
確率分布のズレを測るものさし!KLダイバージェンスとJSダイバージェンスを徹底解説
 山崎講師
山崎講師こんにちは。ゆうせいです。
あなたは、二つのデータの集まりがどれくらい似ているか、あるいはどれくらい離れているかを数値で表したいと思ったことはありませんか。例えば、昨日の売上予測と実際の売上のズレを計算したり、AIが生成した画像が本物の写真とどれくらい近いかを評価したりする場面です。
機械学習や統計学の世界では、このズレを測るためにダイバージェンスという概念を使います。今回は、その代表格であるKLダイバージェンスと、その進化系であるJSダイバージェンスについて、初心者の方にも分かりやすくお伝えしますね。
ダイバージェンスとは何者か
そもそもダイバージェンスとは、日本語で「散逸」や「相違」を意味する言葉です。二つの確率分布(データの散らばり具合)が、どれだけ食い違っているかを数値化してくれます。
想像してみてください。あなたは弓道の師範です。
お手本となる的の中心(正解の分布)に対して、弟子の矢がどこに集まっているか(予測の分布)を調べます。このとき、師範の狙いと弟子の狙いのズレ具合を数値にしたものがダイバージェンスだと考えてください。
KLダイバージェンス:情報の落とし穴
まずは基本となるKLダイバージェンス(カルバック・ライブラー情報量)を見ていきましょう。
専門用語の解説
KLダイバージェンスとは、ある分布 P を基準にして、別の分布 Q がどれだけ情報を失っているかを測る指標です。
これを理解するために、情報エントロピーという言葉を知っておく必要があります。これは情報の「驚き具合」や「乱雑さ」を表す尺度です。
例えば、毎日必ず晴れる砂漠で「明日は晴れです」と言われても驚きはありませんが、めったに降らない砂漠で「明日は大雨です」と言われたら、その情報の価値(驚き)は非常に大きいですよね。KLダイバージェンスは、この驚きの差を利用してズレを計算します。
KLダイバージェンスの最大の特徴
この指標には、非常にユニークで、かつ注意が必要な性質があります。それは、非対称性です。
分布 P から見た Q の距離と、分布 Q から見た P の距離が一致しないのです。
数式で表すと、ズレの大きさ D は以下のようになります。
D = 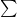

ここで、P と Q を入れ替えると計算結果が変わってしまいます。
メリットとデメリット
- メリット:情報の損失量を厳密に計算できるため、ニューラルネットワークの学習(損失関数)などで非常に強力な武器になります。
- デメリット:距離の概念を満たしていないことです。AからBへの距離とBからAへの距離が違うというのは、日常感覚では少し扱いづらいですよね。また、Q の確率が 0 になる場所で計算が破綻してしまうという弱点もあります。
JSダイバージェンス:バランスの取れた解決策
KLダイバージェンスの「右から見るか左から見るかで結果が違う」というモヤモヤを解決するために登場したのが、JSダイバージェンス(イェンセン・シャノン情報量)です。
専門用語の解説
JSダイバージェンスは、二つの分布 P と Q のちょうど真ん中に、平均的な分布 M を作るところから始まります。
M = ( P + Q )
そして、「P と M のズレ」と「Q と M のズレ」を計算して、その平均をとるのです。
なぜJSダイバージェンスが好まれるのか
一番の理由は、対称性を持っているからです。
P から見ても Q から見ても、計算される距離は同じになります。これでようやく、私たちは地図上の距離を測るのと同じような感覚で分布のズレを扱えるようになります。
また、計算結果が必ず 0 から 1 の間に収まるというのも大きな魅力です。0 であれば完全に一致、1 であれば完全に別物、とはっきり判定できるのは便利だと思いませんか。
メリットとデメリット
- メリット:対称性があり、値が 0 から 1 に制限されるため、比較が非常にスムーズです。分布の一部が 0 であっても計算が破綻しません。
- デメリット:KLダイバージェンスに比べると計算の手間が少し増えます。また、非常に複雑な数学的最適化を行う際には、KLダイバージェンスの方が扱いやすい場面もあります。
二つの違いを比較表でチェック
それぞれの特徴を整理してみましょう。
| 特徴 | KLダイバージェンス | JSダイバージェンス |
| 対称性 | なし( P と Q を入れ替えると値が変わる) | あり(入れ替えても値は同じ) |
| 値の範囲 | 0 から 無限大 | 0 から 1 |
| 計算の破綻 | 確率 0 の地点で不安定になる | 安定している |
| 主な用途 | ディープラーニングの損失関数など | 生成対抗ネットワーク(GAN)の評価など |
あなたが次に進むべき道
ここまで読んで、確率分布のズレを測るイメージが湧いてきたでしょうか。
どちらが優れているかという話ではなく、目的に応じて使い分けることが大切です。
もしあなたがこれからデータサイエンスやAIの学習を深めたいなら、以下のステップで進んでみてください。
- 情報エントロピーの概念をより深く掘り下げてみる
- Pythonなどのプログラミング言語を使って、実際に二つの山形グラフ(正規分布)の距離を計算してみる
- 生成AI(GANなど)の仕組みの中で、JSダイバージェンスがどのように使われているか調べてみる
最初は難しく感じるかもしれませんが、これらは現代のAI技術を支える非常にエキサイティングな理論です。一歩ずつ、楽しみながら学んでいきましょう。
セイ・コンサルティング・グループでは新人エンジニア研修のアシスタント講師を募集しています。
投稿者プロフィール


