
Irisデータセットで学ぶ!機械学習の実践ロードマップ
 山崎講師
山崎講師こんにちは。ゆうせいです。
アヤメのデータでAIの扉を開こう!データの姿を覗く可視化と準備編
これから皆さんと一緒に、機械学習の第一歩を踏み出せることをとても嬉しく思います。
記念すべき第1回は、機械学習の世界で最も愛されているデータセット、Iris(アヤメ)を使って、データの正体を探っていきます。
人工知能に何かを教える前に、まずは私たち人間がそのデータを知らなくてはなりません。
あなたは、目の前にある数字の束から、花の種類を見分けるヒントを見つけ出すことができるでしょうか?
機械学習のスタート地点!探索的データ解析(EDA)
機械学習を始めるとき、いきなり難しい数式を解かせるわけではありません。
最初に行うのは、探索的データ解析(EDA)と呼ばれる作業です。
これは、データという名の宝箱を開けて、中身をじっくり眺めるようなものです。
どこにどんなお宝(特徴)があるのか、あるいはゴミ(外れ値)が混じっていないかを確認します。
アヤメのデータには、3つの品種(セトナ、バーシカラー、バージニカ)が含まれています。
それぞれの品種ごとに、見た目の特徴がどう違うのかを分析していきましょう。
データの中身を理解するための専門用語
高校生の皆さんでもイメージしやすいように、重要な用語を例え話で解説しますね。
特徴量(とくちょうりょう)
特徴量とは、機械が学習するための「ものさし」のことです。
アヤメの場合、以下の4つのものさしが用意されています。
- がく片の長さ(Sepal Length)
- がく片の幅(Sepal Width)
- 花びらの長さ(Petal Length)
- 花びらの幅(Petal Width)
例えば、あなたがある果物を「りんご」か「みかん」か見分けるとき、色や表面のざらつきをヒントにしますよね?
その「色」や「ざらつき」こそが、機械学習における特徴量なのです。
散布図(さんぷず)
散布図は、2つの特徴量を縦軸と横軸にとって、データを点として打ち込んだグラフのことです。
これを見ると、データがどのように集まっているかが一目でわかります。
例えば、横軸に「花びらの長さ」、縦軸に「花びらの幅」をとってみましょう。
特定の品種だけが左下に固まっていたら、「花びらが小さければこの品種だ!」というルールが予測できますよね。
Pythonでデータを準備してみよう
それでは、実際にデータを読み込む準備をしましょう。
プログラミング言語のPythonには、便利な道具箱がたくさん用意されています。
from sklearn.datasets import load_iris
import pandas as pd
# データの読み込み
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['target'] = iris.target
# 最初の5行を表示
print(df.head())
このコードを実行すると、アヤメのサイズが記録された表が表示されます。
ここには 
データの準備におけるメリットとデメリット
データを可視化して準備することには、どんな意味があるのでしょうか。
メリット
- 予測の当たりがつく:グラフを見るだけで「この品種は簡単に見分けられそうだな」といった見通しが立ちます。
- ミスに気づける:
センチを超えるアヤメのような、ありえない数値(異常値)が混じっていても、可視化すればすぐに見つかります。
デメリット
- 手間がかかる:早くアルゴリズムを動かしたい人にとっては、地味な作業に感じるかもしれません。
- 偏った解釈のリスク:たまたま見た
つの項目だけで全てを判断してしまうと、本質を見失うことがあります。
今回のまとめと今後の指針
第1回では、データのヒントとなる特徴量について学び、EDAの大切さを確認しました。
機械学習は、魔法ではありません。
地道にデータを観察し、そこにあるパターンを見つけ出す作業の積み重ねです。
今回読み込んだデータの数字を眺めてみて、何か法則性が見つかりそうでしょうか?
次は、この準備したデータを使って、実際に機械に分類をさせてみます。
第2回では、もっとも直感的な手法である「k近傍法」に挑戦しましょう。
まずは今回紹介したコードを自分のパソコンで動かして、データの顔ぶれを確認してみてください。
準備ができたら、次のステップへ進むためのプログラムを一緒に書いてみませんか?
こんにちは。ゆうせいです。
第1回ではデータの顔ぶれを確認しましたね。
第2回となる今回は、いよいよ機械に「分類」をさせてみましょう!
今回挑戦するのは、数ある機械学習の手法の中でもトップクラスに直感的な「k近傍法」です。
AIがどうやって「これはセトナだ!」「これはバージニカだ!」と判断しているのか、その舞台裏を覗いてみましょう。
似たもの同士は友達?k近傍法の仕組み
k近傍法(k-Nearest Neighbors, k-NN)を一言で言うなら、「類は友を呼ぶ」作戦です。
新しく見つけたアヤメの品種を当てたいとき、あなたならどうしますか?
この手法では、そのアヤメの「花びらの長さ」や「幅」が似ている、近くにいる 
もし、近くにいる 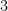
とてもシンプルで分かりやすいですよね!
