の平均点を出して新しい中心点を決め、また所属をやり直す。
この作業を繰り返して、グループが動かなくなったら完成です!
この「平均」という考え方が非常に重要です。数学的には、各点と中心の距離の二乗和を最小にすることを目指します。
距離 =

この式は、それぞれのデータと中心のズレを計算しているだけなので怖がらないでくださいね。
初期値の運ゲーを終わらせるK-means++
基本のK-means法には大きな弱点があります。それは、最初に決める中心点が「たまたま近くに集まってしまう」と、おかしなグループ分けのまま終わってしまうことです。これを初期値依存性と呼びます。
これを解決するのが、K-means++です!
K-means++は、最初の中心点を選ぶときに、できるだけお互いが離れるように選ぶ工夫をします。
- 最初の1点をランダムに選ぶ。
- 2点目以降は、すでに選ばれた点から遠い場所にあるデータほど選ばれやすくする。
このように「最初はバラバラに始めようぜ!」とルールを決めるだけで、計算のスピードも精度も劇的に向上します。
外れ値に負けないK-medoids法
次に紹介するのはK-medoids法です。
K-means法はグループの「平均値」を計算の軸にします。しかし、平均値には「極端なデータ(外れ値)」に引っ張られやすいという性質があります。
例えば、年収のグループ分けをしているときに、一人だけ年収100億円の人が混ざっていたらどうなるでしょうか?平均値は一気に跳ね上がり、普通の感覚とはかけ離れたグループ分けになってしまいますよね。
そこでK-medoids法では、平均ではなく「グループの中に実際に存在するデータ」を代表者に選びます。
イメージとしては、クラスの代表を決めるときに「全員の身長の平均値(実在しない数値)」を代表にするのがK-means法で、「クラスの中で一番真ん中に近い実在する生徒」を代表にするのがK-medoids法です。
実在するデータを軸にするので、変なデータが紛れ込んでもビクともしません!
計算をサボってスピードアップ!Mini Batch K-means
データが数百万件、数億件と巨大になったらどうすればいいでしょうか?真面目に全てのデータを毎回計算していたら、日が暮れてしまいます。
そこで登場するのがMini Batch K-meansです。
これは、全てのデータを一度に使うのではなく、ランダムに抜き出した少量のデータ(ミニバッチ)だけで中心点を更新していく手法です。
メリットとデメリットを整理してみましょう。
| 項目 | メリット | デメリット |
| Mini Batch K-means | 計算が圧倒的に速い。メモリを節約できる。 | 精度が基本のK-meansより少しだけ落ちることがある。 |
「大体の傾向が分かればいいから、とにかく速く結果が欲しい!」というビジネスの現場では非常に重宝される手法ですよ。
それぞれの手法の使い分けガイド
結局どれを使えばいいの?と迷ってしまいますよね。そんなときは以下の指針を参考にしてください。
- まずはK-means++を試す。これが現代のスタンダードです。
- データの中に明らかに異常な値(外れ値)が多いなら、K-medoids法を検討する。
- パソコンが固まるほどデータが重いなら、Mini Batch K-meansで時短する。
皆さんが扱っているデータは、どのタイプに当てはまりそうですか?
