
【初心者向け】たくさんのデータを要約する魔法?主成分分析(PCA)を世界一わかりやすく解説!
 山崎講師
山崎講師こんにちは。ゆうせいです。
「たくさんの項目があるデータを渡されたけど、どこから見ていけばいいんだろう…」「特徴量が多すぎて、モデルの精度が上がらない!」
新人エンジニアとしてデータと向き合う中で、そんな悩みを抱えたことはありませんか?
たくさんの変数(特徴量)があると、データの全体像を掴むのはとても大変ですよね。
そんなときに役立つ強力な武器が、今回ご紹介する「主成分分析(Principal Component Analysis, PCA)」です!
この記事を読めば、主成分分析が何なのか、どんなときに役立つのか、そしてその仕組みまで、スッキリ理解できるようになりますよ。
さあ、一緒にデータの要約術をマスターしにいきましょう!
主成分分析(PCA)って、一言でいうと何?
まずは結論から。
主成分分析とは、「たくさんある情報を、できるだけ失わずに、より少ない新しい指標に要約する」ための手法です。
…と言われても、まだピンとこないかもしれませんね。
身近な例で考えてみましょう!
例え話:体力測定の結果を要約してみよう
あなたの学校で体力測定があったとします。
測定項目は、50m走、走り幅跳び、ハンドボール投げ、持久走、反復横跳び…など、たくさんありますよね。
これらの結果を個別に見ていても、「AくんはBくんより足が速い」「CさんはDさんよりボールを遠くに投げられる」ということは分かりますが、「総合的に見て、誰が一番運動能力が高いのか?」を判断するのは少し難しいです。
ここで主成分分析の出番です!
主成分分析を使うと、これらのたくさんの測定項目を、例えば「総合的な運動能力」と「瞬発力・持久力のバランス」という、たった2つの新しい指標にまとめ直すことができます。
どうやってそんなことをするのでしょうか?
まず、関連性の強い項目をグルーピングすることを考えます。
例えば、50m走、走り幅跳び、反復横跳びは、どれも「瞬発力」に関係が深いですよね。
一方で、持久走は「持久力」を示す指標です。
主成分分析は、このようにデータの中から関連性の強い変数の組み合わせを見つけ出し、それらを統合した新しい指標(これを「主成分」と呼びます)を自動で作り出してくれます。
最初の新しい指標である「第1主成分」は、元のデータが持つ情報を最もよく表す、いわば「総合指標」になります。体力測定の例で言えば、これが「総合的な運動能力」に相当するわけです。
そして「第2主成分」は、第1主成分では説明しきれなかった、次に重要な情報を表す指標(例えば「瞬発力系か持久力系か」)になります。
このように、たくさんの測定項目を1つや2つの「主成分」に要約することで、一人ひとりの生徒の運動能力の全体像が、ぐっと分かりやすくなると思いませんか?
主成分分析で出てくる専門用語を解説!
さて、イメージが掴めてきたところで、主成分分析を学ぶ上で避けては通れない専門用語を、いくつか見ていきましょう。
大丈夫、一つ一つ丁寧に解説するので安心してください!
次元削減 (Dimensionality Reduction)
これは、主成分分析の目的そのものを表す言葉です。
データの「次元」とは、簡単に言えば「項目の数」のことです。体力測定の例なら、測定項目が10個あれば、そのデータは「10次元のデータ」ということになります。
主成分分析を使って10個の項目を2つの主成分に要約するのは、まさに「10次元から2次元へ次元を削減する」ことに他なりません。
主成分 (Principal Component)
先ほどから何度も登場していますが、元の変数(測定項目など)を組み合わせて作られた「新しい指標」のことです。
データの情報を最もよく反映する順に、第1主成分、第2主成分、第3主成分…と名付けられます。
寄与率 (Contribution Ratio)
それぞれの主成分が、元のデータ全体の情報をどれくらいの割合で説明できているかを示す指標です。
例えば、第1主成分の寄与率が70%だとすると、この第1主成分だけで、元のデータが持つ情報の70%を説明できている、ということになります。非常に優秀な要約指標だと言えますね!