重要な専門用語をマスターしよう
初心者が最初につまずきやすい言葉を、身近な例で解説します。
k(ケイ)
これは「近所のデータを何個まで参考にするか」という数字です。
例えば 


クラスで流行っているものを知りたいとき、
この
ハイパーパラメータ
先ほどの
ラジコンの感度調整や、オーブンの温度設定のようなものだと考えてください。
機械が勝手に決めてくれるわけではないので、私たちが「一番いい数字」を探してあげる必要があります。
プログラムで分類に挑戦!
それでは、実際にScikit-learnを使ってモデルを作ってみましょう。
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
# データを学習用とテスト用に分ける
X_train, X_test, y_train, y_test = train_test_split(
iris.data, iris.target, test_size=0.2, random_state=42
)
# モデルの作成(近所5人を参考にする設定)
knn = KNeighborsClassifier(n_neighbors=5)
# 学習(データの特徴を覚えさせる)
knn.fit(X_train, y_train)
# 予測(テスト用データで実力テスト!)
score = knn.score(X_test, y_test)
print(f"正解率: {score}")
このコードでは、手元のデータの 
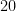
正解率はどれくらいになりましたか?きっと驚くほど高い数字が出たはずです!
k近傍法のメリットとデメリット
使いやすい手法ですが、万能というわけではありません。
メリット
- 仕組みが簡単:直感的に理解できるので、結果の説明がしやすいです。
- 事前準備が少ない:複雑な数式を組み立てる必要がなく、すぐに試せます。
デメリット
- 計算に時間がかかる:データが
- データの偏りに弱い:特定の品種だけデータが極端に多いと、多数決の結果がそちらに流されやすくなります。
今回のまとめと今後の指針
第2回では、もっとも基本的な分類アルゴリズムであるk近傍法を学びました。
「近くのデータの多数決で決める」というルールは、シンプルながらも強力です。
さて、ここで一つ疑問が浮かびませんか?
「多数決ではなく、確率で計算することはできないの?」と。
次回の第3回では、統計学の力を借りて「このアヤメがセトナである確率は 
今回のプログラムで、 
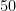
ぜひ実験して、その結果を教えてくださいね!
こんにちは。ゆうせいです。
第2回のk近傍法はどうでしたか?「近くにいる仲間に合わせる」という考え方は、とても直感的でしたよね。
第3回となる今回は、少し大人なアプローチ、「ロジスティック回帰」に挑戦しましょう。
名前に「回帰」と付いているので、数字を予想するものかな?と思うかもしれませんが、実はこれ、分類問題で非常に頼りになる手法なんです。
白黒はっきりつけるだけじゃない!「確率」で考える分類
k近傍法は多数決でしたが、ロジスティック回帰は「どれくらいその品種らしいか」を 
例えば、あるアヤメを見て「これは 
このように、データの境界線を数式で表現し、滑らかな坂道のようなグラフ(シグモイド関数)を使って分類するのがこの手法の特徴です。
重要な専門用語をマスターしよう
今回のステップで登場する、少し難しいけれど大切な言葉を解説します。
ロジスティック回帰
名前に惑わされないでくださいね!これは「回帰」という仕組みを使って「分類」を行う手法です。
イメージとしては、試験の点数(数値)から、合格か不合格か(カテゴリー)を判定するようなものです。
正解率(Accuracy)
モデルがどれくらい優秀かを測る一番シンプルな物差しです。


ただし、これだけで全てを判断するのは危険なこともあるのですが……それはまた後ほどお話ししますね。
プログラムで確率を計算してみよう
それでは、Pythonでロジスティック回帰を実行してみましょう。
from sklearn.linear_model import LogisticRegression
# モデルの作成
# max_iterは計算を繰り返す回数の上限です
model = LogisticRegression(max_iter=200)
# 学習
model.fit(X_train, y_train)
# 予測
y_pred = model.predict(X_test)
# 確率を表示してみる(最初の3件分)
probs = model.predict_proba(X_test[:3])
print(f"各品種である確率:\n{probs}")predict_proba という命令を使うのがポイントです。
実行結果を見ると、3つの数字が並んでいるはずです。これがそれぞれの品種である確率を表しています。
ロジスティック回帰のメリットとデメリット
バランスの取れた手法ですが、得意不得意があります。
メリット
- 理由がわかりやすい:どの特徴量が分類に強く影響したかを数値で確認できます。「花びらの長さが
- 計算が速い:複雑な計算を必要としないため、サクサク動きます。
デメリット
- 直線的な分類しかできない:データが複雑に絡み合っている場合、真っ直ぐな線(または平面)で区切ろうとするロジスティック回帰では、うまく分類できないことがあります。
今回のまとめと今後の指針
第3回では、確率を使ってスマートに分類するロジスティック回帰を学びました。
「なんとなくこっち」ではなく、数式に基づいた根拠を持って分類できるようになったのは大きな進歩です!
さて、今のところ私たちは「直線的なルール」や「近所の多数決」で戦ってきましたが、現実はもっと複雑ですよね。
「もし花びらが長くて、かつ、がくが広ければ……」といった、条件分岐の連続で判断したいと思いませんか?
