【講師向け】Adagradの「急停止」を防げ!RMSpropを「毎日のコーヒーブレンド」で解説
 山崎講師
山崎講師こんにちは。ゆうせいです。
前回の記事では、足元を見て慎重に歩く「Adagrad」について解説しました。しかし、この Adagrad には一つだけ、どうしても無視できない致命的な弱点がありましたね。
そうです。「長く学習を続けていると、ある日突然、一歩も動けなくなってしまう」という問題です。
研修で生徒さんから「先生、学習が進むにつれて loss が全く下がらなくなりました……」と相談されたら、それは Adagrad の限界かもしれません。
今日は、その弱点を克服するために生まれた「RMSprop(アールエムエス・プロップ)」というアルゴリズムについてお話しします。難しそうな名前ですが、教えるときは「老舗のコーヒー店のブレンド」に例えると、驚くほどスッと理解してもらえますよ。
Adagrad が止まってしまう理由の復習
まずは、なぜ Adagrad が止まってしまうのかを簡単におさらいしましょう。
Adagrad は、過去の勾配の2乗をひたすら「足し算」し続けます。

これを生徒さんにはこう伝えてください。
「Adagrad は、創業以来の全てのコーヒー豆を、一つの巨大な瓶に貯め続けているようなものです」
最初は瓶に余裕があるので、新しい豆の味が分かります。しかし、時間が経つにつれて瓶はパンパンになり、数字(分母)が巨大になります。
分母が無限に大きくなれば、更新量(割り算の結果)は 
つまり、「瓶がいっぱいで、もう新しい豆が入らない!」という状態になり、学習がストップしてしまうのです。
RMSprop は「過去を少しずつ忘れる」
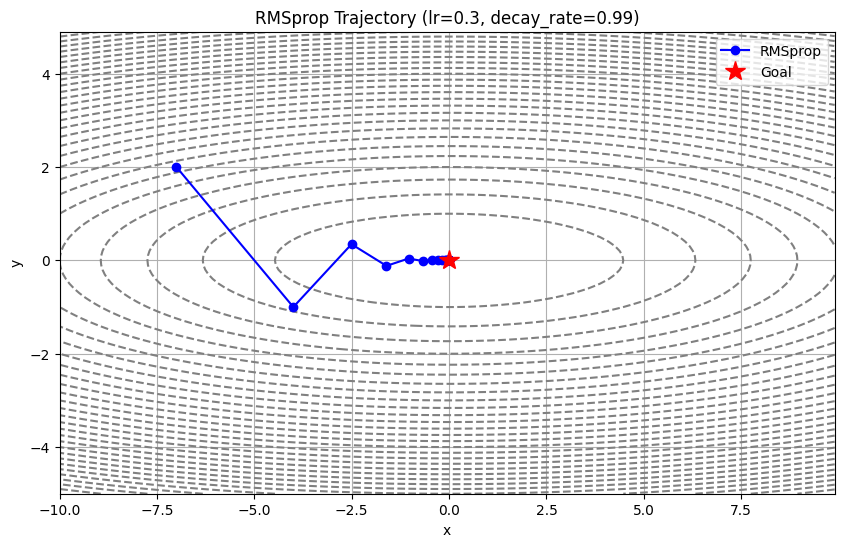
そこで登場するのが RMSprop です。
このアルゴリズムの最大の特徴は、「過去の記憶を少しずつ忘れながら、新しい情報を取り入れる」 という点にあります。
これを専門用語では「指数移動平均」と言いますが、この言葉をそのまま使っても生徒さんは眠くなるだけです。
ここで、「こだわりのコーヒーブレンド」 の話をしましょう。
生徒さんに、こうイメージしてもらってください。
「RMSprop という名前のマスターがいるコーヒー店では、毎日こんなルールでブレンドを作っています」
- 昨日のブレンドを
%残す(過去の記憶)
- そこに、今日の挽きたての豆を
%だけ加える(新しい情報)
- これを混ぜて、今日のブレンドにする
こうすれば、瓶がパンパンになることはありませんよね?
古い豆の味は、少しずつ薄れて消えていきます。一方で、常に「最近のトレンド」を
これが RMSprop の仕組みです。
「過去の全てを記憶するのではなく、最近の傾向だけを大事にする」
だから、学習がどれだけ長く続いても、Adagrad のように完全に止まってしまうことがないのです。
数式で見る「ブレンドの比率」
では、このコーヒーブレンドの話を数式に翻訳してみましょう。
RMSprop の式は以下のようになります。

