AIはどうやって反省する?「損失関数」で誤差を数値化する仕組み
 山崎講師
山崎講師こんにちは。ゆうせいです。
前回は、AIに人間のような表現力を与える「活性化関数」についてお話ししました。
シグモイド関数を使って、データを確率(0から1の数字)に変換できるようになったわけです。
さて、ここで一つ質問です。
AIが「これは80%の確率で犬です!」と自信満々に答えたとします。
でも、もしその画像が「猫」だったらどうしますか。
「違うよ!猫だよ!」と教えてあげないといけませんよね。
人間なら言葉で伝えれば分かりますが、計算式で動いているAIには「どれくらい間違っていたのか」を数字で突きつけてあげる必要があります。
そこで登場するのが、今回のテーマ「損失関数(そんしつかんすう)」です。
これは、AIの出した答えに対する「採点係」のようなものです。
AIが賢くなる(学習する)ためには、自分の間違いを正確に知ることが絶対に必要なのです。
この「間違いの測り方」には、エンジニアたちが知恵を絞った工夫が詰まっています。
一緒に見ていきましょう。
損失関数ってなに?
一言で言うと、損失関数とは「AIの予測」と「正解」のズレ(誤差)を計算する式のことです。
機械学習の目的は、この損失関数の値をできるだけ「0」に近づけることです。
損失関数の値が大きいということは、「全然当たっていない(損失が大きい)」状態。
逆に値が小さければ、「かなり正解に近い(損失が少ない)」状態を意味します。
いわば、AIにとっての「テストの減点スコア」ですね。
0点(満点)を目指して、AIはひたすら努力を続けるわけです。
どうやってズレを測る?
ズレを測るなんて、単に引き算すればいいだけでは?
そう思った方もいるかもしれません。
例えば、正解が 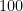
AIの予測が 

AIの予測が 

もし、この二つのズレを単純に足し合わせて平均をとるとどうなるでしょう。

これでは、AIは「自分は完璧だ(誤差0だ)」と勘違いしてしまいますよね。本当はどちらも間違っているのに。
だから、単純な引き算ではダメなのです。
具体的な計算方法:二乗和誤差
そこでよく使われるのが、「二乗和誤差(にじょうわごさ)」という計算方法です。
名前はいかついですが、やっていることはシンプルです。
「引き算して、2乗する」
これだけです。
先ほどの例で計算してみましょう。
- 予測
2乗する:
- 予測
2乗する:


こうすれば、マイナスのズレもプラスになります。
これらを足し合わせると 
なぜ「絶対値」じゃなくて「2乗」なの?
マイナスを消すだけなら、絶対値( 
なぜわざわざ2乗するのでしょうか。
理由は主に二つあります。
- 大きな間違いを厳しく罰するため2乗すると、ズレが大きければ大きいほど、値が雪だるま式に大きくなります。ズレが
なら誤差は
ですが、ズレが
なら誤差は
- 計算(微分)がしやすいからここがエンジニア的には重要です。絶対値のグラフは底がV字型に尖っていて、数学的に扱いづらい点があります。一方、2乗のグラフ(放物線)は底が丸くなっていて、どこでも滑らかに計算(微分)ができます。AIが「どっちに修正すればいいか」を探るときに、この滑らかさがとても有利に働くのです。
なぜ機械学習で重要なのか
損失関数は、機械学習における「ゴールの旗印」です。
AIは最初、パラメータ(重み)がデタラメなので、損失関数の値は巨大になります。
そこで、AIはこう考えます。
「どうパラメータを変えれば、この損失関数の値を少しでも小さくできるだろうか?」
この問いに対する答えを探すプロセスこそが「学習」そのものです。
損失関数がなければ、AIは自分が正しいのか間違っているのか分からず、暗闇の中を彷徨うことになってしまいます。
損失関数は、AIを正解へと導く羅針盤なのです。
メリットとデメリット
今回紹介した「二乗和誤差」について、良い点と悪い点を整理しましょう。
メリット
直感的で分かりやすいことです。「正解からの距離」を測っている感覚に近いので、数値の予測(回帰問題)で非常によく使われます。また、計算式が単純なので、微分などの処理も簡単です。
デメリット
外れ値(異常値)に弱いという点です。
2乗するという性質上、たまたまデータの中に一つだけとんでもない間違いがあると、その誤差が 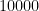
すると、AIはそのたった一つの例外を合わせようとして、他のまともなデータの学習をおろそかにしてしまうことがあります。
ちなみに、分類問題(犬か猫かなど)では、「クロスエントロピー誤差」という別の損失関数がよく使われます。こちらは確率の考え方に基づいた計算式ですが、目的は同じく「ズレを最小にする」ことです。
Pythonで確認してみよう
では、二乗和誤差をPythonで計算してみましょう。
NumPyを使うと、複数のデータもまとめて計算できます。
import numpy as np
# AIの予測した値
y = np.array([0.8, 0.4])
# 本当の正解(教師データ)
t = np.array([1.0, 0.1])
# 1. ズレを計算(予測 - 正解)
diff = y - t
print(f"ズレ: {diff}")
# 出力: [-0.2 0.3]
# 2. 二乗する
squared = diff ** 2
print(f"二乗誤差: {squared}")
# 出力: [0.04 0.09]
# 3. 合計して平均をとる(これが平均二乗誤差 MSE)
loss = np.sum(squared) / len(t)
print(f"損失関数の値: {loss}")
# 出力: 0.065
この 0.065 という数字が、今のAIの成績表です。
学習が進むにつれて、この数字が 0.001 ... 0.0001 とどんどん小さくなっていく様子を見るのが、機械学習エンジニアの楽しみの一つでもあります。
まとめ
いかがでしたか。
損失関数とは、AIの予測と正解の「ズレ」を、2乗などの工夫をして数値化したものでした。
AIはこの「損失」を最小にするために、ひたすら努力を続けます。
人間で言えば、「テストの点数が悪かったから、次は間違えたところを重点的に復習しよう」と反省するプロセスに似ていますね。
さて、ここで一つ疑問が湧きませんか。
「間違いの量はわかった。でも、具体的にどうすればその間違いを減らせるの?」
点数が悪いことは分かっても、どう勉強すればいいか分からなければ成績は上がりませんよね。
そこで次回は、損失関数の値を小さくするための具体的な手順、「勾配降下法(こうばいこうかほう)」について解説します。
いよいよ、AIが学習する瞬間の核心に迫りますよ。
分からないことがあれば、いつでも質問を投げかけてくださいね。
一緒にAIの気持ちになって考えていきましょう。
セイ・コンサルティング・グループの新人エンジニア研修のメニューへのリンク
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。