次回の第4回では、まるでYES/Noチャートのような仕組みで分類する「決定木(けっていぎ)」と、その進化形である「ランダムフォレスト」に挑戦します。
今回の確率の結果を見て、自信満々に当てているデータと、迷いながら(確率が五分五分に近い状態で)当てているデータがあったでしょうか?
もし良ければ、どんな結果になったか詳しく教えてくださいね。
次は、データの中に「木」を育てに行きましょう!
こんにちは。ゆうせいです。
第3回では、確率を使ってスマートに分類する手法を学びましたね。
第4回となる今回は、まるでクイズ番組のYes/Noチャートのような、人間にとっても馴染み深い手法「決定木(けっていぎ)」と、そのパワーアップ版である「ランダムフォレスト」に挑戦しましょう!
データの迷路を切り抜ける!決定木の仕組み
決定木は、データの中に潜む「もし~ならば」というルールを見つけ出し、木が枝分かれするように分類していく手法です。
例えば、「花びらの長さは 
さらに、この「木」をたくさん集めて、みんなで多数決をとる贅沢な手法が「ランダムフォレスト」です。
1人の意見(1本の木)よりも、100人の専門家(100本の木)の意見をまとめる方が、間違いが少なくなります。
重要な専門用語をマスターしよう
木を育てるために必要な、少しプロっぽい言葉を解説します。
決定木
データを条件分岐で分けていくアルゴリズムです。一番上の根っこから、最後に答えが出る葉っぱまで、順を追って判断していきます。
ランダムフォレスト
たくさんの決定木を同時に作り、それらの予測結果を多数決でまとめる手法です。
「森(フォレスト)」という名前の通り、たくさんの木が集まることで、1本の木では防げなかった予測のミスをカバーし合います。
アンサンブル学習
ランダムフォレストのように、複数のモデルを組み合わせて、より強力なひとつのモデルを作る仕組みのことです。
音楽の「アンサンブル(合奏)」と同じで、それぞれの楽器(モデル)が響き合うことで、素晴らしい演奏(高い精度)を生み出します。
プログラムで森を作ってみよう
それでは、Pythonでランダムフォレストを動かしてみましょう。
from sklearn.ensemble import RandomForestClassifier
# モデルの作成
# n_estimatorsは、森の中に何本の木を育てるかという数です
forest = RandomForestClassifier(n_estimators=100, random_state=42)
# 学習
forest.fit(X_train, y_train)
# 予測
score = forest.score(X_test, y_test)
print(f"ランダムフォレストの正解率: {score}")
# どの特徴量が重要だったかを確認
importances = forest.feature_importances_
print(f"特徴量の重要度: {importances}")
実行してみると、どの特徴量(花びらの長さなど)が分類に最も貢献したかが数値でわかります。
アヤメの分類において、どの項目が一番の「決め手」になっていたでしょうか?
決定木とランダムフォレストのメリットとデメリット
非常に人気のある手法ですが、注意点もあります。
メリット
- 理由が明確:決定木単体なら、どういう判断基準で分類したのかを完全に可視化できます。
- データの加工が少なくて済む:これまでの手法と違い、データの数値を揃えたりする下準備が少なくても、高い精度が出やすいのが特徴です。
デメリット
- 過学習(オーバーフィッティング)しやすい:木を深く育てすぎると、手元のデータにだけ詳しすぎて、新しいデータに対応できない「頭の固いモデル」になってしまうことがあります。
- 中身がブラックボックス化する:ランダムフォレストのように木が増えすぎると、なぜその答えになったのかを人間が追うのは難しくなります。
今回のまとめと今後の指針
第4回では、Yes/Noの積み重ねで判断する決定木と、その集合体であるランダムフォレストを学びました。
これであなたは、単体のモデルだけでなく、「チームで予測する」という強力な武器を手に入れましたね!
さて、これまでは「木」や「線」で分けてきましたが、もっと力技で「境界線をグイッと広げる」ような、ストイックな手法も存在します。
次回の第5回では、基礎編の締めくくりとして、非常に高い性能を誇る「サポートベクターマシン」に挑戦します。
これまでの手法と比べて、正解率に違いは出るでしょうか?
もし今回の「重要度」の結果で、意外な項目がランクインしていたら、ぜひ教えてくださいね。
次は、最も美しい境界線を引きに行きましょう!
こんにちは。ゆうせいです。
いよいよ基礎編のクライマックス、第5回です!
前回は「森」を作ってチームプレーで分類しましたが、今回はたった一本の、しかし最高に「キレのある境界線」を引くスペシャリスト、サポートベクターマシン(SVM)を攻略しましょう。
これまで学んできた手法とは一味違う、数学的な美しさを感じていただけるはずです。
ギリギリを攻める!サポートベクターマシンの仕組み
サポートベクターマシンを一言でいうなら、「もっとも余裕のある境界線を引く達人」です。
例えば、机の上に置かれたリンゴとミカンを線で分けるとき、どちらかの果物にギリギリの線を引いてしまうと、少し大きなミカンが来ただけで「これはリンゴだ!」と間違えてしまいそうですよね。
そこで、SVMは両方のグループからできるだけ遠く、道の真ん中に境界線を引こうとします。この境界線と、一番近くにあるデータとの距離を「マージン」と呼びます。このマージンを最大に広げることで、未知のデータに対しても間違いにくい、タフなモデルが完成するのです。
重要な専門用語をマスターしよう
SVMを使いこなすために欠かせない、強力な武器を紹介します。
サポートベクター
境界線を決める際に、ガイド役となる「境界線に一番近いデータ」のことです。
実は、SVMはこの一部のデータ(サポートベクター)だけを見て境界線を決めています。遠くにいる他のデータは、境界線の位置に影響を与えません。非常に効率的な考え方ですよね!
