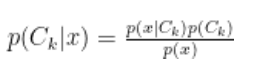生成モデル、識別モデル、識別関数の違い
 山崎講師
山崎講師AIの世界へようこそ!
機械学習を学び始めると、「モデル」という言葉が何度も出てきますよね。
特にE資格でも重要なのが、データをどう扱うかというスタンスの違いである「生成モデル」「識別モデル」「識別関数」の3つです。
これらは、いわば「犯人探し」のアプローチの違いのようなものです。
今日は、この3つの違いをスッキリ整理していきましょう!
生成モデル、識別モデル、識別関数の違い
こんにちは。ゆうせいです。
新人エンジニアのみなさん、例えば「この写真は犬か猫か?」を判定するAIを作るとします。
このとき、AIに「犬とは何か、猫とは何か」を根本から教え込むのか、それとも「犬と猫の境界線」だけを教えるのか。
この戦略の違いが、モデルの種類を決めるんです。
それぞれの特徴を、直感的に理解できるように解説しますね。
1. 生成モデル(Generative Model)
「正解のデータがどうやって作られるか」まで学習する
生成モデルは、データ 


簡単に言うと、「犬ならこんな見た目になるはずだ」というデータの成り立ち(背景)を完璧にマスターしようとするエリートタイプです。
- 特徴: データの分布を学習するため、新しいデータを「生成」することも可能です。
- 例え: 料理に例えると、レシピ(材料と手順)をすべて覚えるようなものです。レシピを知っていれば、自分で料理を作ることもできますし、出された料理がどのレシピで作られたかも当てられますよね。
- 代表例: ナイーブベイズ、隠れマルコフモデル、GAN(敵対的生成ネットワーク)
2. 識別モデル(Discriminative Model)
「データが与えられたとき、どのクラスに近いか」を直接考える
識別モデルは、あるデータ 
「なぜそうなるか」という背景よりも、「今目の前にあるデータが、どのクラスに属する確率が高いか」という結果を重視する実利的なタイプです。
- 特徴: 生成モデルよりも境界線を引くのが得意で、一般的に分類精度が高くなりやすいです。
- 例え: 料理のレシピは知らないけれど、味見をして「これは 80% の確率でカレーだ!」と判定するようなものです。
- 代表例: ロジスティック回帰、条件付き確率場(CRF)
3. 識別関数(Discriminant Function)
「確率なんて関係ない!境界線はここだ!」とズバッと決める
識別関数は、確率(パーセント)を計算しません。
入力データ 
- 特徴: 「何%の確率で正解か」という曖昧さを排除し、とにかく境界線を引くことだけに特化しています。
- 例え: 料理を一口食べて、一切悩まずに「これはカレー!」と断定する、頑固な職人のようなイメージです。
- 代表例: サポートベクターマシン(SVM)、パーセプトロン
メリットとデメリットの比較
それぞれのモデルには、得意・不得意があります。
| 分類 | メリット | デメリット |
| 生成モデル | 未知のデータを生成できる。データが少なくても学習が進みやすい。 | 学習が複雑になりやすく、分類精度が識別モデルに劣ることがある。 |
| 識別モデル | 分類精度が高い。データが大量にある場合に非常に強力。 | データの背景(生成プロセス)については何も教えてくれない。 |
| 識別関数 | 計算がシンプルで、境界線を引くことに特化している。 | 出力の信頼度(どれくらい自信があるか)が数値として得られない。 |
違いを整理する質問
みなさんに質問です。
「偽造硬貨を見抜くAI」を作るとき、どちらのアプローチが安心でしょうか?
- 本物の硬貨の模様や重さのルール(生成プロセス)を完璧に覚えさせる
- 本物と偽物の「違い」だけを徹底的に覚えさせる
実は、どちらも正解です。
しかし、本物の硬貨を新しく作りたいなら「1」の生成モデルが必要になりますし、とにかく偽物を弾く精度を上げたいなら「2」の識別モデルが向いています。
このように、目的によって使い分けるのがエンジニアの腕の見せ所です!
今後の学習の指針
この3つの違いがわかったら、次のステップとしてこれらを詳しく学んでみてください。
- ベイズの定理の再確認: 生成モデルがどうやって「逆向きの確率」を計算しているか、数式で追ってみる。
- ソフトマックス関数: 識別モデルがどうやって「合計 100% 」の確率を出力しているか調べる。
- SVMのカーネル法: 識別関数が、複雑な境界線をどうやってシンプルに引いているか(ワープの魔法)を学ぶ。
この分類の概念は、E資格の試験でも「この手法はどのモデルに分類されるか」という形でよく問われます。
まずは「背景を知るエリート(生成)」「確率で選ぶ実利派(識別)」「ズバッと決める職人(関数)」というイメージを定着させてくださいね。
セイ・コンサルティング・グループの新人エンジニア研修のメニューへのリンク
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。