
E検定対策!Pythonで学ぶ「情報理論」入門:エントロピーからKLダイバージェンスまで徹底解説
 山崎講師
山崎講師エントロピーからKLダイバージェンスまでをシミュレーションで学ぶ
第1章:情報理論へようこそ! なぜ「情報」を測るの?
さあ、E検定の学習を始めていきましょう!
最初のテーマは「情報理論」です。AIやディープラーニングを学ぶ上で、この分野は避けて通れない、とても重要な土台となります。
「情報? 理論? なんだか哲学的で難しそう…」と感じるかもしれませんね。
でも心配いりません! ここでは、AIの学習になぜ情報理論が必要なのか、その「キモチ」の部分から優しく解説していきます。
1-1. 情報理論って、なんですか?
まず、言葉の定義から確認しましょう。
専門用語解説:「情報理論(Information Theory)」
情報理論とは、文字通り「情報」を数学的に扱うための理論です。
「情報」という、とても曖昧(あいまい)なものを、客観的な「量」として測定したり、効率よく伝えたり(通信)、蓄えたり(圧縮)する方法を研究する分野です。
では、あなたに質問です。
次の2つのニュースを聞いたとき、どちらが「情報量が多い」と感じますか?
- A:「今日の午後の天気は、晴れです」
- B:「年末ジャンボ宝くじで、1億円が当選しました!」
…もちろん、Bですよね!
なぜでしょう? それは、Bの方が「珍しい(めったに起こらない)出来事」だからです。
Aの「天気が晴れ」というのは、わりとよくあることですよね。
でも、Bの「1億円当選」は、天文学的な確率でしか起こりません。
情報理論では、この「珍しさ」や「予測しにくさ」、あるいは「不確かさ」のことを「情報量」と呼びます。
つまり、「めったに起こらないことほど、情報量は大きい」と考えるのです。
情報理論は、この「珍しさの度合い」を、客観的な「数値」として測るための学問だ、とまずは理解してください。
1-2. E検定と情報理論:AIは「情報」をどう使う?
では、その「情報量」を測る学問が、E検定で学ぶAIとどう関係するのでしょうか?
AI、特にディープラーニングのモデルを「学習」させる時、私たちがやっていることは何でしょう?
それは、モデル(AI)に問題(例えば「この画像は犬ですか?猫ですか?」)を見せて、予測させる作業です。
そして、AIが出した「予測」と、私たちが用意した「正解」を比べます。
もしAIが「犬の画像を90%の確率で猫」と予測したら、それは「正解」から大きくズレていますよね?
AIの学習とは、この「予測」と「正解」の「ズレ」を最小限にしていく作業、と言い換えることができます。
ここで情報理論の出番です!
情報理論は、この「ズレ」を測るための、非常に強力な「物差し」として活躍するのです。
- AIの「予測」…ある種の確率
- 私たちが持つ「正解」…ある種の確率
この2つの確率が、どれだけ「離れているか」を、情報理論の考え方を使って数値化します。
その数値(ズレの大きさ)を「損失(Loss)」と呼び、その損失ができるだけ小さくなるように、AIは自分自身を賢く調整していくのです。
E検定で登場する「クロスエントロピー」などは、まさにこの「物差し」の代表選手なんですよ。
1-3. 準備運動:Python環境とライブラリ
この学習(テキスト)では、数式をただ眺めるだけでなく、実際にPythonのコードを動かしながら「情報量」を体感していくことを目指します。
本格的なAIライブラリ(TensorFlowやPyTorch)の前に、まずは以下の基本的な道具が揃っているか確認してください。
- Pythonの基本的な文法
- 変数、リスト、関数の定義など、基本的なことは理解している前提で進めますよ!
- math ライブラリ
- 情報量の計算には「対数(log)」という数学の道具が不可欠です。この math ライブラリは、対数計算など基本的な数学関数を提供してくれます。
- numpy ライブラリ
- AI・データサイエンスの世界では必須のライブラリ、ナムパイ(またはナンパイ)です。
- 複数の数値をまとめて(配列として)高速に計算するときに大活躍します。
準備はよろしいでしょうか?
次の章から、いよいよ「情報量」を計算する具体的な数式と、Pythonコードの世界に入っていきます!
第1章では、情報理論がAIにとって「予測と正解のズレを測る物差し」として重要だ、というお話をしましたね。そして、「珍しいことほど情報量が大きい」という感覚を共有しました。
第2章では、いよいよその「珍しさ」や「不確かさ」を、具体的な「数値」として計算する方法を学んでいきます。
ここが情報理論の核となる部分です。はりきっていきましょう!
第2章:情報の「珍しさ」と「ごちゃ混ぜ度」を測る!エントロピー
2-1. 「珍しさ」を数字にする:自己情報量
まずは、個々の出来事が持つ「珍しさ」を数値化してみましょう。
専門用語解説:「自己情報量(Information Content)」
自己情報量とは、ある特定の出来事 
英語では「Information Content」や「Surprisal(驚きの度合い)」と呼ばれることもあります。
第1章の例を思い出してください。
「宝くじで1億円が当たる」という出来事
確率が低い(珍しい)ほど、自己情報量は「大きく」なってほしい。
逆に、「天気が晴れ」のように確率が高い(よくある)ことほど、自己情報量は「小さく」なってほしい。
この関係をうまく表現するために、数学では「対数(log)」、特に「マイナスの対数」を使います。
なぜマイナスかって?
確率は必ず0から1の間の数値ですよね。(100%が1です)
0から1の間の数値を対数(log)で計算すると、結果は必ずマイナスになってしまいます。
情報量をマイナスにしたくないので、頭にマイナスをつけて、プラスの数値に変換しているのです!
数式:


