
機械学習の心臓部!勾配降下法の更新則を世界一やさしく解説します
 山崎講師
山崎講師こんにちは。ゆうせいです。
「機械学習って、どうやって賢くなっているの?」
そんな風に思ったことはありませんか?
たくさんのデータから自動で学習する賢いコンピュータ。その学習プロセスの中心には、実は「勾配降下法(こうばいこうかほう)」という考え方があります。
今回は、その勾配降下法の中でも特に重要な「更新則」という数式について、一緒に見ていきましょう。一見すると難しそうですが、一つ一つの意味がわかれば、きっと「なるほど!」と思えるはずです。
そもそも勾配降下法ってなに?
数式を見る前に、まずは勾配降下法が何を目指しているのか、イメージから掴んでみましょう。
あなたは今、深い霧に包まれた山の中にいると想像してください。あなたの目的は、とにかく一番低い谷底までたどり着くことです。しかし、霧で周りは全く見えません。
さて、どうすれば谷底にたどり着けるでしょうか?
おそらく、今いる場所で足元を確かめ、「一番傾きが急な下り坂」を探して、そちらへ一歩進むでしょう。そしてまた、その場で一番急な下り坂を探して一歩進む…。これを繰り返せば、いつかは谷底にたどり着けそうですよね?
この、「一番急な坂を下っていく」というシンプルなアイデアこそが、勾配降下法の本質です!
機械学習では、「間違いの大きさ」を山の高さに見立てます。そして、この間違いが最も小さくなる地点(谷底)を探すために、勾配降下法を使って間違いという名の山を少しずつ下っていくのです。
謎の数式「更新則」を分解してみよう!
では、いよいよ本日の主役である「更新則」の式を見てみましょう。先ほどの山下りの一歩を、数式で表したものがこちらです。

うーん、記号だらけでアレルギーが出そうですね…。大丈夫!一つずつ、ゆっくりと分解していくので安心してください。
w:「現在の位置」を示すパラメータ
まず、wです。これは「パラメータ」と呼ばれ、機械学習モデルの賢さを調整するための「つまみ」のようなものだと考えてください。先ほどの山登りの例で言えば、あなたの「現在の位置」を表します。このwの値を少しずつ動かして、最適な場所(谷底)を探していくわけです。
f(w):「現在の高さ」を測るコスト関数
f(w)は「コスト関数」や「損失関数」と呼ばれます。これは、現在の位置wが、どれくらい谷底から離れているか、つまり「間違いの大きさ」を計算する関数です。山の例で言えば、あなたのいる場所の「標高(高さ)」を教えてくれるものですね。このf(w)の値が小さければ小さいほど、正解に近いということになります。
∂f(w)/∂w:「坂の傾き」を教えてくれる勾配
さて、ここが一番のポイントです。
この分数の形をした記号は、「wにおけるf(w)の勾配(こうばい)」を表しています。
「勾配」とは、ずばり「坂の傾き」のことです。
- この値がプラスの大きな値なら、右肩上がりの急な上り坂。
- この値がマイナスの大きな値なら、右肩下がりの急な下り坂。
- この値が0なら、平坦な場所。
つまり、この勾配を調べることで、今いる場所がどれくらい傾いているのか、そしてどちらの方向が「上り」なのかが分かるのです。
η:「歩幅」を決める学習率
このη(イータと読みます)は、「学習率」と呼ばれるものです。これは、坂を下るときの一歩の「歩幅」を決めます。
ηが大きいと、一歩で進む距離が長くなります(大胆に進む)。ηが小さいと、一歩で進む距離が短くなります(慎重に進む)。
この歩幅はとても重要で、大きすぎると谷底を飛び越えてしまったり、小さすぎると谷底にたどり着くまでに時間がかかりすぎたりします。ちょうど良い歩幅を見つけるのが、腕の見せ所なのです。
式全体をもう一度!
もう一度、全体の式を見てみましょう。
これを日本語に翻訳すると、こうなります。
「新しい位置(
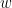


ここで一つ疑問が湧きませんか? なぜ、引き算(–)なのでしょうか。
先ほど、勾配は「上り坂の方向」を指し示すと言いました。私たちの目的は山を「下る」ことですよね。だから、上り坂とは「逆の方向」に進むために、引き算をするのです。これで、いつでも谷底に向かって進むことができますね!
勾配降下法のメリット・デメリット
この便利な勾配降下法にも、得意なことと苦手なことがあります。
メリット
- シンプルで分かりやすい: 考え方が非常に直感的で、プログラムとして実装するのも比較的簡単です。
- 多くの問題でうまくいく: 様々な機械学習アルゴリズムの基礎となっており、非常にパワフルです。
デメリット
- 局所解に陥る可能性: もし山に谷が複数あった場合、一番低い「本当の谷底(大域的最適解)」ではなく、途中にあった小さな「偽物の谷(局所的最適解)」にハマってしまうことがあります。
- 学習率の調整が難しい: 歩幅である学習率
ηを適切に設定するのが難しく、職人技が求められることもあります。
次に学ぶべきこと
勾配降下法の基本的な考え方が分かったら、次の一歩に進んでみましょう!
- 確率的勾配降下法 (SGD): データが非常に大きい場合に、より高速に学習するための工夫がされた手法です。
- AdamやRMSpropなどの最適化アルゴリズム: 学習率を自動で調整してくれる、より賢い勾配降下法の仲間たちがたくさんいます。
これらのキーワードで調べてみると、さらに機械学習の奥深い世界が広がっていきますよ。
今回は数式を解説しましたが、一番大切なのは「間違いを少しでも小さくするために、坂道を一歩ずつ下っていく」というイメージを掴むことです。このイメージさえ持っていれば、これから先、より複雑なアルゴリズムに出会ったときも、きっと理解の助けになるはずです!
セイ・コンサルティング・グループの新人エンジニア研修のメニューへのリンク
投稿者プロフィール