標準化(ひょうじゅんか)
データの「単位」を揃える作業です。
例えば、身長 

これを防ぐために、平均を
カーネル法
もしデータが複雑に絡み合っていて、直線ではどうしても分けられないとき、どうすればいいでしょうか?
そんなとき、データを一時的に「より高い次元(立体の世界)」に飛ばして、そこでスパッと平面で切り分ける魔法のような技術がカーネル法です。
プログラムで最強の境界線を引こう
SVMは単位の違いに敏感なので、今回は「標準化」の工程も一緒に入れてみましょう。
from sklearn.svm import SVC
from sklearn.preprocessing import StandardScaler
# データの単位を揃える(標準化)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# モデルの作成(SVCは分類用のSVMです)
model = SVC(kernel='linear', random_state=42)
# 学習
model.fit(X_train_scaled, y_train)
# 予測
score = model.score(X_test_scaled, y_test)
print(f"サポートベクターマシンの正解率: {score}")
標準化を行わずに実行した場合と、結果に差が出るかもしれません。ぜひ、その違いを観察してみてください。
サポートベクターマシンのメリットとデメリット
メリット
- 精度が非常に高い:特にデータの特徴量が多い場合に、他の手法よりも優れた性能を発揮することが多いです。
- 外れ値に強い:境界線付近のデータ(サポートベクター)しか見ないため、遠くにある変なデータに惑わされにくい性質があります。
デメリット
- データの準備が必須:先ほどの「標準化」を忘れると、ガクンと精度が落ちてしまいます。
- 学習に時間がかかる:データの数が何十万件と増えてくると、計算が非常に重くなってしまいます。
今回のまとめと今後の指針
第5回、お疲れ様でした!これで「機械学習の基礎アルゴリズム」を一通りマスターしたことになります。
多数決のk近傍法、確率のロジスティック回帰、Yes/Noの決定木、そしてマージン最大化のSVM。
それぞれの個性を知ることで、データの性格に合わせた「武器」を選べるようになったはずです。
さて、ここまでは「昔からある定番の手法」を学んできました。
しかし、AIの世界は日々進化しています。もっともっと速く、もっともっと賢い「最新のエース」たちが、あなたの挑戦を待っています。
次回、第6回からは「発展編」に突入です!
現在、実務の現場で最強と名高い「勾配ブースティング決定木(LightGBMなど)」の世界へ踏み込んでみませんか?
これまでの 
その理由と一緒に、次への意気込みを聞かせてくださいね!
こんにちは。ゆうせいです。
いよいよ今回から発展編のスタートです!基礎編で学んだ「決定木」を覚えていますか?
第6回では、その決定木を究極まで進化させた、現代の機械学習界における「最強のエース」をご紹介します。
その名も、勾配ブースティング決定木(GBDT)です。
いま、データ分析のコンペティションや実際のビジネス現場で「とりあえずこれを動かせば間違いない」と言われるほど、圧倒的な実力を誇る手法なんですよ。
弱点を補い合って最強を目指す!勾配ブースティングの仕組み
勾配ブースティングを一言でいうなら、「反省を次に活かす、超ストイックなリレー学習」です。
前回のランダムフォレストは、たくさんの木が「せーの!」で同時に予測して多数決をとるスタイルでした。
それに対して勾配ブースティングは、1本目の木が予測し、そこで間違えた分(誤差)だけを次の2本目の木が必死に学習します。さらに3本目の木は、2本目でも解決できなかった間違いを学習していく……というように、前の木のミスを後ろの木がカバーしながら、少しずつ正解に近づいていくのです。
この「間違い(勾配)を減らしていく」というストイックな姿勢が、驚異的な予測精度を生み出す秘密なんです!
