【脱・過学習】AIモデルの信頼性を爆上げする「クロスバリデーション」入門
 山崎講師
山崎講師こんにちは。ゆうせいです。
機械学習のモデルを作っていて、こんな経験はありませんか?
「学習データでの精度は完璧なのに、未知のデータを入れると全然当たらない...」
これ、新人エンジニアが最初にぶつかる大きな壁なんです。いわゆる「過学習」という状態ですね。AIが手元のデータを丸暗記してしまって、応用力がなくなっている状態です。
せっかく作ったモデルが、実戦で使い物にならなかったらショックですよね?
そこで今回は、モデルの本当の実力を正しく測り、信頼性を高めるための必須テクニック「クロスバリデーション(交差検証)」について解説します。
現場でも当たり前のように使われる手法ですので、ここでしっかりマスターしておきましょう!
なぜ「データを分ける」だけでは不十分なのか
まず、基本のおさらいです。
通常、AIモデルを作るときは、手持ちのデータを「学習用」と「テスト用」の2つに分けますよね。これを「ホールドアウト法」と呼びます。
例えば、データを7対3に分けて、7で勉強して3でテストする。一見、これで良さそうに思えます。
でも、ここに落とし穴があるんです。
もし、たまたま「テスト用」に選ばれたデータが、すごく簡単なものばかりだったらどうでしょう? 実力以上に高い点数が出てしまいますよね。逆に、難問ばかり集まってしまったら、実際よりも低い評価になってしまいます。
つまり、1回だけのテストでは「運」の要素が強すぎて、そのモデルが本当に優秀なのか判断できないのです。
そこで登場するのが、クロスバリデーションです。
クロスバリデーションの仕組みをイメージしよう
クロスバリデーションを一言でいうと、「テスト担当をローテーションさせて、何度も検証する」手法です。
最も一般的な「K分割クロスバリデーション」を例に、仕組みを見てみましょう。ここではわかりやすく、データを5つのグループに分けるとします(これを 
手順はとてもシンプルです。
- データを5つのグループ(A、B、C、D、E)に等しく分割します。
- 1回目: Aをテスト用、残り(B〜E)を学習用にして評価します。
- 2回目: Bをテスト用、残り(A、C〜E)を学習用にして評価します。
- これをC、D、Eがテスト担当になるまで繰り返します。
- 最後に、合計5回分のスコアの「平均」を出します。
どうでしょう? この方法なら、すべてのデータが一度は「テスト用」として使われます。
たまたま簡単なデータにあたって高得点が出ても、他の回でバランスが取れるので、まぐれ当たりを排除できるのです。これが、クロスバリデーションが「信頼性が高い」と言われる理由です。
エンジニアにとってのメリット
現場でこの手法を使うメリットは、大きく分けて2つあります。
1. 少ないデータを無駄なく使える
データ収集は大変な作業です。せっかく集めた貴重なデータを、テストのためだけに温存しておくのは少しもったいないですよね。クロスバリデーションなら、ローテーションさせることで、最終的に「すべてのデータを学習にもテストにも活用」できます。データ数が少ないプロジェクトでは、特に重宝しますよ。
2. モデルの「設定値」選びに失敗しない
機械学習モデルには、人間が決めてあげなければならない設定値(ハイパーパラメータ)がたくさんあります。
「設定Aと設定B、どっちが優秀かな?」と迷ったとき、クロスバリデーションの平均スコアで比較すれば、運に左右されずに、本当に性能が良い設定を選び抜くことができます。
知っておくべきデメリット
もちろん、良いことばかりではありません。デメリットもしっかり把握しておきましょう。
それはズバリ、「計算時間がかかる」ことです。
ホールドアウト法なら1回の学習と評価で終わりますが、5分割クロスバリデーションなら5回、10分割なら10回繰り返すことになります。単純計算で、時間が 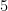

ディープラーニングのように、1回の学習に何日もかかるような巨大なモデルでは、時間のコストが大きすぎるため、あえて使わないという判断も必要になります。
今後の学習の指針
ここまで読んでいただき、ありがとうございます。
クロスバリデーションは、AI開発における「品質保証」のようなものです。自分の作ったモデルに自信を持つためにも、ぜひ使いこなせるようになってください。
次のステップとして、Pythonの機械学習ライブラリ「scikit-learn」を使って実装してみることをおすすめします。
cross_val_score などの関数を使えば、驚くほど短いコードで実装できて感動しますよ!
まずは手元の小さなデータセットで、分割数を変えながら精度の変化を観察してみてください。
それでは、またお会いしましょう!
セイ・コンサルティング・グループでは新人エンジニア研修のアシスタント講師を募集しています。
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。
最新の投稿
 山崎講師2026年8月1日コンピューターが数値計算の誤差に対処する仕組みと精度管理の方法
山崎講師2026年8月1日コンピューターが数値計算の誤差に対処する仕組みと精度管理の方法- 山崎講師2026年8月1日0乗が1になる理由を2乗の計算式から解説する指数法則の基礎
- 山崎講師2026年8月1日機械学習モデルの予測理由を解釈するSHAPとシャープレイ値の基礎
- 山崎講師2026年8月1日適合率と再現率の概念と初心者向けのわかりやすい再翻訳案