Pythonで実装
K-means法のバリエーションを、Pythonを使って実際に目で見える形にしてみましょう!頭で理解するよりも、グラフが動く様子や結果の違いを見るほうがずっと納得感がありますよね。
今回は、標準的なK-means法と、計算を高速化させたMini Batch K-meansの結果を比較するコードを作成しました。
Pythonで動かしてみる準備
データ分析の定番ライブラリである scikit-learn を使います。以下のコードをコピーして、Google Colabやお手元のJupyter Notebookで実行してみてください。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans, MiniBatchKMeans
from sklearn.datasets import make_blobs
import time
# 1. テスト用のデータを作成します(3つの塊があるデータ)
n_samples = 3000
X, y = make_blobs(n_samples=n_samples, centers=3, cluster_std=0.60, random_state=0)
# 2. 通常のK-means法を実行
start_time = time.time()
kmeans = KMeans(n_clusters=3, init='k-means++', n_init=10)
kmeans_labels = kmeans.fit_predict(X)
kmeans_time = time.time() - start_time
# 3. Mini Batch K-meansを実行
start_time = time.time()
mbk = MiniBatchKMeans(n_clusters=3, init='k-means++', batch_size=100, n_init=10)
mbk_labels = mbk.fit_predict(X)
mbk_time = time.time() - start_time
# 4. 結果を可視化します
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
# 通常のK-meansのグラフ
ax1.scatter(X[:, 0], X[:, 1], c=kmeans_labels, s=5, cmap='viridis')
ax1.set_title(f'Standard K-means\nTime: {kmeans_time:.4f}s')
# Mini Batch K-meansのグラフ
ax2.scatter(X[:, 0], X[:, 1], c=mbk_labels, s=5, cmap='viridis')
ax2.set_title(f'Mini Batch K-means\nTime: {mbk_time:.4f}s')
plt.show()
コードのポイントを解説しますね
このプログラムで特に注目してほしい部分がいくつかあります。
データの「種」を作る 
まず最初に、人工的に「似たもの同士の集まり」を作っています。

賢い初期値 
コードの中で
爆速の秘密 
Mini Batch K-meansの方にある
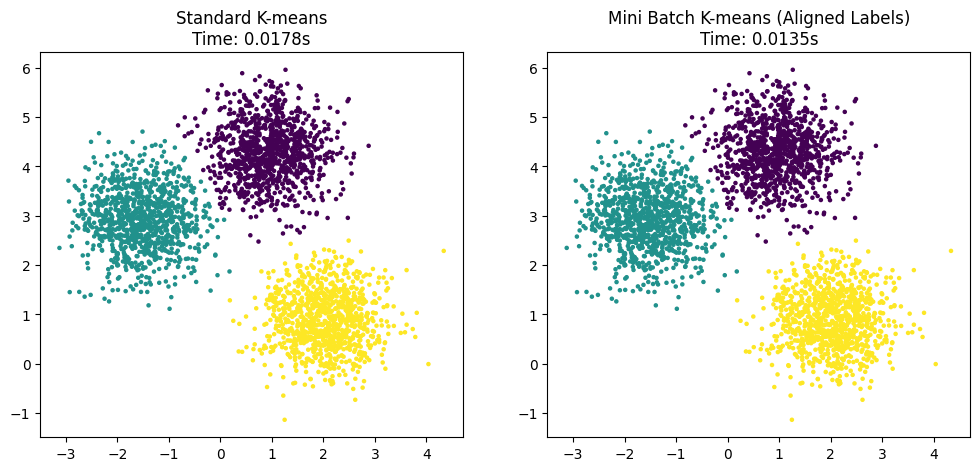
実行結果の Time(処理時間)を見てみてください。Mini Batchの方が圧倒的に速く終わっているはずです!
実際に動かしてみてどう感じましたか?
グラフを見ると、どちらの手法も綺麗に3つのグループに分けられていることが分かりますよね。
「計算をサボっても(ミニバッチを使っても)、これだけ正確に分けられるなら便利だな」と感じていただけたのではないでしょうか。
もし余裕があれば、データの数 
まとめとこれからの学習アドバイス
今回はK-means法のバリエーションについて解説しました。アルゴリズムにはそれぞれ個性があり、完璧なものは一つもありません。状況に合わせて道具を使い分けるのが、データサイエンティストへの第一歩です。
今後は、グループの数(K)をどうやって決めるかという「エルボー法」や「シルエット分析」について調べてみると、より実践的なスキルが身に付きますよ。
まずは身近なデータを、Pythonなどのプログラミング言語を使って実際にグループ分けしてみることから始めてみてください!
次は、グループの形が丸くないときに役立つ「混合ガウスモデル」について一緒に勉強してみませんか?
セイ・コンサルティング・グループでは新人エンジニア研修のアシスタント講師を募集しています。
投稿者プロフィール

