
【統計学の探偵】犯人は誰だ?「最尤推定」を新人エンジニアに直感的に解説
 山崎講師
山崎講師これまでの流れで、確率、オッズ、そしてロジスティック回帰の式の正体について解説してきました。
ここで新人エンジニアのみなさんに一つ、大きな疑問が生まれているはずです。
「式の形(モデル)はわかったけど、その中の具体的な数値(パラメータ)はどうやって決めているの?」
ロジスティック回帰で出てきた係数 

そこで登場するのが、統計学における「名探偵」とも呼べる手法、「最尤推定(さいゆうすいてい)」です。
今回は、データから「真犯人(最適なパラメータ)」を見つけ出すこの手法について解説します。
【統計学の探偵】犯人は誰だ?「最尤推定」を新人エンジニアに直感的に解説
こんにちは。ゆうせいです。
みなさんは、ミステリー小説や刑事ドラマは好きですか?
現場に残された「証拠」をもとに、複数の容疑者の中から「もっとも犯行を行いそうな人物」を推理する。あのプロセス、ドキドキしますよね。
実は、データ分析における「最尤推定(さいゆうすいてい)」という手法は、まさにこの「名探偵の推理」そのものなんです。
「難しそうな漢字が出てきた…」と身構える必要はありません。「尤(ゆう)」という字は、「もっともらしい」という意味です。つまり、「一番もっともらしい答えを推測する」という、とてもシンプルな考え方なんです。
今日は、機械学習のパラメータ決定で必ず使われるこの手法について、数式というよりは「推理ロジック」として解説していきます。
「確率」と「尤度(ゆうど)」の違い
最尤推定を理解するための最大の壁は、「確率(Probability)」と「尤度(Likelihood)」の違いです。
この2つ、似ているようでいて、視点が真逆なんです。
刑事ドラマで例えてみましょう。
1. 確率(Probability):犯人を知っていて、結果を予想する
「犯人は怪盗Xだ(モデルが確定している)。あいつの性格なら、90%の確率で宝石店を狙うだろう(結果を予測)」
これが確率です。「原因 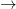
2. 尤度(Likelihood):結果を知っていて、犯人を予想する
「宝石店が襲われた(結果・データが確定している)。容疑者はA、B、Cの3人だ。この状況証拠からして、怪盗Xが犯人である可能性(もっともらしさ)が一番高い」
これが尤度です。「結果
エンジニアが手にするのは常に「すでに起きたデータ(ログ)」ですよね。だから、データ分析では「確率」ではなく「尤度」を使って、裏にある仕組み(パラメータ)を逆探知するのです。
具体例:イカサマコインを見抜け!
もっと具体的な例で見てみましょう。ここに1枚のコインがあります。
このコインを3回投げたら、「表、表、表」と3回連続で表が出たとします。
さて、このコインの「表が出る確率(パラメータ 
推理1:普通のコイン説(  )
)
もしこれが普通のコインなら、3回連続で表が出る確率は…

うーん、ありえなくはないですが、ちょっと珍しいですね。
推理2:イカサマコイン説(  )
)
もしこれが「9割表が出るイカサマコイン」なら、3回連続で表が出る確率は…

おっ! これなら「表、表、表」という結果になっても全然不思議じゃありません。
推理3:絶対表が出るコイン説(  )
)
もしこれが「両面表のコイン」なら、確率は…

これこそが、今の結果を「もっともよく説明できる」仮説です。
このように、手元のデータ(表が3回)が起きる確率が一番高くなるように、パラメータ(
これが「最尤推定」です。今回の場合、最尤推定値は
数式で見る「掛け算」の正体
今の推理を数式にしてみましょう。
あるパラメータ 


尤度関数

「それぞれのデータが起きる確率を全部掛け合わせたもの」が、全体の尤もらしさになります。
この 
なぜ「対数(Log)」をとるの?
しかし、ここでエンジニア泣かせの問題が発生します。
確率は必ず「1以下」の数字ですよね?

そこで登場するのが、以前も少し触れた「対数(Log)」です。
掛け算を足し算に変える魔法です。
対数尤度

- 掛け算が足し算になるので計算が楽。
- 値が小さくなりすぎない。
- 「最大値になる場所」はログをとっても変わらない。
だから、実際のデータ分析の現場では、尤度をそのまま最大化するのではなく、「対数尤度(Log-Likelihood)」を最大化する計算を行っているのです。
機械学習とのつながり:損失関数
最後に、機械学習を勉強しているとよく聞く「損失関数(Loss Function)の最小化」との関係をお話しします。
「最尤推定は『最大化』なのに、機械学習は『最小化』? 逆じゃない?」
と思った鋭いあなた。実はこれ、同じことを言っているんです。
「山の頂上(尤度の最大値)を目指す」のと、「谷底(マイナスの尤度の最小値)を目指す」のは、地図をひっくり返して見ているだけで、結局たどり着く場所(最適なパラメータ)は同じですよね。
機械学習(特に分類問題)で使われる「交差エントロピー誤差」という損失関数は、実はこの「対数尤度にマイナスをつけたもの」そのものなんです。
- 尤度を最大化したい
もっともらしいモデルを作りたい
- 誤差を最小化したい
表現は違いますが、目指しているゴール(真犯人の特定)は一緒なんですね。
まとめ:データが一番輝く設定を探せ
ここまで読んでいただき、ありがとうございます。
最尤推定のイメージ、掴んでいただけましたか?
- 確率:モデルからデータを予測する。
- 尤度:データからモデル(犯人)を逆探知する。
- 最尤推定:「今あるデータが、一番高い確率で発生するような設定(パラメータ)」を探し出すこと。
- 計算のために対数(Log)をとって足し算にするのが定石。
ロジスティック回帰も、ディープラーニングも、裏側ではこの「最尤推定」を使って、
「今のデータに一番フィットするパラメータは君だ!」
と、最適な係数を探し出しているのです。
今後の学習の指針
「最大値を探す」というゴールは決まりました。では、具体的にどうやってその山の頂上まで登っていけばいいのでしょうか?
そこで使われるのが、「勾配降下法(こうばいこうかほう)」というアルゴリズムです。
以前解説した「微分の傾き」を使って、一歩ずつ正解に近づいていく泥臭くも強力な手法です。次はぜひこれを学んでみてください。
それでは、また次回の記事でお会いしましょう!
セイ・コンサルティング・グループの新人エンジニア研修のメニューへのリンク
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。

