
【初心者向け】機械学習の「成績の付け方」!交差エントロピーと平均二乗誤差の賢い使い分け
 山崎講師
山崎講師こんにちは。ゆうせいせいです。
「機械学習モデルを学習させる」と一言で言っても、モデルが賢くなっているのか、それとも見当違いの方向に進んでいるのか、どうやって判断すれば良いのでしょうか?
今回は、機械学習モデルの「成績」を付ける役割を担う「誤差関数(損失関数)」について、特に重要な「交差エントロピー」と「平均二乗誤差」に焦点を当てて、その違いと使い分けを解説していきます!
そもそも誤差関数って何?
まず、「誤差関数」という言葉自体が難しく聞こえるかもしれませんね。
簡単に言うと、誤差関数とは「モデルの予測」と「実際の正解」が、どれくらいズレているかを測るための「ものさし」です。
学校のテストを想像してみてください。あなたの解答(モデルの予測)と、先生が持っている模範解答(実際の正解)を比べて、点数を付けますよね?100点満点なら完璧、0点なら全然ダメ、というように。
誤差関数は、この「テストの採点」のような役割を果たします。予測が正解に近ければ近いほど誤差は小さく(点数が高く)なり、逆に大きく外れていれば誤差は大きく(点数が低く)なります。機械学習の目標は、この誤差をできるだけ小さくすること、つまり「テストで高得点を取ること」なのです。
平均二乗誤差:距離で測るシンプルな採点官
数ある誤差関数の中でも、最も直感的で分かりやすいのが「平均二乗誤差(Mean Squared Error, MSE)」でしょう。
これは、予測したいものが「数値」である「回帰問題」でよく使われます。例えば、家の広さや駅からの距離といった情報から、その家の価格を予測するようなケースです。
平均二乗誤差の考え方
平均二乗誤差の採点方法はとてもシンプルです。
- 「予測した価格」と「実際の価格」の差を計算する。
- その差を2乗する(マイナスをなくし、ズレが大きいほどペナルティを重くするため)。
- 全てのデータで計算した2乗の値を平均する。
式で書くと少し難しく見えますが、やっていることはこれだけです。

ここで、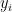

例えるなら、的当てゲームのようなものです。的の中心(正解)から、あなたの投げた矢(予測)がどれだけ離れているか、その「距離」を測っているイメージですね。距離が遠いほど、ペナルティが大きくなるわけです。
交差エントロピー:自信まで評価する厳しい採点官
では、家の価格のような数値ではなく、「この画像は犬か?猫か?」を当てるような「分類問題」ではどうでしょうか。
平均二乗誤差を無理やり使うこともできなくはないですが、実はあまり相性が良くありません。なぜなら、分類問題の答えは「犬(1)」か「猫(0)」のようにカチッとしたもので、予測の「ちょっとしたズレ」をうまく評価できないからです。
そこで登場するのが「交差エントロピー(Cross Entropy)」です。
交差エントロピーの考え方
交差エントロピーは、モデルの予測が「どれだけ正解の確率分布に近いか」を測るためのものさしです。
「確率分布」なんて言葉が出てきて、少し戸惑いましたか?大丈夫です。
先ほどの犬猫クイズで考えてみましょう。モデルは最終的に、「犬である確率80%、猫である確率20%」のように、それぞれの選択肢に対する「自信度」を確率で出力します。これが予測の確率分布です。
一方、正解は「犬」なので、正解の確率分布は「犬である確率100%、猫である確率0%」となります。
交差エントロピーは、この2つの確率分布(モデルの自信度と、絶対的な正解)がどれだけ似ているかを評価します。
そして、交差エントロピーが非常に賢いのは、「自信満々に間違えた」ときに、とてつもなく大きなペナルティを与える点です!
例えば、
- 正解が「犬」なのに、「猫の確率99%」と予測してしまった場合 -> 莫大なペナルティ!
- 正解が「犬」で、「犬の確率60%」と少し自信なさげに予測した場合 -> 小さなペナルティ
このように、ただの正解・不正解だけでなく、その予測の「自信」まで考慮して採点してくれる、非常に厳しいけれど優秀な採点官なのです。
数式は少し複雑に見えるかもしれませんが、この「自信満々な間違いに厳しい」というコンセプトを表現しています。

ここで、は正解(犬なら1, 猫なら0)、
はモデルの予測確率です。logという関数が、予測確率が0に近づく(=自信満々に間違える)ほど、マイナス無限大に近づく性質を持っているため、大きなペナルティを生み出すことができるのです。
まとめ:結局、どう使い分けるの?
ここまで長々と説明してきましたが、使い分けは驚くほどシンプルです。
| 問題の種類 | 主に使われる誤差関数 | 例え |
| 回帰問題(数値を予測) | 平均二乗誤差 | 的当てゲームの「距離」 |
| 分類問題(カテゴリを予測) | 交差エントロピー | 自信度まで見る「厳しい採点官」 |
基本的にはこのルールに従っておけば、まず間違うことはありません。
次のステップへ
今回は、機械学習における「成績の付け方」である誤差関数、特に代表的な2つを紹介しました。
- 平均二乗誤差は、予測値と正解値の「距離」を測るシンプルな方法で、主に回帰問題で使われる。
- 交差エントロピーは、予測の「確率」と正解の「確率」を比較し、特に自信を持って間違えた場合に大きなペナルティを与えることで、分類問題を効率的に学習させる。
この考え方が分かると、なぜモデルがうまく学習したり、しなかったりするのか、その一端が見えてくるはずです。
もしさらに興味が湧いたら、「平均絶対誤差(MAE)」や、分類問題でデータに偏りがある場合に活躍する「Focal Loss」といった、他の誤差関数について調べてみるのも面白いですよ。
モデルの気持ちになって、最適な採点方法を選んであげられるよう、一歩ずつ学習を進めていきましょう!
セイ・コンサルティング・グループの新人エンジニア研修のメニューへのリンク
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。