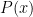

さっそくPythonで計算してみましょう!
mathライブラリを使って、確率
import math
# 確率 P(x)
# 例1: 明日が晴れる確率 (仮に 50% = 0.5 とする)
P_hare = 0.5
I_hare = -math.log2(P_hare)
print(f"晴れの自己情報量: {I_hare}")
# 例2: 宝くじが当たる確率 (仮に 100万分の1 = 0.000001 とする)
P_takarakuji = 0.000001
I_takarakuji = -math.log2(P_takarakuji)
print(f"宝くじ当選の自己情報量: {I_takarakuji}")実行してみると、晴れの自己情報量は「1.0」ですが、宝くじ当選の自己情報量は「約19.9」と、とてつもなく大きな数値になるはずです。
確率が低いほど、情報量が爆発的に増えていく感覚が掴めましたか?
2-2. 「ごちゃ混ぜ度」の平均値:エントロピー
自己情報量は、あくまで「一つの出来事」に対する珍しさでした。
でも私たちが知りたいのは、多くの場合、「そのデータ全体が、どれくらい予測しにくいのか」という、全体の傾向です。
専門用語解説:「エントロピー(Entropy)」
エントロピーとは、自己情報量の「期待値(平均値)」のことです。
ちょっと難しく聞こえますが、要するに「その確率的なシステム全体(例えば、明日の天気や、サイコロの目)が、平均してどれくらいの情報量を持っているか」を示す指標です。
エントロピーは、そのシステムがどれだけ「不確かか」「ごちゃ混ぜか」「予測しにくいか」を表す数値、と考えると分かりやすいですよ。
例えを使って考えてみましょう。
ここに2種類のコインがあります。
- A. イカサマコイン
- 投げてみたら、100%の確率で「表」しか出ません。
- B. 公平なコイン
- 投げると、50%の確率で「表」、50%の確率で「裏」が出ます。
さて、このコインを投げる前に「次に出る面は?」と予測するとき、どちらが難しいですか?
もちろん、Bの公平なコインですよね!
Aのイカサマコインは、予測するまでもなく「表」です。結果が完全に分かっているので、「不確かさ」はゼロです。
一方、Bの公平なコインは、「表」か「裏」か、投げてみるまで全く分かりません。「不確かさ」が最大です。
エントロピーは、この「不確かさ(ごちゃ混ぜ度)」を数値化したものです。
したがって、エントロピーはA(イカサマコイン)では「最小(ゼロ)」となり、B(公平なコイン)では「最大」となります。
2-3. エントロピーの数式とPython実装
エントロピーは「自己情報量の平均値」でしたね。
平均値を計算するには、「(その出来事の自己情報量)×(その出来事が起こる確率)」を、すべての出来事について足し合わせればOKです。
数式:


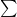

では、Python(Numpy)を使って、これを計算してみましょう!
題材として、公平な6面体のサイコロを考えてみます。
公平なサイコロは、「1」から「6」までの目が、すべて同じ確率 
import numpy as np
# 公平なサイコロの確率分布 P(x)
# [1の目, 2の目, 3の目, 4の目, 5の目, 6の目]
P_dice = np.array([1/6, 1/6, 1/6, 1/6, 1/6, 1/6])
# 自己情報量 I(x) = -log2(P(x))
# Numpyなら、配列全体を一度に計算できます!
I_dice = -np.log2(P_dice)
# エントロピー H(X) = Σ P(x) * I(x)
# (Σ P(x) * (-log2(P(x))) と同じ意味です)
H_dice = np.sum(P_dice * I_dice)
print(f"公平なサイコロの確率分布: {P_dice}")
print(f"各目の自己情報量: {I_dice}")
print(f"公平なサイコロのエントロピー: {H_dice}")実行すると、エントロピーは約「2.58」という値になるはずです。
もし、これが「1の目しか出ないイカサマサイコロ」だったらどうなるでしょう?
確率は [1.0, 0, 0, 0, 0, 0] となります。(0の対数は計算できないので工夫が要りますが、理論上)エントロピーは「0」になります。予測が100%当たるので、不確かさゼロ、というわけです。
どうでしょう?
エントロピーが「ごちゃ混ぜ度」や「不確かさ」を表す指標だ、という感覚が掴めてきたでしょうか。
次の章では、いよいよこのエントロピーの考え方を使って、AIの「予測」と「正解」の「ズレ」を測る方法、クロスエントロピーとKLダイバージェンスに進みます!
第2章では、「珍しさ」を表す自己情報量と、「ごちゃ混ぜ度」の平均値を表すエントロピーについて学びました。
さて、ここからがE検定で最も重要と言っても過言ではないクライマックスです!
第3章では、AIの学習で「間違っている」とはどういうことか、その「間違いの度合い(ズレ)」を測るための2つの強力な物差し、「クロスエントロピー」と「KLダイバージェンス」を徹底的に解説します。
第3章:2つの「ズレ」を測る!クロスエントロピーとKLダイバージェンス
3-1. AIの学習と「2つの分布」
第1章で、AIの学習は「予測」と「正解」の「ズレ」を最小にする作業だ、という話をしましたね。
この「予測」と「正解」は、情報理論の世界では、それぞれが一つの「確率分布」として表現されます。
ピンと来ないかもしれませんので、具体的な例で見てみましょう。
あるAIが、目の前の画像が「犬」か「猫」かを当てる(分類する)問題を解いているとします。
- 「正解」の確率分布(
と呼びましょう)その画像は、まぎれもなく「犬」だとします。この「犬である」という正解を、確率分布で無理やり表現すると、次のようになります。
- 「モデルの予測」の確率分布(
と呼びましょう)AIモデルは、まだ学習途中なので、自信がありません。
AIの学習のゴールは、この「予測
そのためには、まず
3-2. 損失関数の王様:クロスエントロピー
ここで登場するのが、E検定で超頻出の「クロスエントロピー」です。
専門用語解説:「クロスエントロピー(Cross Entropy)」
クロスエントロピーは、一言でいうと「間違った物差し(予測Q)で測ったときの、平均情報量」です。
どういうことでしょう?
第2章で、エントロピーは「自己情報量の平均値」だと学びました。
本来、情報量の平均(エントロピー)を計算するときは、「正解の確率 
でももし、本当の確率(正解
その時に計算される「見かけ上の平均情報量」が、クロスエントロピー 
数式:

第2章のエントロピー


違いは、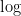
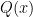
メリット(なぜAIで使うの?)
ここが最重要ポイントです!
クロスエントロピー
(そして、 
AIの学習の目的は「ズレを最小にする」ことでした。
クロスエントロピーは「ズレが小さいほど、値も小さくなる」。
…ということは?
AIの学習において、クロスエントロピーを「損失関数(ペナルティ)」として使い、この数値を最小化するようにAIを訓練すれば、自然と「予測
まさにAIの「損失関数」にピッタリだと思いませんか?
3-3. Pythonで実装!クロスエントロピー
先ほどの「犬 vs 猫」の例で、クロスエントロピーを計算してみましょう。





