
【マージン最大化とは?】サポートベクターマシン(SVM)の仕組みを世界一わかりやすく解説!
 山崎講師
山崎講師こんにちは。ゆうせいです。
k-近傍法、決定木、ロジスティック回帰…。
機械学習のアルゴリズムを学んでいく中で、「SVM」というアルファベット3文字を目にしたことはありませんか?
なんだか専門的で、少しだけ難しそうな響きがありますよね。
サポートベクターマシン(Support Vector Machine, SVM)は、特に「分類」タスクにおいて非常に高い性能を発揮することで知られる、強力で美しいアルゴリズムです。
その裏側にあるアイデアは、実は驚くほどシンプルでエレガント。
今回は、このSVMの考え方の核心部分を、例え話を交えながら誰にでもわかるように解き明かしていきます!
SVMの基本思想:「境界線」はどこに引くのがベスト?
SVMの目的は、データをグループ分けするための「境界線」を引くことです。
では、ベストな境界線とは一体どんな線でしょうか?
ここに、赤色のグループと青色のグループに分かれたデータがあるとします。
あなたなら、この2つのグループを分ける線をどこに引きますか?
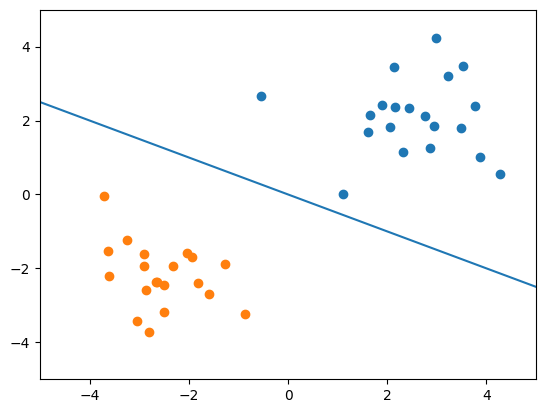
おそらく、こんな感じの線を引くのではないでしょうか。
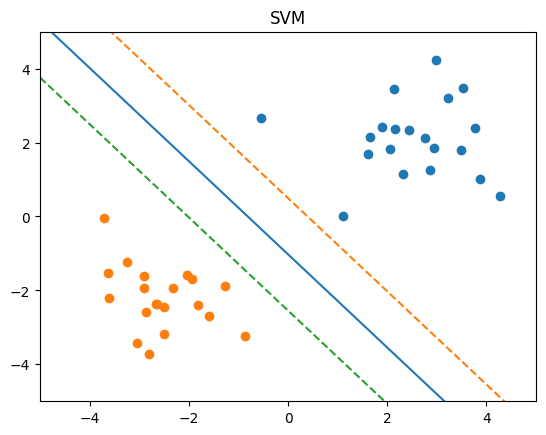
では、次の線はどうでしょう?
この線でも、一応は2つのグループを分けられています。
しかし、なんだか少し不安な感じがしませんか?
青色のグループにギリギリすぎて、もし新しい青色のデータが少しでも線の近くに現れたら、間違えて赤色グループだと判断してしまいそうです。
SVMは、この「不安」を数学的に解決します。
SVMが考える「ベストな境界線」とは、それぞれのグループから最も距離が離れている、一番マージンの大きい線です。
マージン最大化という考え方
「マージン」とは、境界線と、境界線に最も近いデータ点との間の「余白」や「距離」のことです。
SVMは、このマージンが最大になるような境界線を探索します。これがマージン最大化という、SVMの最も重要なコンセプトです。
道路をイメージしてみてください。
境界線が「センターライン」だとすれば、マージンは「路肩までの幅」です。
SVMは、どちらの車線からも等しく、そして最も広い路肩を確保できるようなセンターラインを引こうとするのです。
この方が、車(新しいデータ)が多少ふらついても、対向車線にはみ出しにくい(誤分類しにくい)、安全な道路になりますよね。
SVMの数式を簡単に解説