重要な専門用語をマスターしよう
最新の手法を使いこなすために、現場でよく飛び交う言葉を解説しますね。
勾配ブースティング(Gradient Boosting)
「勾配」は数学的な言葉で、ここでは「予測と正解のズレ」を指します。そのズレを、新しいモデルを次々と追加することで「ブースト(強化)」して消していく仕組みのことです。
LightGBM / XGBoost
勾配ブースティングを、さらに高速で賢く動かせるように改良した専用ライブラリの名前です。
特にLightGBM(ライト・ジービーエム)は、計算の効率が非常に良く、大きなデータでもサクサク動くため、現在のデータサイエンスの現場で最も人気があります。
早期終了(Early Stopping)
学習を繰り返していく中で、「これ以上木を追加しても精度が上がらないな」と判断した時点で、自動的に学習をストップさせる機能です。
テスト勉強でいえば、もう完璧に覚えたからこれ以上は時間の無駄だ、と切り上げるようなスマートな仕組みですね。
プログラムで最強のエースを動かそう
今回は、世界中で使われている lightgbm というライブラリを使って、アヤメの分類に挑みます。
import lightgbm as lgb
import numpy as np
# LightGBM専用のデータ形式に変換
train_data = lgb.Dataset(X_train, label=y_train)
# パラメータの設定
params = {
'objective': 'multiclass', # 多クラス分類
'num_class': 3, # アヤメの種類数
'metric': 'multi_logloss', # 誤差の評価方法
'verbosity': -1 # ログ出力を静かにする
}
# 学習(100回リレーを繰り返す)
gbm = lgb.train(params, train_data, num_boost_round=100)
# 予測(一番確率が高いクラスを選ぶ)
y_prob = gbm.predict(X_test)
y_pred = [np.argmax(line) for line in y_prob]
# 正解率を確認
from sklearn.metrics import accuracy_score
print(f"LightGBMの正解率: {accuracy_score(y_test, y_pred)}")アヤメのような小さなデータでも、その「キレ味」を感じることができたでしょうか?
勾配ブースティングのメリットとデメリット
メリット
- 圧倒的な予測精度:複雑なルールが絡み合うデータにおいて、他の追随を許さないほど高い正解率を叩き出すことが多いです。
- 特徴量のスケールを気にしなくていい:前回のSVMとは違い、標準化をしなくても高い精度で動いてくれるタフさがあります。
デメリット
- 設定項目(ハイパーパラメータ)が多い:木を育てる速さや深さなど、調整すべき項目が多く、使いこなすには経験が必要です。
- 過学習の危険性:あまりにストイックに間違いを追いかけすぎると、練習問題(学習データ)の細かなノイズまで正解だと勘違いして覚えてしまうことがあります。
今回のまとめと今後の指針
第6回では、現代最強の手法の一つ、勾配ブースティング決定木を学びました。
「間違いをリレー形式で修正していく」という考え方は、私たちの学習プロセスにも似ていて、なんだか親近感が湧きませんか?
さて、これまでは「木」や「線」をベースにした手法でしたが、世の中には「人間の脳」そのものをモデルにしようという、さらに壮大なアプローチが存在します。
次回の第7回では、あのディープラーニングの基礎となる「ニューラルネットワーク」の世界へ飛び込みます。
ついに、AIの真骨頂とも言える領域に足を踏み入れますよ!
今回のLightGBM、これまで学んだ手法と比べてみて、コードの書き味や結果はどう感じましたか?
次は、コンピューターの中に「神経細胞」を作ってみましょう!
こんにちは。ゆうせいです。
いよいよ第7回ですね!ここまで、さまざまな計算手法や「森」の力を借りて分類をしてきましたが、今回はついに「AI」と聞いて誰もが思い浮かべるあの技術、ニューラルネットワークに挑戦します。
ディープラーニング(深層学習)という言葉をニュースで見かけない日はありませんよね。その心臓部にあたる仕組みを、アヤメのデータを使って動かしてみましょう!
コンピューターの中に脳を作る?ニューラルネットワークの仕組み
ニューラルネットワークは、私たちの脳にある神経細胞(ニューロン)のつながりを、数学の式で再現しようとしたモデルです。
脳の中では、目や耳から入ってきた刺激が神経細胞を伝わり、ある一定以上の強さになると次の細胞へ信号が送られます。これをコンピューターの中で再現するために、「入力層」「中間層」「出力層」という3つの階層を作ります。
- 入力層:アヤメの「花びらの長さ」などのデータを受け取ります。
- 中間層:受け取ったデータに「重み」をつけて計算し、特徴を複雑に組み合わせます。
- 出力層:最終的に「これはセトナだ!」という答えを導き出します。
この「重み」を何度も調整して、正解に近づけていくプロセスが、ニューラルネットワークの学習なんです!
重要な専門用語をマスターしよう
少し難しく聞こえるかもしれませんが、イメージで捉えれば大丈夫ですよ。
パーセプトロン
ニューラルネットワークの最も基本的な単位(細胞1つ分)のことです。複数の入力を受け取って、1つの答えを出す、シンプルな計算ユニットだと考えてください。
活性化関数(かっせいかかんすう)
細胞に届いた信号を、次の層へ「どれくらいの強さで伝えるか」を決める関数です。
例えば、「合計値が
ディープラーニング(深層学習)
中間層を何層も、何十層も重ねた巨大なニューラルネットワークのことです。層を深くすればするほど、より高度で複雑なパターン(例えば、写真に写っているのが猫か犬かなど)を見分けられるようになります。
プログラムで「人工知能」を動かそう
今回は、初心者でも扱いやすい MLPClassifier (多層パーセプトロン)を使って、アヤメの分類を行います。
from sklearn.neural_network import MLPClassifier
# モデルの作成
# hidden_layer_sizes=(10, 10) は、10個の細胞を持つ中間層を2つ作るという意味です
mlp = MLPClassifier(hidden_layer_sizes=(10, 10), max_iter=1000, random_state=42)
