機械学習の要「内積」を攻略!データ同士の「相性」を測る計算式
 山崎講師
山崎講師こんにちは。ゆうせいです。
前回は、データの大きさを1に揃える「単位ベクトル」についてお話ししました。
今回は、その単位ベクトルと切っても切れない関係にある、そして機械学習で最も頻繁に使われる計算の一つ、「内積(ないせき)」について解説します。
数学の教科書で「内積」という言葉を見た瞬間、ページを閉じた経験はありませんか。
記号や公式が並んでいて、なんだか難しそうですよね。
でも、怖がる必要はありません。
エンジニアの視点で見ると、内積は「データとデータの相性診断」を行うための、とても便利なツールなのです。
これを知っていると、AIがどうやって「この画像とこの画像は似ている」と判断しているのか、その裏側が手に取るようにわかるようになりますよ。
さあ、一緒に内積の世界を覗いてみましょう。
内積ってなに?
一言で言うと、内積とは二つのベクトルがどれくらい同じ方向を向いているかを表す数字です。
あるいは、「二つのデータがどれくらい似ているか」を表すスコアだと思ってください。
具体的なイメージを持とう
例えば、あなたがオンラインショップのオーナーだとします。
「お客さんの好み」を表すベクトルと、「商品の特徴」を表すベクトルがあると想像してください。
お客さんA:甘いものが好き、辛いものは嫌い
商品B(ケーキ):とても甘い、辛くない
この二つのベクトルには、「甘い」という共通点がありますよね。
方向性が一致しています。
このとき、内積を計算すると「大きなプラスの数字」になります。
逆に、こんな場合はどうでしょう。
お客さんA:甘いものが好き
商品C(激辛カレー):甘くない、とても辛い
好みの方向と、商品の特徴の方向が逆を向いています。
このとき、内積は「小さな数字」あるいは「マイナス」になります。
つまり、内積の計算結果が大きければ大きいほど、その二つのデータは「相性が良い」「似ている」と判断できるのです。
AIはこの計算を大量に行って、あなたにおすすめの商品を選んでいるのですね。
どうやって計算するの?
では、実際に計算してみましょう。
内積の計算方法は驚くほど簡単です。
同じ位置にある数字同士を掛けて、全部足す。たったこれだけです。
ベクトル 

- まず、X座標(1つ目の数字)同士を掛けます。
- 次に、Y座標(2つ目の数字)同士を掛けます。
- 最後に、それらを足します。



これでおしまいです。内積は 
拍子抜けするほど簡単ではありませんか。
この計算のことを「ドット積」と呼ぶこともあります。
高校数学では 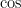
なぜなら、コンピュータにとってはこの四則演算の方が圧倒的に速いからです。
では、計算結果が 0(ゼロ) になったり、マイナス になったりするのはどんな時でしょうか?
実は、ここに内積の面白い性質が隠れています。
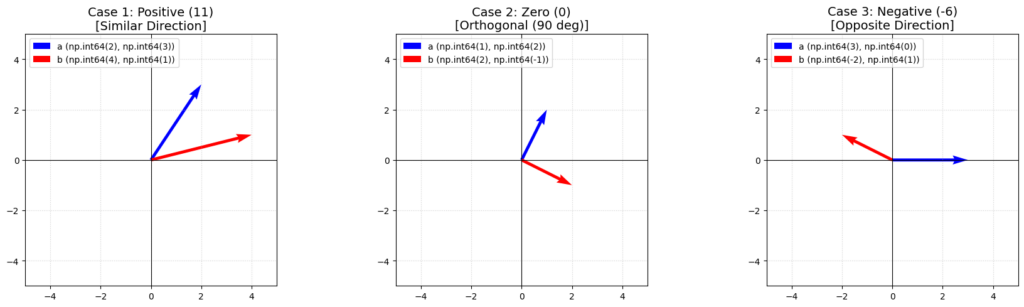
1. 結果が「0」になるケース
ベクトル $a = (1, 2)$ と、ベクトル $b = (2, -1)$ でやってみましょう。
- X座標: $1 \times 2 = 2$
- Y座標: $2 \times (-1) = -2$
- 足し算: $2 + (-2) = 0$
なんと、答えは $0$ になりました。
実はこれ、2つのベクトルが「直角(90度)」に交わっている 状態なんです。
「全く違う方向(無関係な方向)を向いていると、内積はゼロになる」。これは非常に重要なサインです。
2. 結果が「マイナス」になるケース
次は、ベクトル $a = (3, 0)$ と、ベクトル $b = (-2, 1)$ です。
- X座標: $3 \times (-2) = -6$
- Y座標: $0 \times 1 = 0$
- 足し算: $-6 + 0 = -6$
今度はマイナスになりました。
