
4.1 ニューラルネットワークの学習の基本
この章では、人工知能の中核技術「ニューラルネットワーク」について、その仕組みと学習方法をわかりやすく解説していきます。
G検定では、言葉だけでなく「どうやって学習するのか?」「どこに課題があるのか?」といった理解が求められます。
ニューラルネットワークとは?
ニューラルネットワーク(Neural Network)とは、人間の脳の仕組みをヒントにしたアルゴリズムで、たくさんの「ノード(人工ニューロン)」がつながって情報を処理するモデルです。
例えるなら、たくさんの“ちいさな脳細胞”がネットワークの中で協力して、データを理解しようとしているイメージです。
単純パーセプトロン:ニューラルネットワークの原点
まずは、最も基本的な「単純パーセプトロン(Perceptron)」から見てみましょう。
単純パーセプトロンは、入力と重みをかけて足し合わせ、しきい値を超えたら「1」、そうでなければ「0」を出力するシンプルな構造です。

これはまさに、直線で分けられる問題(二値分類)にしか対応できません。
なお、単純パーセプトロンが脳のニューロンを模して造られたというのは有名なお話です。

多層パーセプトロン(MLP):より複雑な問題に対応
単純なパーセプトロンでは限界があります。そこで登場するのが、多層パーセプトロン(Multi-Layer Perceptron)です。
これは「入力層」「中間層(隠れ層)」「出力層」があり、複数の層でデータを段階的に処理する構造です。
図解イメージ:
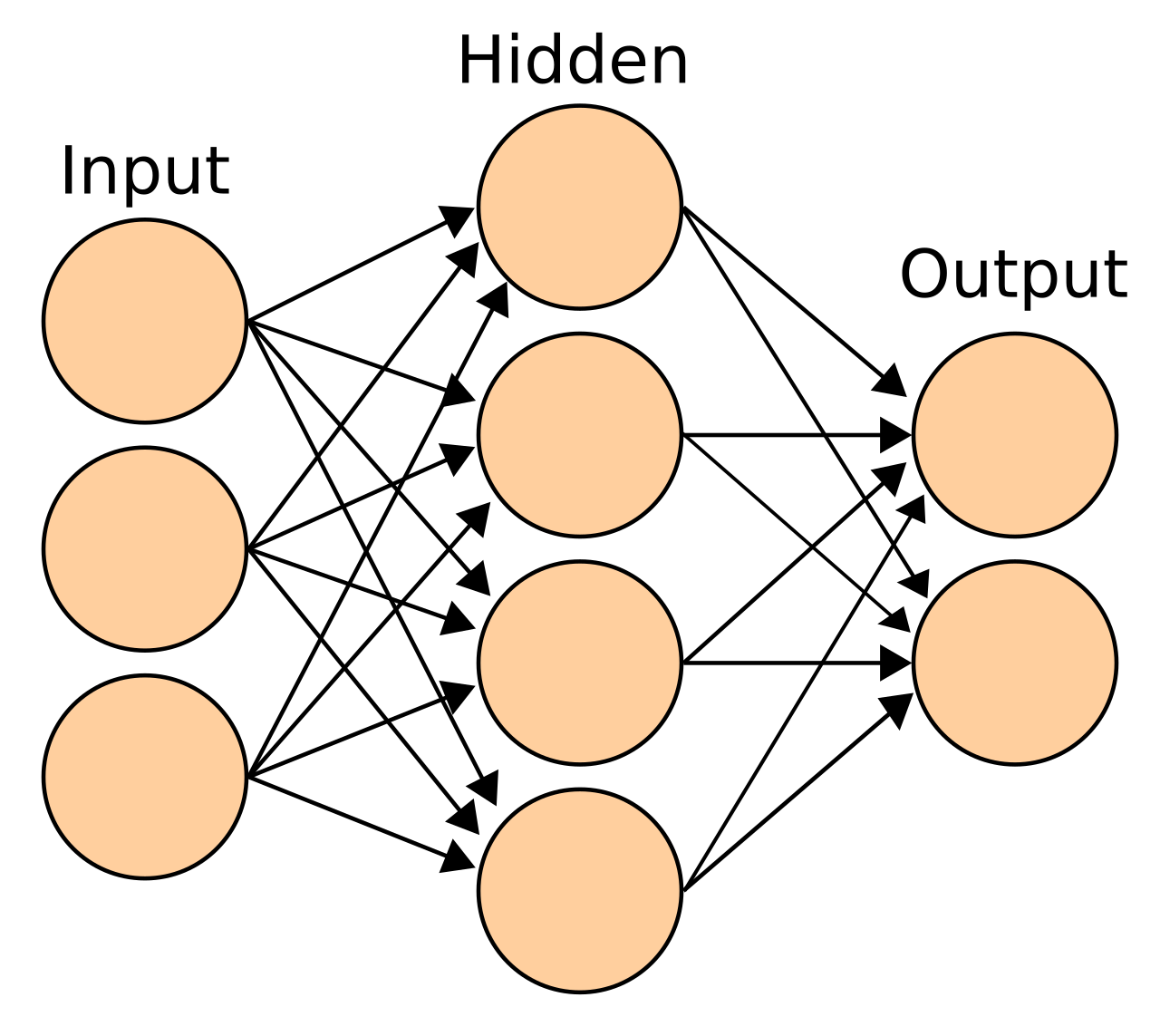
MLPによって、非線形な複雑な問題も解けるようになりました。
誤差逆伝播法(バックプロパゲーション)
学習は「正解と予測の差(誤差)」をもとに、パラメータ(重み)を更新することで行います。
このとき使われるのが誤差逆伝播法(Backpropagation)です。