# 学習(標準化したデータを使うのがコツです!)
mlp.fit(X_train_scaled, y_train)
# 予測
score = mlp.score(X_test_scaled, y_test)
print(f"ニューラルネットワークの正解率: {score}")
SVMの時と同じように、ニューラルネットワークも「データの単位を揃える(標準化)」ことが非常に重要です。単位がバラバラだと、脳がパニックを起こしてうまく学習できないからなんですね。
ニューラルネットワークのメリットとデメリット
メリット
- 限界がない:データ量と計算能力さえあれば、どんなに複雑なパターンでも学習できる可能性を秘めています。
- 柔軟性が高い:画像、音声、テキストなど、あらゆる種類のデータに対応できます。
デメリット
- ブラックボックス:なぜその答えになったのか、人間が中身の計算を追いかけるのはほぼ不可能です。
- 計算コスト:本格的なディープラーニングを行うには、高性能なコンピューター(GPU)と長い時間が必要になります。
今回のまとめと今後の指針
第7回では、AIの代名詞とも言えるニューラルネットワークの入り口に立ちました。
「数式で脳を模倣する」というアイデア、ワクワクしませんか?
これまでの学習は、すべて「正解(アヤメの品種名)」が分かっている状態で進める「教師あり学習」でした。しかし、世の中には正解が分からないデータもたくさんあります。
次回の第8回からは、正解ラベルを使わずにデータのグループ分けを行う「教師なし学習」の世界、クラスタリングに挑戦します!
コンピューターが自ら「このグループとこのグループは似ているぞ」と発見する様子は、また違った驚きがありますよ。
今回の「人工知能」の正解率、他の手法と比べてどうでしたか?ぜひ感想を教えてくださいね!
こんにちは。ゆうせいです。
第7回までは、あらかじめ品種という「正解」がわかっているデータを扱ってきましたね。
第8回となる今回は、ガラリと趣向を変えて、正解を教えずにAI自身にデータのまとまりを見つけてもらう「教師なし学習」に挑戦しましょう!
これを「クラスタリング」と呼びます。品種名というラベルを隠した状態で、AIは果たしてアヤメの個性を自力で見抜けるのでしょうか?
答えを教えない教育?クラスタリングの仕組み
これまでの手法が「先生が答えを教えてくれる勉強」だとしたら、クラスタリングは「バラバラに置かれたカードを、似たもの同士でグループ分けする遊び」に似ています。
中でももっとも有名なのが、k-means(ケー・ミーンズ)法です。
- まず、データの中に
- それぞれのデータは、一番近い中心点のグループに所属します。
- グループに所属したデータの平均をとって、中心点を「真ん中」へ移動させます。
- 2と3を繰り返し、中心点が動かなくなったら完成です!
人間が「これがセトナだよ」と教えなくても、AIが勝手に「このグループは花びらが小さいから仲間だね」と判断してくれるのです。
重要な専門用語をマスターしよう
教師なし学習の世界で使われる、ちょっと不思議な言葉を解説します。
教師なし学習
「入力データ」だけで学習し、データの中に隠れた構造やパターンを見つけ出す手法です。
売上データから顧客をグループ分けしたり、写真の中から似た構図のものを選び出したりするときに活躍します。
クラスタリング
似ているデータ同士をまとめて、グループ(クラスタ)を作ることです。
アヤメのデータなら、「品種」という名前を知らなくても、形の特徴だけで
エルボー法
「結局、何個のグループに分けるのが正解なの?」という疑問を解決するための方法です。
グループの数を増やしていったとき、グラフの形が「ひじ(Elbow)」のように折れ曲がる点を探すことで、最適なグループ数を見つけ出します。
プログラムで「自律的な発見」を体験しよう
今回は、あえて品種ラベルを使わずに、k-means法で
from sklearn.cluster import KMeans
# モデルの作成(3つのグループに分けるように指示)
# 品種名は一切使いません!
kmeans = KMeans(n_clusters=3, random_state=42)
# 学習(特徴量だけでグループを探す)
kmeans.fit(iris.data)
# 分類結果のラベルを取得
clusters = kmeans.labels_
# 実際の品種(iris.target)とどれくらい一致しているか確認してみましょう
print(f"AIが見つけたグループ分け:\n{clusters}")
実行してみると、AIが独自に振り分けた 
実際の品種ラベルと見比べてみてください。驚くほど正確に言い当てている部分はありませんか?
クラスタリングのメリットとデメリット
メリット
- 正解がなくても使える:ラベルを付けるのが大変な大量のデータでも、とりあえず傾向を掴むことができます。
- 新たな発見がある:人間が気づかなかった「実はこの品種の中にも、さらに
デメリット
- 評価が難しい:正解がないため、そのグループ分けが本当に「正しい」のかどうかを判断するのは、最終的には人間の解釈に委ねられます。
- 初期値に左右される:最初に置く中心点の位置によって、結果が少し変わってしまうことがあります。
今回のまとめと今後の指針
第8回では、自らルールを見つけ出す教師なし学習を学びました。
「答えを教えなくても、データの特徴だけでここまで見抜けるんだ!」と驚かれたのではないでしょうか。
さて、アヤメには 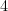
人間には想像もできない複雑な世界になってしまいますよね。
次回の第9回では、たくさんの情報をギュッと凝縮して、本質だけを抜き出す魔法のような技術「次元圧縮」についてお話しします。
AIが作ったグループ分けの結果は、あなたの直感と合っていましたか?