これが、モデルの「間違い度合い(損失)」となります。
もしモデルがもっと賢くなって、

となり、損失が小さくなりました!
Python(Numpy)で計算してみましょう。
import numpy as np
# P (正解): [犬: 1.0, 猫: 0.0]
P_correct = np.array([1.0, 0.0])
# Q (モデルの予測): [犬: 0.7, 猫: 0.3]
Q_model_1 = np.array([0.7, 0.3])
# クロスエントロピー H(P, Q)
# H(P,Q) = -Σ P(x) * log2(Q(x))
# np.log2(Q_model_1) の計算結果は [log2(0.7), log2(0.3)] です
H_PQ_1 = -np.sum(P_correct * np.log2(Q_model_1))
print(f"モデル1 (0.7, 0.3) のクロスエントロピー: {H_PQ_1}")
# もしモデルがもっと賢くなったら
# Q (モデルの予測): [犬: 0.9, 猫: 0.1]
Q_model_2 = np.array([0.9, 0.1])
H_PQ_2 = -np.sum(P_correct * np.log2(Q_model_2))
print(f"モデル2 (0.9, 0.1) のクロスエントロピー: {H_PQ_2}")
実行結果からも、予測が正解に近づく(0.7 -> 0.9)と、クロスエントロピー(損失)が小さくなる(0.514 -> 0.152)ことが確認できるはずです!
3-4. 純粋な「ズレ」の大きさ:KLダイバージェンス
クロスエントロピーとセットで必ず登場するのが「KLダイバージェンス」です。
専門用語解説:「KLダイバージェンス(Kullback-Leibler Divergence)」
KLダイバージェンスは、2つの確率分布
実は、先ほど計算したクロスエントロピー
このうち、2番目の「
関係式:
(KLダイバージェンス)=(クロスエントロピー)ー(正解のエントロピー)
この式を変形すると、
AIの学習で「クロスエントロピー
ということは、「クロスエントロピーを最小化すること」と「KLダイバージェンスを最小化すること」は、AIの学習においては全く同じ意味(等価)なのです!
KLダイバージェンスの数式:

3-5. KLダイバージェンスの注意点(デメリット?)
ここで非常に大切な注意点があります。
KLダイバージェンス
それは、非対称性(Asymmetry)です。
A地点からB地点への距離が5mなら、B地点からA地点への距離も5mですよね?
しかし、KLダイバージェンスは違います!
と

では、計算結果が全く異なります。
AIの学習(分類問題)では、常に「正解
3-6. Pythonで実装!KLダイバージェンス
先ほどの「犬 vs 猫」の例で、KLダイバージェンス

でした。
は
です。
は
の不定形ですが、情報理論では
として扱います。(確率0のことは情報量に影響しない)よって、
です。(考えてみれば当たり前ですね。「正解」は [1.0, 0.0] と決まりきっていて、「ごちゃ混ぜ度(不確かさ)」はゼロです!)
- 引き算する



なんと、この例(正解がone-hot表現)の場合、KLダイバージェンスとクロスエントロピーの値が全く同じになりました!
これは、AIの分類問題では非常によくあるケースです。
import numpy as np
# P (正解): [犬: 1.0, 猫: 0.0]
P_correct = np.array([1.0, 0.0])
# Q (モデルの予測): [犬: 0.7, 猫: 0.3]
Q_model = np.array([0.7, 0.3])
# 1. H(P, Q) クロスエントロピー
H_PQ = -np.sum(P_correct * np.log2(Q_model))
# 2. H(P) 正解のエントロピー
# log(0) を計算しないように P > 0 の項だけ足し合わせる
# (今回は P[0] = 1.0 だけが対象)
H_P = -np.sum(P_correct[P_correct > 0] * np.log2(P_correct[P_correct > 0]))
# 3. D_KL(P || Q) = H(P, Q) - H(P)
D_KL = H_PQ - H_P
print(f"クロスエントロピー H(P,Q): {H_PQ}")
print(f"正解のエントロピー H(P): {H_P}")
print(f"KLダイバージェンス D_KL(P||Q): {D_KL}")
実行すると、H(P)が0になり、H(P,Q)とD_KL(P||Q)が同じ値になることが確認できます。
お疲れ様でした!
情報理論の山場、エントロピー、クロスエントロピー、KLダイバージェンスの関係性が、少し見えてきたのではないでしょうか。
エントロピーからKLダイバージェンスまでをシミュレーションで学ぶ
セイ・コンサルティング・グループの新人エンジニア研修のメニューへのリンク
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。