この手法では、
- 出力層で誤差を計算
- その誤差を後ろから前へと伝搬
- 各層の重みを微分(勾配)に基づいて更新
このようにして、ネットワーク全体を調整していきます。
誤差逆伝播法は、ニューラルネットワークが間違いから学ぶためのしくみです。
例えるなら、テストで点数が悪かったときに「どこで間違えたか」を見直して、教科書をさかのぼって復習するようなものです。ネットワークでは、出力の誤差を使って、前の層へと少しずつ「ここが間違いの原因だったよ」と逆に伝えていきます。そして、その原因に合わせて重み(知識)を少しずつ修正していきます。これを何度も繰り返すことで、正しい答えを出せるようになるのです。まるで解き直しと復習を重ねて、成績を上げていく勉強法のようですね。
活性化関数:ニューロンを“活性化”させる関数
各ノードの出力を変形する関数を活性化関数(Activation Function)といいます。
これは「ニューロンを発火させるかどうか」の判断をする関数です。
主な活性化関数を見ていきましょう。
シグモイド関数(Sigmoid Function)

- 出力は0〜1の間
- 古くから使われているが、勾配が小さくなりやすく、学習が進まない問題がある(これを勾配消失問題という)
ハイパーボリックタンジェント関数(tanh関数)

- 出力は−1〜1
- シグモイドよりも中心が0に近く、勾配消失の影響がやや軽減される
ReLU関数(Rectified Linear Unit)

- 非常にシンプルかつ勾配消失しにくい
- ディープラーニングで現在最もよく使われる活性化関数
ソフトマックス関数(Softmax Function)
分類タスクの出力層で使われる関数。複数クラスに対する確率を出力します。

- 出力はすべて0〜1で、合計が1になる
- 「このクラスである確率」を表現できる
勾配消失問題とは?