もし「ここだけは間違えているな」という部分があれば、そこには何か理由があるはずです。ぜひ考察してみてくださいね!
こんにちは。ゆうせいです。
第8回では、AIが自らグループを見つけるクラスタリングを体験しましたね。
第9回となる今回は、複雑なデータをシンプルに整理する魔法のような技術、「次元圧縮(じげんあっしゅく)」に挑戦しましょう!
アヤメのデータには4つの特徴量がありますが、これを人間が一度に理解するのは少し大変です。もし、この4つの情報を保ったまま、2つの情報にギュッと凝縮できたらどうでしょうか?
4次元から2次元へ!主成分分析(PCA)の仕組み
次元圧縮の代表選手が、主成分分析(PCA)です。
想像してみてください。ある人の個性を「身長」「体重」「座高」「足のサイズ」という4つの数字で説明するとします。でも、これらをまとめて「体格の大きさ」という1つの指標にまとめることができたら、とても分かりやすいですよね?
PCAは、データの中で「もっとも変化が激しい(=情報がたくさん詰まっている)方向」を見つけ出し、そこに新しい軸を引く作業です。
- データのバラつきが一番大きい方向に「第1主成分」という軸を引きます。
- それと直角に交わる、次にバラつきが大きい方向に「第2主成分」を引きます。
- この2つの軸を使ってデータを描き直せば、4つの数字を使わなくても、平面のグラフでアヤメの分布がはっきりと見えるようになるんです!
重要な専門用語をマスターしよう
データを凝縮する過程で出てくる、かっこいい言葉を解説します。
次元(じげん)
機械学習では、特徴量の数のことを指します。アヤメは4つの数値があるので「4次元」です。次元が増えすぎると、データがスカスカになって計算がうまくいかなくなる「次元の呪い」という現象が起きることもあります。
主成分分析(PCA)
たくさんの特徴量を、情報の損失をできるだけ少なくしながら、より少ない数の新しい指標(主成分)にまとめる手法です。
寄与率(きよりつ)
凝縮した後の新しい指標が、もとの情報の何パーセントを説明できているかを表す数字です。
例えば、第1主成分の寄与率が 
プログラムで情報を凝縮してみよう
実際に4つの特徴量を2つに減らして、グラフに描ける形にしてみましょう。
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
# 2次元に圧縮するモデルを作成
pca = PCA(n_components=2)
# データを圧縮(標準化したデータを使うのが鉄則です!)
X_pca = pca.fit_transform(X_train_scaled)
# 圧縮後のデータの形を確認
print(f"元の形: {X_train_scaled.shape}")
print(f"圧縮後の形: {X_pca.shape}")
# 情報がどれくらい保たれているか確認
print(f"各主成分の寄与率: {pca.explained_variance_ratio_}")実行すると、データの列が
寄与率を見てみてください。第1主成分と第2主成分を合わせるだけで、アヤメの情報のほとんどをカバーできていることに驚くはずです!
次元の圧縮のメリットとデメリット
メリット
- データの可視化ができる:人間は3次元までしか見ることができませんが、2次元に落とし込むことで、データの構造を自分の目で確認できるようになります。
- 計算が速くなる:情報の「ゴミ」を削ぎ落として本質だけに絞るため、その後の学習スピードが向上します。
デメリット
- 意味が分かりにくくなる:元の「花びらの長さ」といった具体的な意味が消え、「第1主成分」という抽象的な数字になってしまいます。
- 情報が少し失われる:
今回のまとめと今後の指針
第9回では、複雑なデータをシンプルにする次元圧縮を学びました。
これで、どれだけ大量の特徴量があっても、その本質を抜き出す術を手に入れましたね!
さて、全10回の連載もいよいよ次が最終回です。
これまで学んできたバラバラの技術を一つの流れにまとめ、実戦で使える「自動予測システム」を完成させましょう。
最終回は、第10回「実戦投入!モデルの運用とパイプライン」です。
4次元の世界を2次元にギュッと縮めてみた感想はどうですか?
「情報の断捨離」を終えたところで、最後に最高のアヤメ鑑定システムを組み上げましょう!
こんにちは。ゆうせいです。
ついに、全10回にわたるアヤメの冒険も最終回を迎えました!
これまでに、データの観察から始まり、近所付き合いのような分類、脳を模したネットワーク、そして情報の断捨離まで、数多くの武器を手に入れてきましたね。
最終回となる第10回は、これらのバラバラな工程を一つに束ね、誰でも簡単に使える「自動予測システム」として完成させる方法を学びましょう。プロの現場で欠かせない「パイプライン」という考え方をご紹介します!