累積寄与率 (Cumulative Contribution Ratio)
その名の通り、寄与率を累積(足し算)したものです。
第1主成分から順に寄与率を足し合わせていき、例えば「第2主成分までの累積寄与率が85%」となったとします。
この場合、「第1主成分と第2主成分の2つがあれば、元のデータの85%は説明できる」と判断できます。分析の目的にもよりますが、一般的にこの累積寄与率が70%〜80%程度になるまでの主成分を採用することが多いです。
PCA計算演習:2つのデータの主成分を求めよ
以下のデータセットについて、第1主成分を求めてみましょう。
- 生徒 A:数学 4点、英語 2点
- 生徒 B:数学 2点、英語 4点
ステップ1:中心化(平均を 0 にする)
まずは、データの平均を求めて、各データからその平均を引きます。
- 数学の平均: ( 4
2 )
2 = 3
- 英語の平均: ( 2
各データから平均の 3 を引いた「中心化データ」を求めてください。
これが計算のスタート地点になります。
ステップ2:共分散行列を作る
中心化したデータを使って、データのバラツキ具合を表す行列を作ります。
2×2の行列になりますが、それぞれの要素は以下の式で計算します。
(※今回はデータ数が 2 なので、簡単のため 
- 左上(数学の分散): ( ( 4
3 )
( 4
- 右下(英語の分散): ( ( 2
- 右上と左下(共分散): ( ( 4
ステップ3:固有値を求める
ステップ2で求めた行列を 


これが「新しい軸(主成分)の重要度」になります。
二つの
ヒント
この問題を解くためのヒントをいくつかお伝えします。
- ステップ2の行列
- ステップ3の固有値は、 2 と 0 になります。
固有値 2 に対応する方向(固有ベクトル)を求めると、それは「数学が得意で英語が苦手」あるいは「その逆」という傾向をズバッと表す軸になります。
理論をコードに落とし込んでみよう
先ほど紙とペンで考えた計算手順を、今度はPythonのコードで実行してみましょう。
数学の式をプログラムにする際は、数値計算ライブラリの定番である numpy(ナンパイ)を使うのが一般的です。
コードを書くことで、手計算では面倒だった複雑な行列の扱いも、一瞬で処理できる爽快感を味わえますよ!
それでは、ステップごとに解説していきます。
PCAを再現するPythonプログラム
以下のコードをコピーして、お手元の環境で動かしてみてください。
import numpy as np
# 1. データの準備(生徒A: [4, 2], 生徒B: [2, 4])
# 行が各生徒、列が[数学, 英語]の点数を表します
data = np.array([[4, 2],
[2, 4]])
# 2. 中心化(各列の平均を引く)
mean = np.mean(data, axis=0)
centered_data = data - mean
# 3. 共分散行列の作成
# rowvar=Falseにすることで、列(科目)ごとの分散を計算します
cov_matrix = np.cov(centered_data, rowvar=False, ddof=0)
# 4. 固有値と固有ベクトルの計算
eigenvalues, eigenvectors = np.linalg.eig(cov_matrix)
# 結果の表示
print("中心化データ:\n", centered_data)
print("共分散行列:\n", cov_matrix)
print("固有値(主成分の強さ):", eigenvalues)
print("固有ベクトル(主成分の向き):\n", eigenvectors)実行結果
中心化データ:
[[ 1. -1.]
[-1. 1.]]
共分散行列:
[[ 1. -1.]
[-1. 1.]]
固有値(主成分の強さ): [2. 0.]
固有ベクトル(主成分の向き):
[[ 0.70710678 0.70710678]
[-0.70710678 0.70710678]]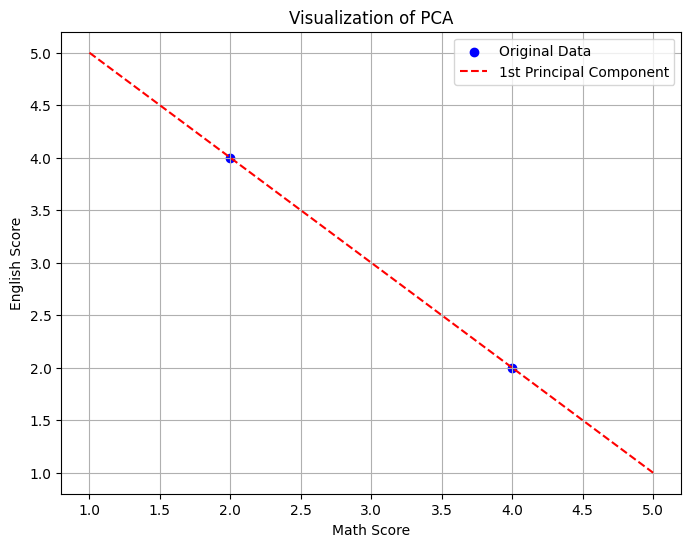
コードの注目ポイントを解説
このプログラムの中で、特に重要な役割を果たしている部分を噛み砕いて説明します。
axis=0 で平均を取る
np.mean(data, axis=0) という部分は、「縦方向(科目ごと)」に平均を出してね、という命令です。
これにより、数学の平均 3 と英語の平均 3 が計算されます。
高校生のみなさんも、テストの平均点を出すときは科目ごとに計算しますよね。それと同じです。
np.linalg.eig は魔法の杖
一番の難所である「固有値分解」を担当しているのが np.linalg.eig です。
先ほど方程式
出力される eigenvectors は、新しいグラフの軸の向きを表しています。
このデータの場合、第1主成分の向きは ![[ 0.707, -0.707 ]](https://s0.wp.com/latex.php?latex=%5B+0.707%2C+-0.707+%5D&bg=ffffff&fg=000&s=0&c=20201002)
