
【初心者でもわかる!KLダイバージェンスとは何か?】
 山崎講師
山崎講師こんにちは。ゆうせいです。
今回は、「KLダイバージェンス」という聞き慣れない言葉について、エンジニア1年目の方でも理解できるように、じっくりわかりやすく解説していきます。
KLダイバージェンスって何?
まずはざっくりと説明しましょう。
KLダイバージェンス(Kullback–Leibler divergence)は、2つの確率分布の「違い」を測る指標です。
たとえ話で理解しよう!
例えば、あなたが普段行くスーパーで売られている商品の価格分布(Aスーパー)と、別のスーパー(Bスーパー)の価格分布を比べたいとします。
「Aではリンゴが100円でよく売られてるけど、Bでは120円の方が多いな」
このように、どれだけ「想定とズレてるか」を数値で表したのがKLダイバージェンスです。
数式で見てみよう!
KLダイバージェンスは以下のように定義されます:

読み方:
「PとQのKLダイバージェンスは、P(x)にQ(x)との比率の対数をかけて足し合わせたもの」
ここでの記号の意味を丁寧に見てみましょう。
| 記号 | 意味 |
|---|---|
 | 実際の分布(または「本物のデータ」) |
 | 近似したい分布(モデルなど) |
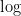 | 対数(通常は自然対数) |
 | 全てのxについて足し合わせる |
どんなときに使うの?
主に機械学習や統計モデリングの中で使われます。
特に、モデルの予測分布が、実際の分布にどれだけ近いかを評価するために重要です。
たとえば:
- ベイズ推論
- 変分オートエンコーダ(VAE)
- 言語モデルの学習
などで大活躍しています!
KLダイバージェンスの特徴
| 特徴 | 内容 |
|---|---|
| 非対称性 |  → 順番を変えると値も変わる → 順番を変えると値も変わる |
| 常に0以上 | 完全に一致していれば0、ずれていれば大きくなる |
| 距離のようで距離じゃない | 正確には「距離」ではなく、情報の損失量と考える |
メリットとデメリット
メリット
- 情報理論的に意味が明確(情報のズレを定量化できる)
- モデルの最適化に使いやすい(例:損失関数)
デメリット
- 非対称なので使いどころに注意が必要
のときに値が発散してしまう(定義できない)
図で理解しよう!
次の図をご覧ください。
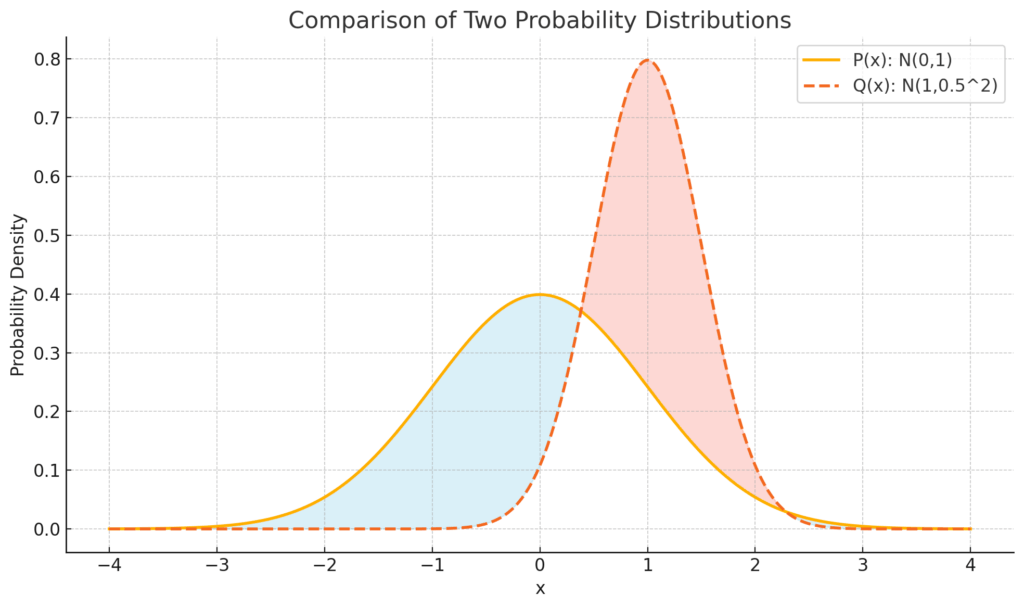
こちらが「P(x)」と「Q(x)」の確率分布を比較した図です。
青や赤で塗られている部分が、両者の違いを表しています。ここがKLダイバージェンスの計算対象になるイメージです!
今後の学習の指針
KLダイバージェンスを理解したあなたは、次のステップとして以下のテーマに取り組んでみてください。
- エントロピー(情報量)とは何か?
- 変分推論とELBO(Evidence Lower Bound)
- JSダイバージェンス(対称性があるKLの発展系)
- VAE(Variational Autoencoder)での使われ方
実際にPythonなどで手を動かして、KLダイバージェンスを自分で計算してみるのもおすすめです!
生成AI研修のおすすめメニュー
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。

