
モデルの成績表!決定係数R^2(R二乗)がなぜ有効なのか、その意味と注意点を解説
 山崎講師
山崎講師こんにちは。ゆうせいです。
データ分析や統計学を学び始めると、必ずと言っていいほど登場する「決定係数(けっていけいすう)」。 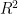
「決定係数が高いほど、良いモデルです」と説明されることが多いですが、「なぜこれが高いと『良い』と判断できるの?」「そもそも何を表しているの?」と疑問に思う方もいるかもしれません。
決定係数は、一言でいえば「作った予測モデルの『当てはまり度』を示す成績表」のようなものです。
この記事では、決定係数がなぜモデルの評価に「有効」なのか、その理由を初心者の方にも分かりやすく、例え話を交えて解説していきます!
そもそも「決定係数(R^2)」って何?
まずは、この専門用語が何者なのかを知る必要がありますね。
決定係数(R^2)とは、統計学の「回帰分析(かいきぶんせき)」という手法で使われる指標です。
回帰分析とは、例えば「勉強時間(説明変数)」から「テストの点数(目的変数)」を予測する、といったように、あるデータから別のデータを予測する「予測モデル(予測式)」を作る手法のことです。
そして、決定係数は、「その作った予測モデルが、実際のデータをどれだけうまく説明できているか」の度合いを、0から1(または0%から100%)の数値で示してくれるものです。
- 決定係数が1に近い:モデルが実際のデータをほぼ完璧に説明できている(予測がよく当たっている)。
- 決定係数が0に近い:モデルが実際のデータをほとんど説明できていない(予測が当たっていない)。
このように、予測モデルの「成績」を0点から100点満点(あるいは0から1)で示してくれる、とても便利な指標なんです。
決定係数が「有効」とされる3つの理由
では、なぜ多くの分析でこの決定係数が使われ、「有効」とされているのでしょうか?
それには、大きく分けて3つの理由があります。
理由1:直感的に「分かりやすい」から
これが最大の理由かもしれません。
決定係数は「0から1」という範囲に収まるように設計されています(※厳密にはマイナスになることもありますが、基本は0〜1です)。
「モデルAの当てはまり度は0.85です」
「モデルBの当てはまり度は0.30です」
と言われれば、「ああ、モデルAの方が断然良さそうだな」と、専門的な知識がなくても直感的に理解できますよね。
「85%くらい当てはまってるんだな」というように、パーセンテージとして解釈できるのが、決定係数の非常に強力な点です。
理由2:「説明できた割合」を示してくれるから
決定係数は、別名「寄与率(きよりつ)」とも呼ばれます。
これは、データの「全体のばらつき」のうち、どれくらいの割合(何%)を、その予測モデルが「説明できたか」を示しているからです。
例え話:テストの点数の「ばらつき」
クラス全員のテストの点数を想像してください。
点数には「ばらつき」がありますよね(平均点の人もいれば、高い人、低い人もいます)。
この「ばらつき」には、色々な原因があるはずです。
「勉強時間の違い」「塾に行っているか」「睡眠時間」など…。
ここで、あなたが「勉強時間」だけを使って、点数を予測するモデルを作ったとします。
その結果、決定係数が 
これは、「クラスの点数の『ばらつき』のうち、60%は『勉強時間』で説明できましたよ!」ということを意味します。
残りの40%は、勉強時間以外の要因(塾、睡眠、才能など)による「説明できていないばらつき(=誤差)」ということになります。
このように、モデルがデータのばらつきをどれだけ「説明」できたかを、割合で示してくれるのが決定係数の有効な点です。
理由3:モデル同士を「比較」できるから
あなたが、テストの点数を予測するために、2つの異なるモデルを作ったとします。
- モデルA:「勉強時間」だけで予測するモデル
- モデルB:「勉強時間」と「睡眠時間」の2つで予測するモデル
どちらのモデルが、より「良い」予測モデルでしょうか?
