
ハフマン符号化のJavaでの実装
 山崎講師
山崎講師突然ですが、皆さんはモールス信号をご存知でしょうか?
有名なものは「SOS」ですね。S「・・・」とO「---」を組み合わせて「・・・---・・・」(トントントンツーツーツートントントン)と打ちます。
以下のリンクを辿ってアルファベットのモールス信号の一覧を見てください。(https://www.jrc.co.jp/casestudy/column/04)
例えば、eは短く、zは長いですが、これは英文の文字の出現頻度と相関しています。つまり、出現頻度の高い文字は短く、出現頻度の低い文字は長くなっています。これと同じ考え方をするのがハフマン符号化です。
ハフマン符号化は、可逆圧縮アルゴリズムの一種です。
ハフマン符号化は、ランレングス符号化とは異なり、頻繁に出現する文字やシンボルに短いビットパターンを割り当て、まれに出現する文字やシンボルに長いビットパターンを割り当てることにより、圧縮率を向上させます。なお、符号化とはデータを0,1のビットで表現することをいいます。
ハフマン符号化では、まずデータの出現頻度を調べ、その情報を使用してハフマン木を構築します。ハフマン木は、出現頻度が高いデータほど木の根に近く配置され、出現頻度が低いデータほど木の葉に近く配置されます。次に、ハフマン木の左側に0を、右側に1を割り当てて、各データに対応する符号を生成します。この符号は、木の根から各葉に至るまでの0と1の組み合わせで表されます。
ハフマン符号化は、圧縮アルゴリズムの中でも効率的なものの一つです。ハフマン符号化は、音声、画像、ビデオ、テキストなど、様々な種類のデータの圧縮に利用されています。
ハフマン符号化は以下の分野で活用されています。
- データ圧縮: ハフマン符号化は、元のデータを効率的に圧縮するために使用されます。特に、テキストや画像、音声、ビデオなど、大量のデータを扱う場合によく使われます。zipやLHZ圧縮でも使われているアルゴリズムです。
- 通信システム: ハフマン符号化は、通信システムにおいて、データ転送の効率化や誤り検出・訂正などに利用されます。例えば、音声圧縮の規格であるMP3やAAC、画像圧縮の規格であるJPEGやPNG、さらには通信規格のLTEや5Gなど、様々な通信技術においてハフマン符号化が使用されています。
講師が実際にハフマン木を書いて説明します。

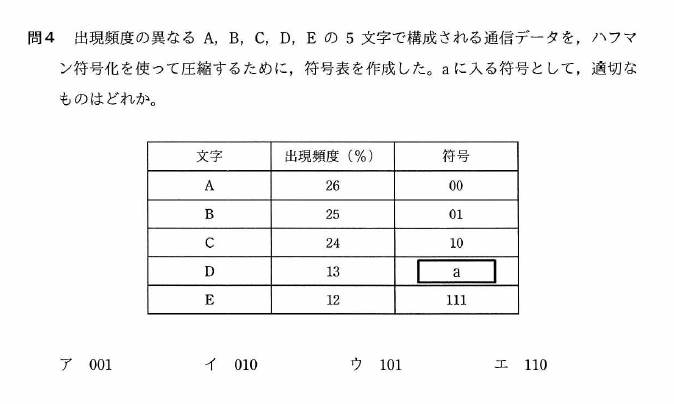
基本情報技術者試験の過去問を解いてみましょう。
練習問題1
基本情報技術者試験 平成30年秋期 午前問4
<サンプルプログラム>
import java.util.HashMap;
import java.util.Map;
import java.util.PriorityQueue;
public class HuffmanEncoding {
private static Map<Character, String> huffmanCodes = new HashMap<>();
// ハフマンツリーのノードを表す内部クラス
private static class HuffmanNode implements Comparable<HuffmanNode> {
char ch; // 文字
int freq; // 出現頻度
HuffmanNode left; // 左の子ノード
HuffmanNode right; // 右の子ノード
HuffmanNode(char ch, int freq, HuffmanNode left, HuffmanNode right) {
this.ch = ch;
this.freq = freq;
this.left = left;
this.right = right;
}
// 葉ノードかどうかを判定するメソッド
public boolean isLeaf() {
return left == null && right == null;
}
// 出現頻度を比較するメソッド
public int compareTo(HuffmanNode node) {
return this.freq - node.freq;
}
}
// ハフマンツリーを構築する関数
private static void buildHuffmanTree(String text) {
// 文字の出現頻度をカウントするためのマップを作成
Map<Character, Integer> freqMap = new HashMap<>();
for (char ch : text.toCharArray()) {
freqMap.put(ch, freqMap.getOrDefault(ch, 0) + 1);
}
// 出現頻度に基づいて優先度付きキュー(PriorityQueue)を作成
PriorityQueue<HuffmanNode> priorityQueue = new PriorityQueue<>();
for (Map.Entry<Character, Integer> entry : freqMap.entrySet()) {
priorityQueue.offer(new HuffmanNode(entry.getKey(), entry.getValue(), null, null));
}
// ハフマンツリーを構築する
while (priorityQueue.size() > 1) {
HuffmanNode left = priorityQueue.poll();
HuffmanNode right = priorityQueue.poll();
HuffmanNode parent = new HuffmanNode('\0', left.freq + right.freq, left, right);
priorityQueue.offer(parent);
}
// ルートノードを取得し、符号を構築する
HuffmanNode root = priorityQueue.peek();
buildHuffmanCode(root, "");
}
// ハフマン符号を構築する再帰関数
private static void buildHuffmanCode(HuffmanNode node, String code) {
if (node.isLeaf()) {
huffmanCodes.put(node.ch, code); // 葉ノードの場合、符号をマップに追加
return;
}
buildHuffmanCode(node.left, code + "0"); // 左の子ノードに0を追加して再帰呼び出し
buildHuffmanCode(node.right, code + "1"); // 右の子ノードに1を追加して再帰呼び出し
}
// テキストをハフマン符号化する関数
public static String huffmanEncode(String text) {
buildHuffmanTree(text); // ハフマンツリーを構築し、文字に対する符号を生成します。
StringBuilder encodedText = new StringBuilder();
for (char ch : text.toCharArray()) {
encodedText.append(huffmanCodes.get(ch) + " "); // 各文字の符号を取得して符号化テキストに追加
}
return encodedText.toString(); // 符号化されたテキストを文字列として返す
}
// メインの処理
public static void main(String[] args) {
String text = "baggage";
String encodedText = huffmanEncode(text);
System.out.println("Original text: " + text);
System.out.println("Encoded text: " + encodedText);
}
}<出力結果>
| Original text: baggage Encoded text: 110 10 0 0 10 0 111 |
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。
最新の投稿
 山崎講師2026年8月1日コンピューターが数値計算の誤差に対処する仕組みと精度管理の方法
山崎講師2026年8月1日コンピューターが数値計算の誤差に対処する仕組みと精度管理の方法- 山崎講師2026年8月1日0乗が1になる理由を2乗の計算式から解説する指数法則の基礎
- 山崎講師2026年8月1日機械学習モデルの予測理由を解釈するSHAPとシャープレイ値の基礎
- 山崎講師2026年8月1日適合率と再現率の概念と初心者向けのわかりやすい再翻訳案