ニューラルネットワークが深くなると、誤差を逆伝播するときに勾配がどんどん小さくなってしまう現象が起こります。
これを勾配消失問題といいます。
この問題が起きると、学習が途中で止まってしまうため、深いネットワークの学習が難しくなります。
対策として:
- ReLU関数の使用
- バッチ正規化
4.2 ニューラルネットワークの学習の仕組み
ここまではニューラルネットワークの基本構造や学習の流れを紹介しました。
ここではもう一歩踏み込み、ニューラルネットワークがどのようにして学習していくのか、その仕組みと工夫を見ていきましょう。
1. 勾配降下法と最適化の難しさ
ニューラルネットワークは、「出力」と「正解」の差(誤差)を最小にするために、重みパラメータを少しずつ調整して学習していきます。
そのとき使われる代表的な手法が、勾配降下法(Gradient Descent)です。
数式:

ここで:
:パラメータ(重みなど)
:学習率(learning rate)
:損失関数の勾配
学習がうまく進まない原因
最小値に向かう途中で、次のような「落とし穴」に引っかかることがあります。
- 局所最適解(Local Minimum):本当の最小値(大域最適解)ではないが、それ以上改善されないポイント
- 鞍点(Saddle Point):すべての方向で勾配が0になるが、最小値ではない
- プラトー(Plateau):勾配がほぼ0になって動かなくなる平坦な領域
学習を安定させるには、こうした問題を回避する工夫が必要です。
2. 学習率と更新の単位
学習率(Learning Rate)
- 学習率が大きすぎると最小値を飛び越えて振動します。
- 学習率が小さすぎると学習が進まなくなります。
適切な学習率の設定はとても重要です。
イテレーション、エポック、バッチサイズ
- イテレーション:重みを1回更新する処理(1バッチごと)
- エポック(Epoch):訓練データ全体を1周する処理
- バッチサイズ:1回のイテレーションで使うデータの数
学習方法の種類
| 学習方法 | 内容 | 特徴 |
|---|---|---|
| オンライン学習 | データ1件ずつ更新 | メモリ効率◎・ノイズに弱い |
| バッチ学習 | 全データをまとめて更新 | 精度安定・計算コスト高 |
| ミニバッチ学習 | データを小分けにして更新(最も一般的) | バランスが良く、確率的勾配降下法との組み合わせが主流 |
3. 確率的勾配降下法(SGD)とその改良版
確率的勾配降下法(Stochastic Gradient Descent)
SGDは、1つのデータ(または小さなミニバッチ)でパラメータを更新します。
高速ですが、更新が不安定になりがちです。
代表的な改良手法
- AdaGrad:学習率をパラメータごとに調整。初期学習に強いが、学習が止まりやすい。
- RMSprop:AdaGradの問題点を改善。学習率を動的に調整して安定性アップ。
- Adam:SGD+モーメンタム+RMSpropを組み合わせた手法。現在もっとも人気のある最適化アルゴリズムです。
4. 学習を安定・効率化するための工夫
バッチ正規化(Batch Normalization)
ネットワークの中間層の出力を正規化(平均0、分散1)することで、学習を安定化させます。
これにより、内部共変量シフト(層ごとに入力の分布が変わって学習が難しくなる現象)を抑えられます。
ドロップアウト(Dropout)
学習中にランダムに一部のノードを無効化する手法。
ノードに依存しすぎることを防ぎ、過学習を防止します。
早期終了(Early Stopping)
学習が進んでもテスト精度が向上しない(むしろ悪化する)場合、途中で学習を打ち切ることで過学習を避けるテクニックです。
プルーニング(Pruning)
不要なノードや重みを削除して、モデルを軽量化します。
性能を維持しつつ、推論速度を上げたいときに便利です。
蒸留(Distillation)
大きな教師モデルの出力を使って、より小さな生徒モデルを訓練します。
軽量化しながら高性能を維持できるため、スマホなど組み込み環境でよく使われます。
量子化(Quantization)
モデルの重みや計算精度を32bit → 8bitなどに圧縮することで、軽量化と高速化を実現する技術です。
5. データを増やして強化する:データ拡張と転移学習
データ拡張(Data Augmentation)
学習データが少ないと、過学習しやすくなります。
そこで使われるのがデータ拡張です。
たとえば、画像なら:
- 回転・反転・ズーム
- 明るさ変更・ノイズ追加
などで、人工的にデータの多様性を増やすことができます。
転移学習(Transfer Learning)とファインチューニング
転移学習は、他のタスクで学習済みのモデルを別のタスクに応用する手法です。
- 基本モデルを再利用し、最終層だけをファインチューニング(微調整)します。
これにより、少量のデータでも高性能なモデルを得られるのです。
転移学習とは、他のタスクですでに学習済みのモデルを新しいタスクに応用する手法です。たとえば、ピアノ経験者がギターを始めると上達が早いように、共通する知識を再利用することで、少ないデータでも高い性能を出せます。
一方ファインチューニングは、その再利用したモデルの一部を新しいデータに合わせて微調整する作業です。既製品を自分好みに少しだけ直すようなイメージです。
4.3 畳み込みニューラルネットワークと画像認識
画像認識において最も基本かつ強力なモデル「畳み込みニューラルネットワーク(CNN)」について学びます。
CNNは、視覚タスクにおける“標準装備”といえる存在で、G検定でも頻出のトピックです。画像をどう「理解」しているのか、順を追って見ていきましょう!