PCAの実装におけるメリットと注意点
自分でコードを書くようになると、以下のことが見えてきます。
メリット
- 再現性:どんなにデータが増えても、同じコードで一貫した分析ができます。
- 自動化:人間が紙で計算する必要がなくなり、ミスが減ります。
デメリット
- ブラックボックス化:中身の数式を理解せずに使うと、間違ったデータを入れても「それっぽい結果」が出てしまい、誤解を招くことがあります。
主成分分析のメリットとデメリット
非常に便利な主成分分析ですが、もちろん万能ではありません。
どんなメリットがあって、どんな点に注意すべきなのかをしっかり押さえておきましょう。
メリット
- データの可視化10次元のデータをそのままグラフに描くことは不可能ですが、主成分分析で2次元に削減すれば、散布図としてプロットできます。これにより、データ全体の構造や、データ点がどのようにグループを形成しているのかを直感的に把握できます。
- 多重共線性の回避これは少し専門的ですが、機械学習のモデルを作る際に重要なメリットです。似たような説明変数(例えば、「最高気温」と「アイスの売上」と「ビールの売上」など)が複数あると、モデルの精度が不安定になる「多重共線性(マルチコ)」という問題が起こることがあります。主成分分析で互いに無相関な主成分に変換しておくことで、この問題を回避し、安定したモデルを構築できます。
- ノイズの除去寄与率の低い主成分は、元のデータのあまり重要でない情報や、単なるノイズを反映していることが多いです。これらを分析から除外することで、より本質的なデータの特徴に焦点を当てられます。
デメリット
- 主成分の解釈が難しいこれが最大のデメリットかもしれません。新しく作られた主成分が「一体何を表す指標なのか」を解釈するのが難しい場合があります。体力測定の例のように「総合運動能力」とハッキリ言えれば良いのですが、ビジネスデータなどでは、各主成分がどんな意味を持つのかを、元の変数との関係性から慎重に考察する必要があります。
- 情報の損失次元を削減する以上、どうしても一部の情報は失われてしまいます。累積寄与率を確認しながら、どれくらいの情報損失なら許容できるかを判断することが重要です。
少しだけ数式を覗いてみよう
「うっ、数式は苦手…」と思ったあなた、待ってください!
ここでは、主成分分析が裏側で何をやっているのか、その雰囲気を掴むためのものなので、完璧に理解できなくても大丈夫です。
主成分分析の核心は、実は「固有値問題」と呼ばれる数学の問題を解くことにあります。
データのばらつき具合を表す「分散共分散行列」というものがあり、この行列を使って以下の計算をしています。

この式を解くことで、データのばらつきが最も大きい方向(v: 固有ベクトル)と、その方向へのばらつきの大きさ(λ: 固有値)を見つけ出しています。
そして、この「ばらつきが最も大きい方向」こそが「第1主成分」の正体なのです!
固有値が大きいほど、その主成分がたくさんの情報を持っている(寄与率が高い)ということになります。
まとめ:次のステップへ!
今回は、たくさんの情報をギュッと要約する魔法のような手法、「主成分分析」について解説しました。
ポイントを振り返ってみましょう。
- 主成分分析は、たくさんの変数を、情報をなるべく失わずに、より少ない「主成分」という新しい指標に要約する手法。
- 「次元削減」によって、データの可視化や機械学習モデルの精度向上に役立つ。
- 「寄与率」や「累積寄与率」を見ることで、いくつの主成分を採用すればよいかを判断する。
- ただし、作られた主成分の解釈が難しいというデメリットもある。
さて、主成分分析の世界に一歩足を踏み入れたあなたへの、今後の学習指針です。
- まずは使ってみよう!理論を学ぶのも大切ですが、まずは実際に手を動かしてみるのが一番です!Pythonのscikit-learnやRといった言語・ライブラリを使えば、驚くほど簡単に主成分分析を実行できます。サンプルデータを使って、今日学んだことを試してみてください。
- 他の次元削減手法も知ろう次元削減の手法は主成分分析だけではありません。「因子分析」や、非線形なデータに強い「t-SNE」「UMAP」といった手法もあります。主成分分析との違いを学ぶことで、状況に応じた最適な手法を選べるようになります。
- 線形代数を復習しようもし、数式の話で「もっと知りたい!」と思ったなら、大学で学んだ(かもしれない)線形代数の教科書をもう一度開いてみてください。「固有値」や「固有ベクトル」について復習すると、主成分分析が何をしているのか、より深く、本質的に理解できるようになりますよ。
データ分析の道は奥が深いですが、一つ一つ武器を身につけていけば、必ず乗り越えられます。
応援しています!
セイ・コンサルティング・グループの新人エンジニア研修のメニューへのリンク
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。