1. 舞台設定:データを分ける直線を引こう
まずは、私たちが解決したい問題の状況を整理しましょう。
手元には、いくつかのデータがあります。
これらを機械に学習させるためのデータとして、次のように表現します。
- 学習データ:
- データの入力:
- データの正解ラベル:



ここで、
例えば、果物の重さや色味を数字にしたものだと考えてください。
そして 
このデータを分類するために、私たちは次のような関数を使います。
分類関数:

この式、見覚えはありませんか。
中学生で習う直線の式 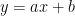


この関数に新しいデータを入れたとき、答えがプラスならグループA、マイナスならグループBと判定する仕組みです。
どうですか。意外とシンプルに感じられませんか。
2. ハードマージンSVMの狙い:一番「余裕」のある境界線
データを分ける線は、一本だけではありません。
適当に引いても分けることはできますが、ギリギリのところに線を引いてしまうと、少しデータがズレただけで判定ミスが起きてしまいます。
そこで登場するのが、ハードマージンSVMという考え方です。
最適化問題(Primal)
最も理想的な線を見つけるために、私たちは次の数式を解くことになります。
目的:

制約: 

この数式が何を命令しているのか、一つずつ解読していきましょう!
マージン最大化という「ゆとり」の追求
目的関数の 
マージンとは、境界線から一番近いデータまでの「隙間」のことです。
道路に例えてみましょう。
道幅がギリギリの狭い道路を運転するのは怖いですよね。
逆に、道幅が広くて余白がたっぷりあれば、多少ハンドル操作を誤っても脱輪しません。
この「道幅」をできるだけ広く確保しようとするのが、マージン最大化です。
厳しいルール:一滴のミスも許さない
制約式の
ハードマージンという名前の通り、このルールは非常にスパルタです。
データが少しでも境界線を越えたり、マージンの中に侵入したりすることを一切認めません。
すべての学習データが、正解ラベルの方向へ正しく、かつ一定以上の距離を保って配置される必要があるのです。
SVMを理解するための重要キーワード
マージン最大化のイメージが掴めたところで、SVMを語る上で欠かせない3つの専門用語を見ていきましょう。
- 超平面 (Hyperplane)先ほどから「境界線」と呼んでいるものの、より専門的な呼び方です。データが2次元(特徴量が2つ)なら境界は「線」ですが、3次元なら「平面」になります。4次元以上になると私たちは想像できませんが、数学的には同じように境界を考えることができます。それらをひっくるめて「超平面」と呼びます。
- マージン (Margin)先ほど説明した通り、超平面と、それに最も近いデータ点との間の距離(余白)です。SVMはこのマージンを最大化します。
- サポートベクター (Support Vector)これが、このアルゴリズムの名前の由来にもなっている、非常に重要な概念です。サポートベクターとは、マージンの境界線上に位置するデータ点のことです。彼らは、超平面の位置を「支えている(サポートしている)」重要なベクトル(データ点)なのです。なぜなら、超平面とマージンの位置は、このサポートベクターだけで決まるからです。逆に言えば、サポートベクター以外の、マージンから遠く離れたデータ点が多少動いたとしても、超平面の位置には何の影響も与えません。この「一部の重要なデータだけで境界が決まる」という性質が、SVMを効率的で強力なアルゴリズムにしている理由の一つです。
SVMの真骨頂!カーネルトリック
さて、ここまでの話は、データが一本の直線(あるいは平面)でスパッと分けられる、という前提でした。
では、次のようなデータはどうでしょう?
このようなデータは、どう頑張っても一本の直線で分けることはできません。
「なんだ、SVMは単純な問題にしか使えないのか…」
そう思うのはまだ早いです!ここでSVMの真骨頂、「カーネルトリック」が登場します。
カーネルトリックとは、元の次元では線形分離できないデータを、高次元の空間に写し(次元を上げる)、そこで線形分離できるようにしてしまう魔法のようなテクニックです。