畳み込みニューラルネットワーク(CNN)は、画像を分析するのが得意なモデルです。例えるなら、カメラに色々なフィルターを付けて写真を見るようなものです。あるフィルターは「輪郭」だけを強調し、別のものは「明るさ」や「模様」に注目します。
CNNでは、こうしたフィルター(=畳み込み層)を何枚も重ねて、画像の特徴を少しずつ見つけていきます。最初は線や点を、次に目や耳、最後には「これは犬だ」と判断するわけです。階段を登るように、だんだん抽象的な理解が深まっていくのが特徴です。
1. 画像認識とCNNの必要性
普通のニューラルネットワーク(全結合型)では、画像のように大きくて構造のあるデータをうまく扱うことができません。
そこで登場したのが、画像の“局所的なパターン”を捉えることができるCNN(Convolutional Neural Network)です。
画像は、ピクセルが横×縦×色(RGB)で構成されている3次元データです。
CNNは、そこから「線」「角」「模様」→「目」「耳」→「動物」「顔」のように、階層的に意味を抽出していきます。
2. CNNの基本構造
CNNは、以下の3つの主要な層から構成されます。
畳み込み層(Convolutional Layer)
- 画像の局所領域にフィルタ(カーネル)を適用して、特徴を抽出する層です。
- この操作を畳み込み演算(convolution operation)といいます。
キーワード解説:
- フィルタ(Kernel):小さな行列。画像にスライドさせて適用することで、模様や縁などの特徴を検出します。
- ストライド(Stride):フィルタを動かすステップ幅(1ピクセルずつ、2ピクセルずつなど)。
- パディング(Padding):画像の端にゼロを追加して、サイズが縮まないようにする工夫。
→ 結果として得られる出力が「特徴マップ(Feature Map)」です。
プーリング層(Pooling Layer)
- 特徴マップのサイズを小さくして情報を圧縮する層です。英語の【pool】には「集める・ひとまとめにする」という意味があります。
- 複数の値を一つに“集約”する
- 代表的な手法は最大プーリング(Max Pooling):局所領域の中で最大値だけを残します。
プーリング層の役割:
- 計算量の削減
- 過学習の抑制
- 特徴の位置ずれに強くする(位置不変性)
全結合層(Fully Connected Layer)
- 最終的に分類を行う層です。画像の特徴をもとに、「これは犬か猫か」などの判定を行います。
3. CNNの発展と有名モデルたち
CNNが世界的に注目されたきっかけは、ILSVRC(ImageNet Large Scale Visual Recognition Challenge)という大規模画像認識コンテストでした。
この大会では、1000種類以上の画像分類を競います。
AlexNet(2012)
- CNNブームの火付け役。
- ReLUやドロップアウト、GPUによる学習を活用し、ILSVRCで圧倒的な成績を記録。
ResNet(Residual Network)
- 非常に深いネットワーク(100層以上)でも学習可能にしたモデル。
- 特徴はスキップ結合(Skip Connection):前の層の出力を飛ばして後の層に渡す仕組み。
これにより、勾配消失問題を大きく軽減しました。
EfficientNet
- 精度と効率のバランスを極限まで高めたモデル。
- Compound Scaling(複合的スケーリング):モデルの深さ、幅、解像度をバランスよく同時に拡張
従来のように「深さだけ増やす」「幅だけ広げる」といった方法ではなく、3つの軸を比例的に調整するのが特徴です。
4. CNN構造のまとめ図

4.4 リカレントニューラルネットワーク(RNN)と時系列処理
「時間の流れ」を扱えるニューラルネットワーク、つまりリカレントニューラルネットワーク(RNN)について学んでいきます。
普通のニューラルネットワークが「静止したデータ(画像など)」を扱うのに対し、RNNは音声、文章、株価、センサーデータなど「時間的な順序を持つデータ(時系列データ)」を扱うことができます。
リカレントニューラルネットワーク(RNN)は、「今までの情報を覚えながら次の予測をする」モデルです。
例えるなら、人との会話です。たとえば「昨日映画を観てね」と言われたら、その後の「すごく面白かった!」という言葉は、前の話を覚えているから意味がわかりますよね? RNNも同じように、過去の入力(文や音など)を記憶しながら処理を進めます。通常のニューラルネットワークが毎回「一問一答」なのに対し、RNNは「流れを考慮した返事」ができるのが強みです。ただし、長い会話になると昔の話を忘れてしまうことがあり、それが弱点にもなります。
1. 時系列データとは?
