AIの学習効率が劇的アップ!「誤差逆伝播法」は責任追求の伝言ゲーム
 山崎講師
山崎講師こんにちは。ゆうせいです。
前回は、AIがゴール(正解)に向かってパラメータを修正していく「勾配降下法」について学びました。
山を下るように、少しずつ誤差を減らしていくんでしたね。
しかし、ここで大きな問題があります。
最近のAI(ディープラーニング)は何十、何百もの層が重なり、パラメータの数は数億個にも及びます。
この膨大なパラメータ一つひとつに対して、「君を右に回したら誤差は減るの?それとも増えるの?」といちいち確認していたら、計算が終わるのに何百年もかかってしまいます。
そこで発明されたのが、今回のテーマ「誤差逆伝播法(ごさぎゃくでんぱほう)」です。
英語では「バックプロパゲーション(Backpropagation)」と呼ばれます。
名前はいかついですが、前回お伝えした通り、やっていることは「責任のなすりつけ合い」です(笑)。
この手法のおかげで、AIは驚異的なスピードで学習できるようになったのです。
一体どういう仕組みなのか、紐解いていきましょう。
誤差逆伝播法ってなに?
一言で言うと、「出力層で出た『誤差』を、入力層に向かって逆向きに伝え、各パラメータがその誤差にどれくらい責任があるかを計算する方法」です。
通常、AIは「入力 
しかし、学習(反省)するときは、「出力
「伝言ゲーム」で考えよう
イメージしやすいように、5人で「伝言ゲーム」をしていると想像してください。
- 先頭の人が絵を見て、次の人に言葉で伝えます。
- 順に伝えていき、最後の人が「ゴリラ!」と答えました。
- でも正解は「リンゴ」でした。大失敗です。
さて、誰が悪かったのでしょうか?
これを調べるために、後ろから順に問い詰めていきます(これが逆伝播です)。
- 審判:「おい、最後の人!なんでゴリラって言ったんだ?」
- 最後の人:「いや、4番目の人が『ゴリラっぽい果物』って言ったからです!」
- 4番目の人:「いや、3番目の人が『強そうな果物』って伝えてきたからです!」
- 3番目の人:「いや、2番目の人が...」
こうやって、最後の結果から逆順にたどっていくことで、「誰が、どのくらい話をねじ曲げたか(=どのパラメータが誤差の原因か)」を効率よく特定できるのです。
数学的なカギ:「連鎖律(チェーンルール)」
この「責任の分配」を数学的に支えているのが、高校数学で習う微分の「連鎖律(チェーンルール)」というルールです。
影響の連鎖は「掛け算」で求まる
例えば、こんなドミノ倒しのような関係があるとします。
- スイッチAを回すと、歯車Bが回る。
- 歯車Bが回ると、タイヤCが回る。
もし、「スイッチAを少し動かしたとき、タイヤCはどれくらい動くか?」を知りたければ、次のように計算できます。
(AがBに与える影響) 
つまり、個別の影響力を掛け算すれば、全体の影響力がわかるというルールです。
ニューラルネットワークもこれと同じです。
「出力の誤差」に対する「あるパラメータの影響」を知りたければ、出力からそのパラメータまでの経路にある「微分(傾き)」を全部掛け算すればいいのです。
いちいちシミュレーションしなくても、掛け算だけで一発で責任の重さが求まってしまう。
これが数学の魔法です。
なぜ機械学習で重要なのか
誤差逆伝播法がなければ、現在のAIブームは起きていなかったと言われるほど重要です。
1. 計算速度が圧倒的に速い
もしこの方法を使わずにパラメータを調整しようとすると、「数値微分」という方法を使うことになります。
これは、「あるパラメータを 
パラメータが1億個あれば、1億回計算し直しです。気が遠くなりますよね。
誤差逆伝播法なら、たった一回の「逆走(バックパス)」の計算だけで、1億個すべてのパラメータの修正量を同時に求めることができます。
計算効率が何万倍、何億倍も違うのです。
2. 深い層でも学習できる
昔のAIは、層を深くすると入口付近のパラメータまで誤差情報が届かず、学習がうまく進まないという悩みがありました。
しかし、この手法(と活性化関数の工夫など)によって、誤差を入口までスムーズに伝えることが可能になり、ディープラーニング(深層学習)が実現したのです。
デメリット(弱点)
万能に見える誤差逆伝播法にも、弱点はあります。
それは、「層が深すぎると、誤差が途中で消えてしまうことがある」という点です。
掛け算を繰り返す性質上、
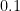

これを「勾配消失(こうばいしょうしつ)問題」と呼びます。
「入力層の人」まで責任追及の声が届かなくなってしまうんですね。
これ防ぐために、前回紹介した「ReLU関数」などが使われています。
Pythonで確認してみよう
Pythonの人気ライブラリ「PyTorch」を使えば、この複雑な計算もたった一行で終わります。
本当に魔法の一行です。
import torch
# x(入力)と w(重みパラメータ)を定義
# requires_grad=True は「この変数の微分(勾配)を追跡してね」という合図
x = torch.tensor([1.0], requires_grad=False)
w = torch.tensor([2.0], requires_grad=True)
b = torch.tensor([3.0], requires_grad=True)
# AIの計算(順伝播): y = w * x + b
# 2 * 1 + 3 = 5
y = w * x + b
# 正解データ(本当は10になりたかった)
target = torch.tensor([10.0])
# 損失関数の計算(二乗誤差)
# (5 - 10)^2 = 25
loss = (y - target) ** 2
print(f"損失: {loss.item()}")
# ------------------------------------
# ここが誤差逆伝播法!
# ------------------------------------
loss.backward()
# これだけで、w と b をどう修正すべきか(勾配)が計算されています
print(f"wの勾配(修正の方向): {w.grad.item()}")
print(f"bの勾配(修正の方向): {b.grad.item()}")
# 出力例:
# 損失: 25.0
# wの勾配: -10.0
# bの勾配: -10.0
loss.backward() を呼び出すだけで、すべての裏計算が終わってしまいます。
エンジニアは、複雑な数式を自分で書く必要はなく、この仕組みを理解していればOKなのです。
まとめ
いかがでしたか。
誤差逆伝播法とは、出力から逆向きに誤差を伝え、連鎖律を使って一気に全パラメータの修正量を計算する超効率的なアルゴリズムでした。
「順伝播で予想し、逆伝播で反省する」。
AIはこのサイクルを高速で繰り返して、賢くなっているのです。
さて、これで「ニューラルネットワークの仕組み」における基礎知識はほぼ揃いました。
セイ・コンサルティング・グループの新人エンジニア研修のメニューへのリンク
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。