例え話:平面のおはじきを宙に浮かせる!
テーブルの上に、中心に赤色のおはじきが、その周りを囲むように青色のおはじきが置かれているとします。
この2次元のテーブル上では、一本の直線で赤と青を分けることは不可能ですよね。
では、このテーブルの真下から「ドン!」と突き上げて、おはじきを宙に飛ばしたらどうなるでしょう?
真ん中にあった赤色のおはじきは高く舞い上がり、周りにあった青色のおはじきはそれよりは低く飛ぶかもしれません。
すると、先ほどの2次元(テーブル上のx, y座標)に「高さ」という3つ目の次元が加わりました。
この3次元空間の中では、低く飛んでいる青色のおはじきと、高く飛んでいる赤色のおはじきの間に、一枚の「平面(紙)」をスッと差し込むことで、きれいに2つのグループを分離できますよね?
これがカーネルトリックの基本的な考え方です。
実際にデータを高次元空間に飛ばすと計算が大変になってしまいますが、「カーネル関数」というものを使うことで、高次元空間での計算を、元の次元の計算だけで効率的に行う(トリック)ことができるのです。
代表的なカーネルには、線形カーネル(何もしない)、多項式カーネル、そして非常によく使われるRBFカーネルなどがあります。
メリットとデメリット
メリット
- 高い分類性能: 特にデータ点が明確に分離できる場合、非常に高い精度を発揮します。
- 次元の呪いを受けにくい: 特徴量の数が多くても、うまく機能する傾向があります。
- メモリ効率が良い: サポートベクターという一部のデータのみを使ってモデルを表現するため、メモリ効率が良いです。
デメリット
- 大規模なデータセットでは学習が遅い: 学習時の計算量がデータ数の2乗から3乗に比例すると言われており、データ数が非常に多くなると学習に時間がかかります。
- モデルの解釈が難しい: 決定木のように「なぜこのような予測になったのか」を直感的に理解するのは難しい、いわゆる「ブラックボックス」モデルです。
- パラメータ調整が重要: どのカーネルを使うか、そしてカーネルの挙動を制御するパラメータ(Cやガンマなど)を適切に設定しないと、良い性能が出ません。
まとめ:次のステップへ!
今回は、マージン最大化という美しいアイデアに基づく分類アルゴリズム、「サポートベクターマシン(SVM)」について解説しました。
- SVMは、マージン(境界と最近傍データ点との距離)を最大化することで、最も安定した境界(超平面)を見つけ出す。
- 境界の位置を決めるのに使われる重要なデータ点をサポートベクターと呼ぶ。
- 直線で分離できないデータも、カーネルトリックを使って高次元空間に写すことで分離可能にする。
- 高い性能を誇るが、大規模データでは学習が遅く、パラメータ調整が重要。
SVMは、機械学習の歴史の中でも非常に重要な位置を占めるアルゴリズムです。その考え方を理解することは、あなたの引き出しを確実に増やしてくれるはずです。
最後に、あなたのネクストステップです。
- scikit-learnでSVCを動かしてみるまずは使ってみましょう!Pythonのscikit-learnライブラリには、SVC (Support Vector Classification) というクラスがあります。まずは簡単なデータセットで、モデルを学習させ、予測をさせてみてください。
- 決定境界を可視化してみる2次元のデータを使ってSVMを学習させ、その決定境界とサポートベクターをグラフにプロットしてみることを強くお勧めします。マージンが最大化されている様子や、サポートベクターが境界を支えている様子を視覚的に理解すると、一気に腑に落ちますよ。
- カーネルを変えて実験する線形分離できないデータに対して、カーネルをlinear、rbf、polyなどと変えてみると、決定境界がどのように変わるかを観察してみましょう。カーネルトリックの威力を実感できるはずです。
データの中に最も美しい「道」を見つけ出すSVM。
ぜひ、あなたの手でその力を引き出してあげてください。応援しています!
セイ・コンサルティング・グループの新人エンジニア研修のメニューへのリンク
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。