時系列データ(Time-series Data)とは、時間とともに変化するデータのことです。
例:
- 音声 → 時間によって変わる波形
- テキスト → 単語や文字の順番
- 株価 → 日ごとの価格の変化
これらは「順序」がとても重要な情報です。
たとえば、「私は寿司が好き」→「好きが寿司は私」では意味がまったく変わってしまいますよね。
2. RNN(リカレントニューラルネットワーク)の基本構造
RNN(Recurrent Neural Network)は、ネットワーク内部に「記憶」をもたせる構造を持っています。
普通のニューラルネットワークとは違い、出力が次の入力に影響する「フィードバック機構」があるのが特徴です。
図解イメージ):

このように、「前の状態」が「次の出力」に影響する構造になっています。
3. RNNの学習とBPTT
RNNの学習には、誤差逆伝播法を時間方向に展開したものを使います。
これを BPTT(Backpropagation Through Time:時間方向の誤差逆伝播) と呼びます。
ただし注意点:
- 長い時系列を扱うと、誤差が途中で消える(勾配消失)または逆に発散する(勾配爆発)ことがあります。
- このとき、重み衝突問題(重みの値が不安定に変化してしまう問題)が起こる可能性もあります。
これらの課題を克服するために開発されたのが、次に紹介する「LSTM」や「GRU」です。
4. LSTM(Long Short-Term Memory)
LSTMは、RNNの弱点である「長期依存の学習が苦手」な問題を克服するための拡張モデルです。
特徴は、記憶セル(CEC: Constant Error Carousel)と3つのゲート機構です。
LSTM(Long Short-Term Memory)を日記に例えて解説
LSTMは、リカレントニューラルネットワーク(RNN)の一種で、「必要な記憶は残し、いらない記憶は捨てる」ことが得意なモデルです。例えるなら、毎日つける日記のようなものです。
日記には「大事な出来事」だけを残し、どうでもいいことは書きませんよね? LSTMはこの「何を覚えるか、何を忘れるか」を自分で判断できる仕組みを持っています。これにより、普通のRNNでは苦手だった「長い文章の文脈を理解する」ことが可能になります。たとえば、小説の最初の登場人物が後半に出てきても、ちゃんと覚えている──そんな記憶力のいい日記のようなモデルです。
CEC(記憶セル)
- 誤差を一定に保ちつつ伝搬できる特殊な構造。
- これにより、「昔の情報」も消えずに保持できます。
3つのゲート
| ゲート名 | 役割 |
|---|---|
| 忘却ゲート(Forget Gate) | 古い情報をどれだけ捨てるか決定 |
| 入力ゲート(Input Gate) | 新しい情報をどれだけ記憶に加えるか決定 |
| 出力ゲート(Output Gate) | 記憶からどの情報を出力するか決定 |
このようにして、重要な情報は保持し、不要な情報は消すことで、長期的な記憶が可能になります。
5. RNN・LSTMの比較表
| モデル | 長期依存学習 | 学習速度 | パラメータ数 | 特徴 |
|---|---|---|---|---|
| RNN | 苦手 | 速い | 少ない | 構造がシンプル |
| LSTM | 得意 | 遅い | 多い | 長期記憶に強い、高精度 |
4.5 深層強化学習
「自分で試して学ぶ」タイプの人工知能=強化学習(Reinforcement Learning)と、そこに深層学習(Deep Learning)を組み合わせた「深層強化学習(Deep Reinforcement Learning)」について学びます。
チェスや囲碁、ロボットの自律行動など、人間が手本を与えずとも最適な行動を習得する仕組みです。
では、まず基本から一緒に見ていきましょう!
1. 強化学習の基本構造とは?
