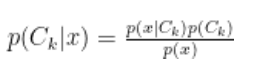【NumPy応用】乱数を操る!choiceとshuffleを使いこなして脱・初心者を目指そう
 山崎講師
山崎講師こんにちは。ゆうせいです。
前回の記事では、NumPyの乱数生成の基本である「3つの神器(rand, randn, randint)」と、再現性を保つための「シード値」についてお話ししました。
「サイコロを振る」ような単純な乱数はもう作れるようになりましたね。
でも、実際のデータ分析やAI開発の現場では、もう少し複雑な操作が求められることがあります。
例えば、「トランプのカードを切るようにデータを混ぜたい」とか、「当たりが出やすいインチキなクジ引きを作りたい」といった場面です。
今日は、そんな「一歩進んだ乱数操作」を実現するための、超重要メソッドたちを解説します。とくに shuffle と permutation の違いは、ベテランでもうっかり間違える落とし穴なので、ここでしっかりマスターしておきましょう!
1. 確率を操るクジ引き「choice」
最初にご紹介するのは choice (チョイス)です。
これは名前の通り、用意されたデータの中から「選ぶ」ためのメソッドです。
randint が「数字」を作り出すのに対し、 choice は「リストや配列の中身」から選び出します。これのすごいところは、ただ選ぶだけでなく「確率(重み)」を自分で決められる点です。
復元抽出と非復元抽出
ここで少し専門的な話をします。箱の中からボールを引く場面を想像してください。
- 復元抽出(ふくげんちゅうしゅつ): 引いたボールを箱に戻してから、次を引く。同じボールが何度も選ばれる可能性があります。
- 非復元抽出(ひふくげんちゅうしゅつ): 引いたボールは箱に戻さない。一度選ばれたボールは二度と出てきません。
choice メソッドは、 replace (置き換え)というオプションを切り替えるだけで、この二つを使い分けることができます。
replace=True(デフォルト): ボールを戻す(重複あり)replace=False: ボールを戻さない(重複なし)
「重複なし」を使えば、ビンゴ大会の数字選びのようなことができますね。
確率の重み付け
さらに、 p というオプションを使えば、「アタリは10%、ハズレは90%」のように、出る確率を操作できます。
- 使い道: データのクラス不均衡(正例が少なくて負例が多いなど)を調整したり、強化学習で「強い行動を選びやすくする」といった処理に使われます。
2. 混ぜる技術「shuffle」と「permutation」
次は、データを混ぜる(シャッフルする)メソッドです。
機械学習では、学習データをランダムな順番に並べ替えることが非常によくあります。データに並び順の偏りがあると、AIが変なクセを覚えてしまうからです。
ここで登場するのが shuffle (シャッフル)と permutation (パーミュテーション)です。
この二つ、やっていることは「混ぜる」で同じなのですが、「元のデータを壊すかどうか」という決定的な違いがあります。
破壊的な「shuffle」
shuffle は、渡されたデータそのものを書き換えて混ぜてしまいます。これを「破壊的変更」と呼びます。
元の綺麗な並び順は消えてなくなります。メモリを節約できるメリットはありますが、「元のデータも残しておきたい」というときには使えません。
非破壊的な「permutation」
permutation は、元のデータはそのままにしておいて、「混ぜたあとの新しいコピー」を作って返してくれます。
元のデータも残るし、新しい混ぜたデータも手に入ります。安全ですが、データ量が多いとメモリを余分に使うことになります。
- 覚え方:
shuffleは「その場で混ぜる」、permutationは「混ぜたコピーを作る」。
3. オーダーメイドな分布「normal」と「uniform」
最後は、基本編で紹介した randn や rand の「上位互換」とも言えるメソッドです。
randとuniform: どちらも均一な乱数ですが、randはから
固定です。一方
uniformは、「から
の間で」のように範囲を自由に指定できます。
randnとnormal: どちらも正規分布ですが、randnは平均normalは、「平均、標準偏差
実務では、細かい設定ができるこちらのメソッドを使うことのほうが多いかもしれません。
実際のコードで違いを体感しよう
それでは、Pythonのコードで動きを確認してみましょう。
とくに shuffle と permutation の違いに注目してください。
import numpy as np
# シードを固定(再現性のため)
np.random.seed(42)
# --- 1. choice の例 ---
items = ['松', '竹', '梅']
# 復元抽出(重複あり)で5回引く
print("--- choice (重複あり) ---")
print(np.random.choice(items, 5))
# 重み付け(梅が出やすくする)
# 松:10%, 竹:10%, 梅:80%
print("\n--- choice (確率操作) ---")
print(np.random.choice(items, 10, p=[0.1, 0.1, 0.8]))
# --- 2. shuffle と permutation の違い ---
data_A = np.array([1, 2, 3, 4, 5])
data_B = np.array([1, 2, 3, 4, 5])
# permutation(非破壊的)
shuffled_data = np.random.permutation(data_A)
print("\n--- permutation ---")
print(f"返り値: {shuffled_data}")
print(f"元のデータ: {data_A} (変わっていない!)")
# shuffle(破壊的)
# 返り値はありません(Noneになります)
np.random.shuffle(data_B)
print("\n--- shuffle ---")
print(f"元のデータ: {data_B} (書き換わっている!)")
# --- 3. normal の例 ---
# 平均50、標準偏差10の正規分布(偏差値のようなデータ)
print("\n--- normal ---")
print(np.random.normal(loc=50, scale=10, size=5))
メリットとデメリット
今回紹介したメソッドの良い点と注意点です。
メリット
- 柔軟性: ただの乱数ではなく、「確率」や「分布の形」をコントロールできるため、現実世界に近いシミュレーションが可能になります。
- データ前処理の効率化:
shuffleなどは、機械学習のモデルにデータを投入する直前の処理として必須級の機能です。
デメリット
- 破壊的変更の罠:
shuffleをうっかり使ってしまい、「元のデータが消えてしまった!」というバグは初心者が必ず通る道です。基本的にはpermutationを使うか、コピーをとってからshuffleするクセをつけましょう。 - 計算コスト:
choiceで確率の重み付け計算を大量に行うと、単純な乱数生成よりは処理時間がかかります。
今後の学習の指針
ここまで読んでいただき、ありがとうございます。
これであなたは、単にサイコロを振るだけでなく、イカサマサイコロを作ったり、トランプを華麗にシャッフルしたりする技術を手に入れました。
次のステップとしては、これらを組み合わせて簡単なシミュレーションを作ってみるのがおすすめです。
例えば、「勝率60%のジャンケンAIと100回戦ったら、何回勝てるか?」などを choice を使って計算してみてください。
また、もし「もっと新しい書き方を知りたい」という意欲的な方は、NumPyの公式ドキュメントにある default_rng() を使ったGenerator(ジェネレータ)方式も調べてみてください。今日学んだメソッド名(choice, shuffleなど)がそのまま使えますよ。
それでは、また次の記事でお会いしましょう。
セイ・コンサルティング・グループの新人エンジニア研修のメニューへのリンク
投稿者プロフィール