こんなときに決定係数が活躍します。
もし、モデルAの決定係数が0.6で、モデルBの決定係数が0.7だった場合、「睡眠時間を加えたモデルBの方が、より点数のばらつきをうまく説明できている(=当てはまりが良い)」と判断することができます。
このように、異なるモデルの「当てはまりの良さ」を、同じ土俵で比較するための共通の尺度(モノサシ)として非常に有効なのです。
要注意!決定係数の「落とし穴」(デメリット)
ここまで決定係数の良いところを見てきましたが、実は万能ではありません。
特に知っておくべき「落とし穴」が一つあります。
それは、「説明変数を増やすと、決定係数は必ず(あるいは、ほぼ必ず)高くなってしまう」という性質です。
これはどういうことでしょうか?
先ほどの例で、「勉強時間」と「睡眠時間」(モデルB)に、さらに「好きなテレビ番組」(全く関係なさそうですよね?)というデータを加えて「モデルC」を作ったとします。
このとき、たとえ「好きなテレビ番組」が点数に全く関係なくても、モデルCの決定係数は、モデルB(0.7)よりもわずかに高くなってしまうのです。
極端な話、無関係なデータを100個集めてくれば、決定係数をほぼ1に近づけることさえできてしまいます。
これでは、「とりあえずデータをたくさん入れれば成績が上がる」という、意味のないモデルが出来上がってしまいますよね。
解決策:「自由度調整済み決定係数」
この「説明変数のドーピング」問題を解決するために、「自由度調整済み決定係数(じゆうどちょうせいずみ けっていけいすう)」という、少し改良された指標が用意されています。
これは、増えた説明変数の「数」に応じてペナルティを課すことで、無意味な変数を増やしても決定係数が上がりにくくなるように調整した指標です。
(説明変数が多いモデル同士を比較する際は、こちらを使うのが一般的です!)
まとめと今後の学習指針
今回は、決定係数(R^2)がなぜ有効なのかについて解説しました。
- 決定係数は、モデルがデータのばらつきをどれだけ説明できたかを示す「成績表」。
- 有効な理由は、「直感的な分かりやすさ(0〜100%)」と「モデル同士の比較ができる」点にある。
- 注意点として、無関係な説明変数を増やしても値が上がってしまう性質がある。
決定係数は、あなたの作ったモデルがどれくらい良いかを評価するための「第一歩」として、非常に強力なツールです。
この指標の意味をしっかり理解できたら、次はぜひ、今日少しだけ触れた「自由度調整済み決定係数」がどのような計算でペナルティを課しているのか、そしてモデルの「誤差(残差)」がどのような分布をしているかを見る「残差分析(ざんさぶんせき)」へと学習を進めてみてください。
モデルの「成績表」を正しく読み解くことで、データ分析はもっと深く、面白くなりますよ!
最後まで読んでいただき、ありがとうございました。
セイ・コンサルティング・グループの新人エンジニア研修のメニューへのリンク
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。
最新の投稿
 新人エンジニア研修講師2026年6月19日Spring BootでセッションIDがアドレスバーに表示される理由と対策|新人エンジニア向けにJSESSIONIDを解説
新人エンジニア研修講師2026年6月19日Spring BootでセッションIDがアドレスバーに表示される理由と対策|新人エンジニア向けにJSESSIONIDを解説- 新人エンジニア研修講師2026年6月18日JavaのOptionalでnullを安全に扱う方法|NullPointerExceptionを防ぎ、DAOの戻り値をわかりやすくする
- 新人エンジニア研修講師2026年6月18日ローカルSMTPを使って問い合わせ完了メールを送る方法|新人エンジニア研修向けにSpring BootとJavaMailSenderを解説
- 新人エンジニア研修講師2026年6月18日DevToolsでHTTP通信・エラー・DOMを確認する方法|新人エンジニア向けにブラウザ開発者ツールを解説