ここで登場する 

: ブレンドの味(勾配の記憶)
などにします。
: 「今日の豆を入れる割合」。
ですね。
この式を見せながら、こう伝えてください。
「見てください。
RMSpropの名前の由来
二乗平均平方根が鍵
この名前、実は4つの英単語の頭文字をつなげたものなんです。「Root Mean Square Propagation」が正式名称です。それぞれ分解してみましょう。
- Root(ルート):平方根
- Mean(ミーン):平均
- Square(スクエア):二乗
- Prop(プロップ):Propagation(伝播)の略
前の3つ「Root Mean Square」は、理系科目ではお馴染みの「二乗平均平方根」という言葉を指しています。
なぜ、わざわざ「二乗」して「ルート」に戻すような面倒なことをするのでしょうか。
それは、マイナスの値をプラスとして扱いたいからです。
例えば、 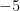

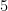
そこで、一度二乗して( 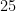
この計算方法を使って、AIの学習情報を次へと伝えていく(Prop)ことから、この名前が付けられました。名前の意味を知ると、数式も少しだけ親しみやすく感じませんか?
Pythonコードで実装する
それでは、実際に Python のコードでこの「ブレンド」がどう書かれているかを見てみましょう。
前回の Adagrad との違いは、たった一行だけです。
class RMSprop:
def __init__(self, lr=0.01, decay_rate=0.99):
self.lr = lr
self.decay_rate = decay_rate # 過去の記憶をどれくらい残すか(α)
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
# 【ここが RMSprop の核心!】
# Adagrad は単なる足し算(+=)でしたが、
# RMSprop は「過去」と「現在」をブレンドします。
# 式: h = α * h + (1 - α) * g^2
self.h[key] *= self.decay_rate
self.h[key] += (1 - self.decay_rate) * grads[key] * grads[key]
# パラメータの更新(ここは Adagrad と同じ)
# 記憶された h のルートで割って調整します
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)Adagrad のときは self.h[key] += ... とひたすら足していましたが、今回は decay_rate を掛けている点に注目させてください。
RMSprop のメリット・デメリット
最後に、この手法の特徴を整理しましょう。
メリット
- 学習が止まらない: 過去の情報を適切に忘れるので、学習が長時間続いても更新がストップしません。
- 変化に対応できる: 常に「最近の坂道の様子」を見ているので、状況が変わっても柔軟に対応できます。
デメリット
- 調整する数字が増える: 学習率(lr)に加えて、減衰率(decay_rate)というハイパーパラメータを決めなければなりません(とはいえ、大抵は
で上手くいきます)。
今日のまとめ
いかがでしたか?
- Adagrad は「瓶がいっぱいになって止まってしまう」
- RMSprop は「古いものを捨てて、常に新しいものをブレンドする」
- 数式の
これで、「足元の調整(Adagrad/RMSprop)」と「慣性の利用(Momentum)」という2つの大きな武器が揃いました。
次回は、いよいよこの2つを合体させた、現在最強と言われるアルゴリズム 「Adam(アダム)」 について解説します。
まさに「慣性の勢い」と「足元の慎重さ」を兼ね備えた、ハイブリッドな技術です。
それでは、また次の記事でお会いしましょう。
セイ・コンサルティング・グループでは新人エンジニア研修のアシスタント講師を募集しています。
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。
最新の投稿
 山崎講師2026年8月1日コンピューターが数値計算の誤差に対処する仕組みと精度管理の方法
山崎講師2026年8月1日コンピューターが数値計算の誤差に対処する仕組みと精度管理の方法- 山崎講師2026年8月1日0乗が1になる理由を2乗の計算式から解説する指数法則の基礎
- 山崎講師2026年8月1日機械学習モデルの予測理由を解釈するSHAPとシャープレイ値の基礎
- 山崎講師2026年8月1日適合率と再現率の概念と初心者向けのわかりやすい再翻訳案