強化学習では、エージェント(Agent)と呼ばれるAIが、環境に働きかけながら報酬(Reward)を得ることを目指します。
構成要素:
| 用語 | 内容 |
|---|---|
| 環境 | エージェントが行動する世界(例:囲碁、迷路) |
| エージェント | 行動を選ぶAI本体 |
| 状態(State) | 現在の状況を表す情報 |
| 行動(Action) | エージェントが選べる選択肢 |
| 報酬(Reward) | 状態や行動によって得られるスコア |
2. Q値と行動選択戦略
エージェントは「この状態でどの行動を選べばよいか?」を判断するために、Q値(Q-value)と呼ばれる指標を使います。
これは、ある状態で特定の行動を取ったときに期待される報酬の合計を表します。
greedy法とε-greedy法
- greedy法:常にQ値が最大の行動を選ぶ(最適だが学習が進まないことも)
- ε-greedy法:確率εでランダムに行動、それ以外は最良の行動 → 探索(exploration)と活用(exploitation)のバランスを取る
3. 代表的な強化学習手法
SARSA(State-Action-Reward-State-Action)
SARSAは、強化学習のアルゴリズムのひとつで、「今の行動が次の行動にどうつながるか」を意識しながら学ぶ仕組みです。
例えるなら、毎朝のルーティンを決める習慣づけです。
たとえば「朝6時に起きる(状態)→ランニングする(行動)→体が軽くなる(報酬)→次の日も6時に起きる(次の状態)→ストレッチをする(次の行動)」というふうに、今の選択が次の選択にも影響を与えるような感覚です。
SARSAでは、この一連の流れ
状態 → 行動 → 報酬 → 次の状態 → 次の行動
をすべて意識しながら学習します。
「そのとき何をしたか」だけでなく「次にどう動いたか」も含めて学ぶ点が特徴です。だからこそ、より慎重な行動選択ができるのです。
Q学習(Q-Learning)
Q学習は、「どの行動がどれだけ得になるか」を自分で試して覚える強化学習のアルゴリズムです。例えるなら、地図も案内もない中で宝探しの冒険をするようなものです。
最初は、どの道に進めばいいか分かりません。でも、とりあえず歩いてみて、「この道は敵が多かった」「あの道は宝箱があった」と少しずつ経験から学んでいきます。そして、「この場所でこの行動をすれば、だいたい得をする」という知識(Q値)を地図のように蓄えていくんです。
Q学習では、次に何をするかを「最大の見返りをくれる行動」に基づいて選びます。「今」よりも「将来の得」を重視するのが特徴です。失敗も成功も経験に変えながら、だんだんと最短ルートを見つけていく──そんな自律的な学び方です。
MIN-MAX法とブルートフォース法
- MIN-MAX法:相手が最も自分に不利な行動を取ることを前提に、最悪の状況でも最善手を選ぶ戦略(チェスや将棋で使われる)
- ブルートフォース法:すべての手を網羅的に試して最善手を選ぶ手法。計算コストが非常に高いため、大規模問題では実用的でない。
4. モンテカルロ法:試行回数で答えを近づける
モンテカルロ法は、ランダムな試行を何度も繰り返すことで、統計的に最適な戦略を導き出す手法です。
強化学習では、将来の報酬の平均を推定する方法として利用されます。
5. 深層強化学習(Deep Reinforcement Learning)
ここまで紹介してきた強化学習は、状態や行動を数値で表せる場合に限られていました。
でも、画像や自然言語などの複雑な入力には向いていません。
そこで登場するのが、深層強化学習(Deep RL)。
Q値の推定をニューラルネットワークで行う手法が登場し、これをDeep Q Network(DQN)と呼びます。
6. DQNとその進化
DQN(Deep Q-Network)
- 画像などの入力から状態を抽出し、Q値を出力するニューラルネットワークを使います。
- Atariのゲームなどで人間を超えるスコアを出し、話題になりました。
Experience Replay(経験再生)
DQNでは、「直前の経験」だけに基づいて学習するのではなく、過去の経験をメモリに保存し、ランダムに再利用する手法を使います。
これにより、データの偏りを防ぎ、学習の安定性が向上します。
Noisy Network(ノイジーネットワーク)
ネットワークの重みにランダムなノイズを加えることで探索性を高める技術です。
ε-greedy法のように外からランダム性を加えるのではなく、モデルそのものが探索的行動を選べるようになるのが特徴です。
7. AlphaGoとAlphaGo Zero:究極の強化学習AI
- AlphaGo(2016):DeepMind社が開発した囲碁AI。人間の棋譜を使って学習した後、自己対戦を繰り返して強化学習。
- AlphaGo Zero(2017):人間のデータを一切使わず、ゼロから自己対戦のみで学習。数日で世界トップレベルに。
AlphaGo Zeroは、強化学習と深層学習を融合させた深層強化学習の到達点ともいえるモデルです。
4.6 オートエンコーダーとその他の重要技術
データの特徴を圧縮・再構築することで学習する「オートエンコーダー(Autoencoder)」と、それを取り巻く重要な技術群について解説します。
画像処理、異常検知、事前学習など、さまざまな分野で活躍する「縁の下の力持ち」です。
1. オートエンコーダーとは?
