
機械学習の"ご先祖様"?重回帰分析が今も最強の「基礎」である理由
 山崎講師
山崎講師こんにちは。ゆうせいです。
機械学習の勉強を始めると、AIやディープラーニングといった華やかな言葉に目が行きがちですよね。しかし、その前に必ずと言っていいほど登場するのが「重回帰分析(じゅうかいきぶんせき)」という、なんだか難しそうな統計用語です。
「え、それって機械学習なの? 古い統計学の話じゃないの?」
新人エンジニアのあなたも、そう感じているかもしれません。
その通り! 重回帰分析は、統計学の世界で古くから使われてきた、伝統ある分析手法です。
しかし、同時に、これこそが現代の機械学習の「最も基本的で、最も重要なモデルの一つ」であり、いわば "ご先祖様" のような存在なんです。
今日は、なぜこの「古い」手法が今もなお現役で、すべてのエンジニアが学ぶべき「基礎体力」なのか、その関係性を解きほぐしていきますね。
そもそも「重回帰分析」って何?
まず、「回帰」という言葉からいきましょう。
「回帰」とは、ざっくり言えば「ある数値(結果)を、別の数値(原因)から予測すること」です。
例え:家の価格を予測する
もし、あなたが「家の広さ」 だけ を使って「家の価格」を予測しようとしたら。
これは原因が1つなので「単回帰分析」と呼びます。シンプルですね。
でも、現実の家の価格って、「広さ」だけで決まりますか?
決まりませんよね。「駅からの距離」や「築年数」も、ものすごく影響しそうです。
このように、予測したい結果(これを 目的変数 と言います)に対して、影響を与えそうな原因(これを 説明変数 と言います)を 2つ以上 使って予測する手法。
それが「重回帰分析」の「重(Multiple=複数の)」たるゆえんです。
- 目的変数(予測したい結果):家の価格
- 説明変数(予測に使う原因):
- 広さ
- 駅からの距離
- 築年数
- ...など複数
重回帰分析の「シンプルな仕組み」
では、重回帰分析はどうやって予測しているのでしょう?
「AIみたいに、中で複雑な計算が…?」と思うかもしれませんが、実は驚くほどシンプルです。
その正体は、私たちが中学1年生で習った「一次関数」の進化系なんです。
覚えていますか? 
「単回帰」は、まさにこれです。(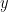

「重回帰」は、説明変数(

この式に、先ほどの家の例を当てはめてみましょう。




そして、

重回帰分析の「学習」とは、たくさんの過去のデータ(実際の家の価格と、その広さや駅からの距離など)を使って、この

重回帰分析と機械学習の「関係」
「データからパターンを学習し、未知のデータに対して予測を行うモデルを作る」
これこそが、機械学習(の中の「教師あり学習」)の定義そのものです。
重回帰分析は、この定義にピタリと当てはまりますよね?
そう、重回帰分析は、予測する結果が「数値」である「回帰問題」を解くための、最も基本的で、最も古い機械学習アルゴリズムの一つなんです。
ディープラーニングのような複雑なモデルも、その基本要素を分解していくと、「入力(データ)に重み(係数)をかけて足し合わせる」という、この重回帰分析とそっくりな計算を、何層にも何層にも重ねているに過ぎません。
重回帰分析を理解することは、複雑なAIモデルを理解するための、まさに「第一歩」なんです。
なぜ「ご先祖様」が今も現役なのか?
では、なぜディープラーニングのような高性能モデルがあるのに、今さら重回帰分析を学ぶ必要があるのでしょう?
それは、重回帰分析にしかない「最強のメリット」があるからです。
メリット1:解釈可能性が「神」
これが最大の理由です!
複雑なAIモデル(例えばディープラーニング)は、高い予測精度を出すのが得意ですが、「なぜAIがその予測結果を出したのか?」を人間に説明するのが非常に難しい、という弱点があります。これを「ブラックボックス問題」と呼びます。
しかし、重回帰分析はどうでしょう?
学習が終われば、「最適な 
例えば、
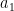

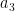
この数値を見ただけで、私たちは「ああ、なるほど!」と結果を「解釈」できます。
「広さが1平米増えると、価格が50万円上がる傾向があるな」
「駅からの距離が1分遠くなると、価格が100万円下がる傾向があるな」
ビジネスの現場では、「AIが予測しました(理由は謎です)」という報告より、「駅からの距離が、これだけ価格に影響しています!」と説明できることの方が、何倍も価値があるケースが多いのです。
メリット2:シンプルで超高速
計算が非常にシンプルなので、学習も予測もめちゃくちゃ速いです。
まずは「ベースライン(最低限の基準点)」として重回帰分析をサッと試してみる、というのは、プロのデータサイエンティストが必ず行う手順ですよ。
重回帰分析の「弱点(限界)」
もちろん、万能ではありません。弱点も知っておきましょう。
- 「線形」の関係しか捉えられない「肥料をやりすぎると収穫が減る」のような、山なりの関係(非線形な関係)を予測するのは苦手です。(常に直線で予測しようとしてしまいます)
- 複雑な「データの絡み合い」が苦手「広くて、 かつ 、駅チカ」のときにだけ価格が爆上がりする、といった特徴同士の複雑な相互作用を自動で見つけるのは苦手です。
- 「似た者同士」に弱い相関分析でも出た「多重共線性」の問題です。「広さ(平方メートル)」と「広さ(坪)」のように、そっくりな説明変数を一緒に入れると、計算が不安定になり、係数の解釈がおかしくなります。
まとめと次のステップ
重回帰分析は、「古い統計手法」と切り捨てるのではなく、「シンプルで、解釈性が抜群に高く、今も現役の機械学習モデル」だと理解してください。
複雑なモデルが常に最良とは限りません。
「解釈できること」に価値がある場面で、重回帰分析はあなたの強力な武器であり続けます。
次のステップ
- 触ってみよう!難しそうな数式に圧倒されず、まずは触ってみましょう。Pythonの scikit-learn というライブラリにある LinearRegression を使えば、ほんの数行のコードで重回帰分析を実行できます。
- 「ロジスティック回帰」を学ぼう!重回帰分析の考え方を応用して、「合格/不合格」や「購入する/しない」といった「Yes/No」の予測(分類問題)を解く手法が「ロジスティック回帰」です。これも機械学習の超基本かつ最重要アルゴリズムです。
- 「正則化」を知ろう重回帰分析が、複雑なデータに無理やりフィットしようとして予測精度が落ちる「過学習」という状態を防ぐためのテクニックがあります。「Ridge回帰」や「Lasso回帰」と呼ばれる手法も知っておくと、さらに一歩進めますよ。
基本を制する者が、機械学習を制します。頑張っていきましょう!
セイ・コンサルティング・グループの新人エンジニア研修のメニューへのリンク
投稿者プロフィール