職人の技を自動化する!パイプラインの仕組み
機械学習の作業は、実は「学習」そのものよりも、その前後の準備に時間がかかります。
- データを読み込む
- 単位を揃える(標準化)
- 情報を凝縮する(次元圧縮)
- AIに予測させる(モデル)
これらを毎回手作業で行うのは大変ですし、うっかりミスも起きやすくなります。
そこで登場するのが、パイプラインです。
パイプラインとは、一連の処理をベルトコンベアのように連結する仕組みのことです。一度このラインを作ってしまえば、新しいアヤメのデータを流し込むだけで、標準化から予測までが自動的に行われ、最後には「品種名」がコロリと出てくるようになります!
重要な専門用語をマスターしよう
システムを運用する際に、エンジニアがよく使う言葉を解説します。
パイプライン
複数の処理工程を一本の管(パイプ)のように繋ぎ、ひとつのオブジェクトとして扱う仕組みです。これを使うことで、コードが驚くほどスッキリし、再利用も簡単になります。
推論(すいろん)
学習が終わったモデルを使って、新しい未知のデータに対して答えを出すことです。
「学習」が勉強なら、「推論」は本番のテストに回答する作業と言えますね。
学習済みモデルの保存
苦労して育てたAI(モデル)は、ファイルとして保存しておくことができます。
次に使いたいときは、わざわざ学習し直さなくても、保存したファイルを読み込むだけですぐに「鑑定士」として復帰させることができるのです。
プログラムで自動予測システムを完成させよう!
それでは、標準化とSVMをセットにしたパイプラインを構築してみましょう。
from sklearn.pipeline import Pipeline
from sklearn.svm import SVC
from sklearn.preprocessing import StandardScaler
import joblib
# 工程をリストにする(標準化してからSVMを実行!)
estimators = [
('scaler', StandardScaler()),
('classifier', SVC(kernel='rbf', probability=True))
]
# パイプラインの作成
pipe = Pipeline(estimators)
# 一気に学習!
pipe.fit(X_train, y_train)
# 新しいアヤメのデータ(適当な数値)を入力してみる
new_data = [[5.1, 3.5, 1.4, 0.2]]
prediction = pipe.predict(new_data)
print(f"このアヤメの品種は: {iris.target_names[prediction][0]} です!")
# モデルを保存する(これでいつでも呼び出せます)
joblib.dump(pipe, 'iris_model.pkl')
これで、あなたは「データの処理方法」と「賢いAI」を丸ごと一つのファイルに詰め込みました。このファイルさえあれば、Webアプリやスマートフォンアプリに組み込んで、世界中の人に使ってもらうことも可能なんですよ!
パイプライン運用のメリットとデメリット
メリット
- ミスがなくなる:学習時と推論時で、データの処理方法がズレてしまう「訓練・推論の不一致」を防げます。
- コードの可読性:複雑な工程を
fitやpredictという短い言葉で管理できるため、後から見返しても分かりやすいです。
デメリット
- デバッグが少し大変:一本の管になっているため、途中でどんな数値になっているかを覗き見るには、少しコツが必要になります。
- 柔軟性の低下:非常に特殊な処理を差し込みたい場合、パイプラインの枠組みに合わせるための工夫が必要になることがあります。
完結!これからの学習の指針
全10回の連載、本当にお疲れ様でした!
最初はただの数字の羅列にしか見えなかったアヤメのデータが、最後にはAIを動かすための貴重な資源に見えてきたのではないでしょうか。
ここまでの旅を終えたあなたには、もう機械学習の基礎体力が十分に備わっています。
これからのステップとして、以下のことに挑戦してみてください。
- 他のデータセットに挑戦:Scikit-learnには、住宅価格を当てるデータや、手書き数字を認識するデータも入っています。今回の知識は、それらにもそのまま応用できます。
- コンペティションに参加:「Kaggle」などのサイトでは、世界中の人が精度を競っています。まずは簡単な課題から覗いてみてください。
- 自分のデータを解析:身近なExcelデータなどを読み込んで、自分なりの予測システムを作ってみるのが一番の近道です。
機械学習の道は、ここで終わりではなく、ここからがスタートです。
あなたがこれから、どんな面白い「発見」をデータから導き出すのか、私は楽しみにしています!
次は、アヤメ以外のどんなデータを解析してみたいですか?
もし新しいテーマが決まったら、また一緒に冒険を始めましょう!
セイ・コンサルティング・グループでは新人エンジニア研修のアシスタント講師を募集しています。
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。
最新の投稿
 山崎講師2026年8月1日コンピューターが数値計算の誤差に対処する仕組みと精度管理の方法
山崎講師2026年8月1日コンピューターが数値計算の誤差に対処する仕組みと精度管理の方法- 山崎講師2026年8月1日0乗が1になる理由を2乗の計算式から解説する指数法則の基礎
- 山崎講師2026年8月1日機械学習モデルの予測理由を解釈するSHAPとシャープレイ値の基礎
- 山崎講師2026年8月1日適合率と再現率の概念と初心者向けのわかりやすい再翻訳案