オートエンコーダーは、入力データを一度「圧縮」してから「再構築」することで、そのデータの本質的な特徴を学習するニューラルネットワークです。
オートエンコーダーは、データを一度コンパクトに圧縮し、あとから元の形に近づけて再現するモデルです。
これを例えるなら、インスタントコーヒーのようなものです。
本物のコーヒーは豆から抽出しますが、それを一度「粉」にして保存しやすくしたのがインスタントコーヒー。使うときにはお湯で溶かして、元の風味にできるだけ近づけますよね。
オートエンコーダーも、入力データを「特徴だけ残して圧縮(=エンコード)」し、あとで「できるだけ元に戻す(=デコード)」という流れで動きます。画像や音声など、情報量が多いデータを扱うときに、本質的な特徴だけを取り出すフィルターとしてよく使われます。まさに、「本質だけを抽出して、必要なときに戻す」インスタント技術なんです。
基本構造
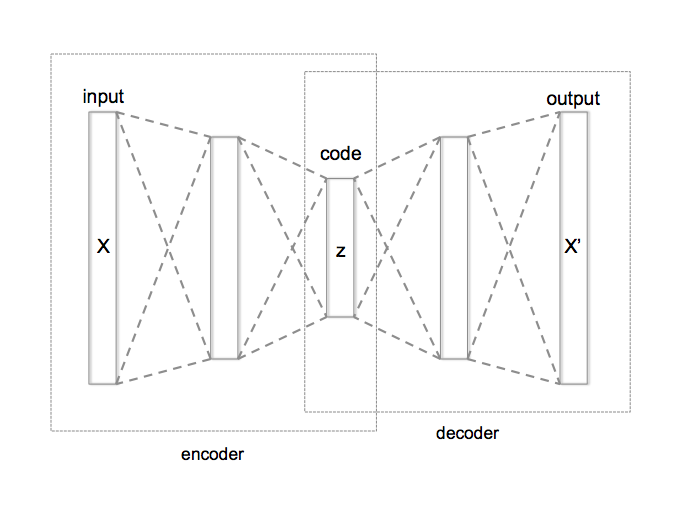
- エンコード(Encode):元のデータを小さな次元に変換(特徴抽出)
- 隠れ層(Hidden Layer):圧縮された情報(ボトルネック層)
- デコード(Decode):圧縮された情報から元のデータに復元
2. 隠れ層と「積層オートエンコーダー」
隠れ層のノード数を入力よりも少なくすると、モデルは「限られた情報で最大限に再構成」しようとします。
これが次元削減・特徴抽出の本質です。
さらに、隠れ層を何層にも重ねた構造が積層オートエンコーダー(Stacked Autoencoder)です。
事前学習と勾配消失問題の関係
ニューラルネットワークが深くなると起こる「勾配消失問題」――これは、誤差が伝わらずに学習が止まる現象です。
積層オートエンコーダーでは、1層ずつ順番に学習する「事前学習(pre-training)」を行うことで、勾配消失を回避しやすくなります。
この技術は、深層学習がブレイクする前夜の重要な突破口となったものです。
3. データの次元とその呪い
オートエンコーダーは、高次元データをコンパクトに表現できるため、「次元の呪い(Curse of Dimensionality)」の対策にも有効です。
● 次元の呪いとは?
- 特徴量が増えると、データの密度が極端に低くなり、学習が困難になる現象
- 特徴の一部を削ってでも、本質的な情報を抽出したほうが性能が上がることも多い
4. データの加工手法:サンプリングとスケーリング
オートエンコーダーやその他のモデルでも、入力データをうまく整えることが極めて重要です。
オーバーサンプリングとダウンサンプリング
- オーバーサンプリング:データを水増し(重複や人工生成)して、少数クラスを補う
- ダウンサンプリング:データを間引きして、多数クラスの偏りを減らす
これは不均衡データへの対策としてよく使われます。
平滑化・標準化・正規化・白色化の違い
| 用語 | 内容 |
|---|---|
| 平滑化 | ノイズを除去し、滑らかなデータに加工(例:移動平均) |
| 標準化(Z-score) | 平均0、標準偏差1に変換。 |
| 正規化(Min-Max) | 値を0〜1の範囲にスケーリング。 |
| 白色化 | データの相関をなくし、分散を揃えた標準化。PCAなどと組み合わせることも。 |
これらの手法は、ニューラルネットワークがスムーズに学習するための“下準備”とも言えます。
次章では、「ディープラーニングの応用と発展」を学びます。