これは、2つのベクトルが 「反対方向」を向いている ことを意味します。
まとめると
計算自体は「掛けて足す」だけですが、その結果を見るだけで、2つの関係性が分かってしまうのです。
- プラスの大きな値: 「すごく似た方向を向いている!」(仲良し)
- ゼロ: 「直角だ!全く無関係な方向だ!」(無関心)
- マイナス: 「逆方向を向いている!」(仲が悪い)
AI(人工知能)が「この画像とこの画像は似ている」と判断したり、おすすめ商品を提案したりできるのも、裏側ではこの「掛けて足す」計算を高速に行って、数値が大きい(似ている)ものを探しているからなんですよ。
なぜ機械学習で重要なのか
エンジニアとして働く上で、内積がなぜこれほど重要視されるのでしょうか。
理由は主に二つあります。
1. 類似度の判定に必須
先ほどのショッピングの例のように、検索エンジンやレコメンドシステムでは「検索ワードとWebページの関連性」や「ユーザーと商品の相性」を計算する必要があります。
この「関連性スコア」を算出する計算式の正体が、実は内積なのです。
前回紹介した「単位ベクトル」と組み合わせることで、「コサイン類似度」という、より純粋な相性スコアを出すこともできます。
2. ニューラルネットワークの基礎演算
今のAIブームを支えている「ディープラーニング」も、中身を分解すれば内積の塊です。
ニューロン(神経細胞)が次のニューロンに信号を伝えるとき、「入力データ」と「重み(重要度)」の内積を計算しています。
「GPU」というパーツが機械学習に強いと言われるのは、この「掛けて足す」という単純な計算を、一度に何千、何万と並列処理するのが得意だからなのです。
メリットとデメリット
内積を使うことの利点と注意点も押さえておきましょう。
メリット
最大のメリットは「計算が高速であること」です。
複雑な条件分岐(if文)を書かなくても、単純な掛け算と足し算だけで「似ているかどうか」を判定できるため、コンピュータとの相性が抜群です。
また、結果が1つの数字(スカラー)になるため、スコアとして扱いやすいのも利点です。
デメリット
デメリットは、「ベクトルの長さに影響を受けること」です。
例えば、「少しだけ似ているけど、データ量が巨大なベクトル」と、「すごく似ているけど、データ量が小さいベクトル」があった場合、前者の方が内積の値が大きくなってしまうことがあります。
純粋に「方向の一致(似ている度合い)」だけを見たい場合は、前回解説した「正規化(単位ベクトル化)」という下準備が必要になります。
Pythonで確認してみよう
今回もPythonのNumPyを使って計算してみましょう。
dot という関数を使います。
import numpy as np
# ベクトルの定義
a = np.array([2, 3])
b = np.array([4, 1])
# 内積の計算
result = np.dot(a, b)
print(result)
# 出力: 11
手計算と同じ
どんなに次元が増えても(数字の並びが増えても)、np.dot 一発で計算してくれます。
まとめ
いかがでしたか。
内積とは、難しい記号の羅列ではなく、「同じ成分同士を掛けて足す」ことで「二つのデータの相性」を導き出す計算のことでした。
機械学習のモデルが「学習する」というのは、実はこの内積の結果が正解に近づくように、パラメータを微調整していると言い換えることもできます。
それくらい、内積はAIの心臓部を担っているのです。
次回の学習の指針ですが、内積をたくさん並べて一気に計算する技術である「行列(マトリックス)の積」に進んでみましょう。
ここを乗り越えれば、機械学習の数式が怖くなくなりますよ。
またいつでも、質問してくださいね。
一緒に一歩ずつ進んでいきましょう。
セイ・コンサルティング・グループの新人エンジニア研修のメニューへのリンク
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。