
【初心者向け】DBSCANとは?ノイズに強く、形にこだわらない賢いクラスタリング手法!
 山崎講師
山崎講師
こんにちは。ゆうせいです。
はじめに:クラスタリングってなんだろう?
まず「クラスタリング」という言葉からおさらいしましょう。
これは、データを「似ているもの同士でグループ分けすること」です。
たとえば、動物園の動物を見た目や大きさで分けると…
- ライオン、トラ → 「肉食獣クラスタ」
- ゾウ、サイ → 「大型草食動物クラスタ」
- ペンギン、カモ → 「鳥クラスタ」
みたいな感じですね。
クラスタリングにはいくつかの手法がありますが、今回はその中でも DBSCAN(ディービースキャン) という、ちょっと賢いやつを紹介します。
DBSCANって何の略?
DBSCAN は、以下の略です:
Density-Based Spatial Clustering of Applications with Noise
「ノイズのある空間データを密度ベースでクラスタリングする手法」
ちょっとカタそうですが、要するに「点が密集してるところは同じクラスタ、離れてるところは違うクラスタ」という考え方です。
DBSCANの基本コンセプト
DBSCANは、点の“密集度”に注目します。
この密集をどう判断するかに、2つのパラメータを使います:
| パラメータ名 | 意味 |
|---|---|
eps(エプシロン) | 「近い」とみなす距離のしきい値 |
minPts(ミンピーティーエス) | 「この点のまわりに何個以上点があれば密集とみなすか」 |
3つの点の種類
DBSCANは、すべての点を以下の3つに分類します:
- コア点(Core Point)
→epsの距離内にminPts個以上の点がある点。 - 境界点(Border Point)
→ 自分はminPtsに満たないけど、近くにコア点がいる。 - ノイズ点(Noise Point)
→ コア点にも属さないし、近くにコア点もいない。孤立した点。
💡 イメージ図
DBSCANの強み
✅ 1. ノイズに強い
ノイズ点を「無理にどこかのクラスタに入れない」という発想がユニーク!
✅ 2. 形の制限がない
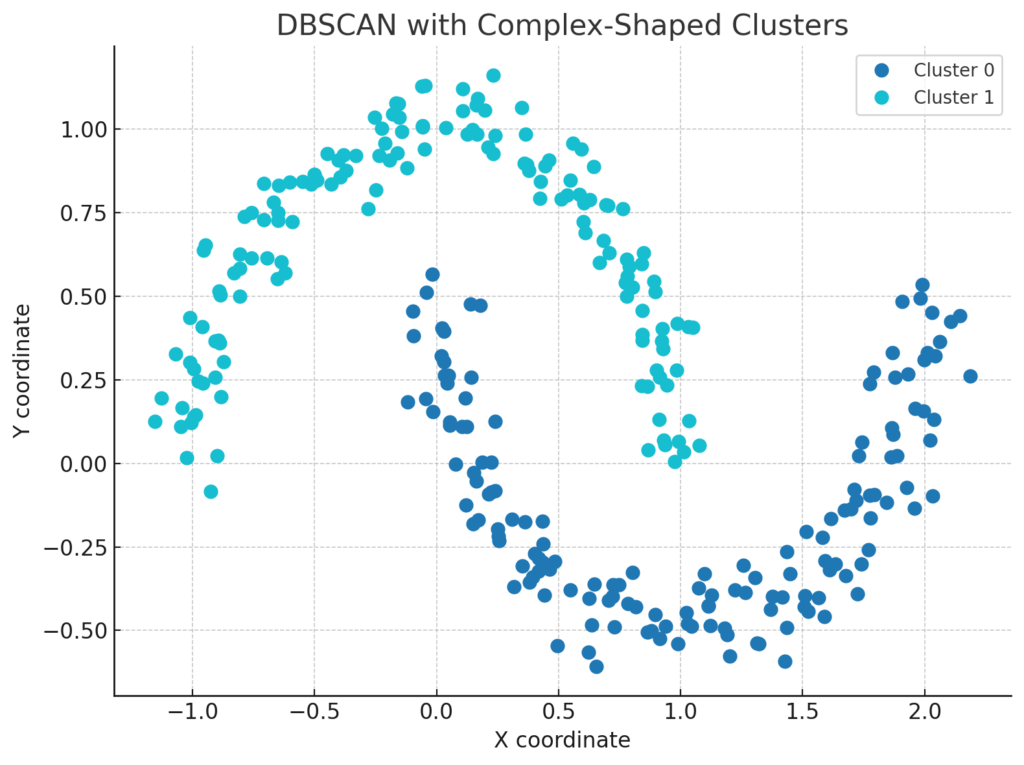
KMeansのように「円形に分ける」必要がない。クネクネした形のクラスタでもOK。
✅ 3. 事前にクラスタ数を決めなくていい
KMeansは「何クラスタに分けるか?」を最初に決めないといけませんが、DBSCANはデータに任せて自然に分けてくれるんです。
ちょっと残念な点(デメリット)
| 弱点 | 説明 |
|---|---|
| epsとminPtsの設定が難しい | パラメータによって結果がガラッと変わります。グラフで調整が必要。 |
| 次元が高すぎると効果が落ちる | これは「次元の呪い」と言われる現象。特に画像やテキストなどのベクトル空間では注意が必要です。 |
Pythonでの使い方(簡単なコード)
from sklearn.cluster import DBSCAN
from sklearn.datasets import make_moons
import matplotlib.pyplot as plt
# テストデータ作成
X, _ = make_moons(n_samples=300, noise=0.05)
# DBSCANでクラスタリング
model = DBSCAN(eps=0.2, min_samples=5)
labels = model.fit_predict(X)
# 結果の可視化
plt.scatter(X[:, 0], X[:, 1], c=labels)
plt.title("DBSCAN Clustering")
plt.show()
まとめ
| 特徴 | 説明 |
|---|---|
| 手法 | 密度ベースのクラスタリング |
| 強み | ノイズに強い、クラスタ数不要、形状の自由度が高い |
| 向いている用途 | 地理データ、センサーデータ、異常検知など |
| 弱点 | パラメータ設定に感度が高く、次元が高すぎると使いにくい |
最後に:あなたの一歩は?
まずは自分の持っているCSVやベクトルデータを使って、scikit-learnでDBSCANを動かしてみましょう!
手を動かすことで、「密度ってこういうことか!」と体感できますよ。
挑戦して、手を動かして、発見する――
それがエンジニアの成長のカタチです!
生成AI研修のおすすめメニュー
投稿者プロフィール


