
【初心者向け】L1正則化とL2正則化とは?〜「過学習を防ぐ魔法のペナルティ」〜
 山崎講師
山崎講師
こんにちは。ゆうせいです。
【初心者向け】L1正則化とL2正則化とは?〜「過学習を防ぐ魔法のペナルティ」〜
はじめに:正則化ってなに?
まず、正則化(せいそくか)とは何か?
ひとことで言えば…
「モデルが複雑になりすぎないようにブレーキをかける仕組み」
機械学習では、データにピッタリすぎるモデル(=過学習)になると、新しいデータに弱くなります。
その過学習を防ぐために、モデルの重み(パラメータ)に“罰金”をかけるのが正則化です。
L1正則化(ラッソ)とは?
🧠 ポイント
- 重みの絶対値の合計にペナルティをかける
- 数式(やさしく):
罰金 = 重み1の絶対値 + 重み2の絶対値 + …

💡 特徴
- いくつかの重みをゼロにする(不要な特徴を消す)
- → 特徴選択にも使える!
🎓 例え話
L1は「断捨離型のペナルティ」です。
「あ、これあんまり効いてないね」と判断された特徴量はスパッと重み0にして捨てる**。
→ モデルがシンプルになります!
L2正則化(リッジ)とは?
🧠 ポイント
- 重みの2乗の合計にペナルティをかける
- 数式(やさしく):
罰金 = 重み1の2乗 + 重み2の2乗 + …

💡 特徴
- 重みをゼロにはしないが、小さく抑える
- なめらかで全体に均等な圧力をかける
🎓 例え話
L2は「節約型のペナルティ」です。
「あんまり派手に重みつけないで、全体的に控えめにしてね」
→ すべての特徴を残しつつも、過剰にフィットしないようにバランスを取ります**。
比較表で整理!
| 指標 | L1正則化 | L2正則化 |
|---|---|---|
| ペナルティ | 重みの絶対値の和 | 重みの2乗の和 |
| 結果 | 一部の重みをゼロにする(特徴選択) | 重みを小さく均等にする |
| 向いている場面 | 特徴が多くて「どれが効いてるか知りたい」 | 少しの過学習をなだらかに抑えたい |
| 数式の印象 | スパッと! | ふんわり。 |
🧠 覚え方①:「1(ワン)= ワンチャンゼロ」
- L1は「ワンチャン重みゼロ」にする
- → ゼロになる可能性があるのはL1だけ!
- → 特徴選択したいならL1!
📌 語呂:「L1=ゼロにするワンチャン」
🧠 覚え方②:「L2は2乗、ゼロにはしない」
- L2 = square = 2乗 でおだやかに重みを抑える
- → 重みは「弱くなる」けどゼロにはならない
- → 滑らかで安定、全体的に抑える
📌 語呂:「L2は重みをスムーズに丸くする」
図解
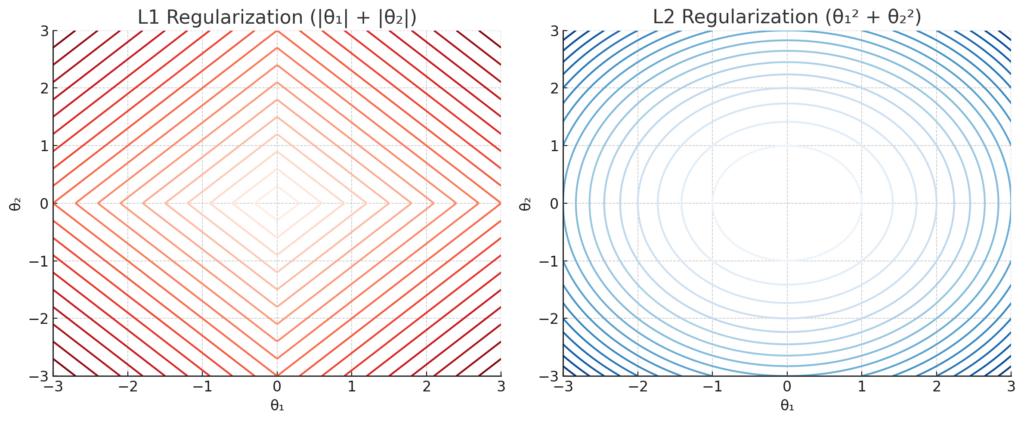
🟥 左:L1正則化(Lasso)
- ひし形の等高線になっているのが特徴です。
- ペナルティは「|θ₁| + |θ₂|」で計算されるため、座標軸と交わるポイント(=θ₁やθ₂がゼロ)を好む傾向があります。
- → 重みがスパッとゼロになりやすい!
🟦 右:L2正則化(Ridge)
- 円形の等高線が特徴です。
- すべての方向に対して均等に滑らかに抑制がかかります。
- 重みはゼロになりにくく、極端な値を避ける形で小さくまとまるのが特徴です。
🌱 まとめ:選び方のヒント
- L1:特徴量が多すぎるとき → いらないものを削ってくれる
- L2:過学習が心配なとき → 重み全体をなめらかに抑えてくれる
- 実務ではL1とL2のハイブリッド(ElasticNet)も使われます!
正則化は「モデルのダイエット」。
太りすぎ(=複雑すぎ)なモデルにうまく制限をかけるのが大事なんです!
必要なら、Pythonで実演するコードやグラフ付きの解説もご用意できます!
さらに詳しく学びたい部分があれば、ぜひ教えてください。
生成AI研修のおすすめメニュー
投稿者プロフィール

