
「AIって数学が得意な人だけの話でしょ?」と思っていませんか?
じつは、数学の知識は中学校〜高校レベルで十分理解できます。この章では、G検定にも出題されるAIの基礎を支える5つの数学・統計分野について、やさしく解説していきます。
3.1 確率・統計の基礎
AIは「未来を予測する」技術。つまり、不確実なことを扱うには確率と統計が必要不可欠です。
確率の基本
- 確率:ある事象が起こる可能性(0〜1の値)
- 条件付き確率
:Bが起こったあとにAが起こる確率
- ベイズの定理:

これはナイーブベイズ分類器などに使われる超重要公式です。
期待値:
確率に基づく「平均値」。「長期的に見て平均するとどうなるか?」を表します。
例:サイコロの出目の期待値は

3.2 基礎統計量
統計の基本
- 平均(Mean):すべての値の合計 ÷ 件数
- 分散(Variance):データのばらつき具合
- 標準偏差(Standard Deviation):分散の平方根
AIでは、データの傾向をつかむために統計的な指標が多用されます。
標準偏差とは?
まず、標準偏差(standard deviation)とは、データのばらつき(散らばり具合)を数値で表したものです。
例えば、テストの点数が全員90点なら、ばらつきはゼロに近いですよね。でも、ある人が100点で別の人が40点なら、その点数のばらつきは大きくなります。これを数式で表すと次のようになります:
(シグマは、データの個数Nで平均値μからの差の2乗を平均して、平方根を取る)

ポイントは、「平均からどれだけ離れているか」の平均を取っているということです。
機械学習で標準偏差が使われる場面
では、この標準偏差が機械学習でどのように役立つのでしょうか?
大きく分けて次の3つの場面があります。
① 特徴量のスケーリング(標準化)
機械学習では、「特徴量(feature)」というデータの個々の値を使って学習を行います。
このとき、特徴量の単位や値のスケール(大きさ)が異なると、学習がうまくいかないことがあります。
例:
ある特徴量Aが「身長(cm)」で100〜200、
別の特徴量Bが「年齢(歳)」で10〜80だったとします。
このままだと、値の大きい身長が強く影響してしまい、バランスが取れません。
そこでよく使われるのが「標準化(Z-score標準化)」という方法です:
(平均を引いて、標準偏差で割る)

この処理を行うことで、すべての特徴量を「平均0・標準偏差1」のスケールに整えられます。
② モデルの予測の安定性チェック
機械学習では、交差検証という手法を使ってモデルの性能を評価します。
あるデータセットに対して複数回訓練と評価を繰り返し、それぞれの精度(accuracy)を記録します。
このとき、精度の平均だけを見るのではなく、「標準偏差」も見ることで、モデルの安定性がわかります。
- 標準偏差が小さい → どの分割でも同じくらいの精度 → 安定している
- 標準偏差が大きい → 精度にムラがある → 過学習の可能性あり
③ 異常検知(Anomaly Detection)
製造業や金融分野では「異常なデータを見つけたい」というニーズがよくあります。
ここでも標準偏差が使われます。
例えば「通常の取引額の標準偏差を超えたら異常」と判断することで、不正取引の検出が可能になります。
3.3 二変数間の関係
■ 相関係数とは?
まず、相関係数(correlation coefficient)とは、2つの変数の間にどの程度の「直線的な関係」があるかを数値で示すものです。代表的なものがピアソンの積率相関係数(Pearson’s r)です。
数式は以下の通りです:
(r は X と Y の共分散を、それぞれの標準偏差で割ったもの)

この値は −1〜1 の範囲を取り、
- 1:完全な正の相関(Xが増えるとYも増える)
- 0:無相関(関係なし)
- −1:完全な負の相関(Xが増えるとYは減る)
という意味になります。
たとえば、「身長」と「体重」は正の相関がありますよね?背が高い人ほど重い傾向にあります。ただし、相関があるからといって、因果関係があるとは限らない点に注意してください!
回帰係数とは?
一方、回帰係数(regression coefficient)は、ある変数が他の変数にどれだけ影響を与えるかを数式として表したものです。
単回帰分析における回帰式は以下です:
(yの予測値は、切片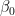


このβ₁(ベータワン)が回帰係数です。
意味としては、「xが1単位増加したときに、yがどれだけ変化するか」を示しています。
たとえば、「広告費」と「売上」の関係をモデル化する場合、回帰係数が10なら、広告費を1万円増やすと売上が10万円伸びる、という具合です。
何が違うのか?
ここが最も大事なポイントです!
| 項目 | 相関係数 | 回帰係数 |
|---|---|---|
| 目的 | 関係の強さを測る | 予測・影響度を測る |
| 単位 | 単位なし(−1〜1) | 単位あり(xとyの単位に依存) |
| 対称性 | 対称的(r(X,Y) = r(Y,X)) | 非対称的(回帰はX→Y) |
つまり、相関係数は「仲の良さ」を測る指標、回帰係数は「どれくらいの影響力があるか」を表す指標です。
機械学習との関係は?
機械学習では、回帰分析(regression)がモデル構築の中心になります。とくに線形回帰(linear regression)モデルは、もっとも基礎的なアルゴリズムの1つです。
ここで使われるのが回帰係数。これを使って、入力(特徴量)から出力(目的変数)を予測します。
一方、相関係数は前処理の段階でよく使われます。特徴量同士の相関が強すぎると、「多重共線性(multicollinearity)」という問題が起こり、モデルの精度が落ちる可能性があります。
3.4 微分・積分の基礎
AIの学習は「少しずつ良くしていく」作業の連続です。ここで使うのが微分・積分の考え方です。
微分とは?
ある関数の「傾き」を求める操作です。たとえば、
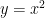

これは「xが1増えると、yはどれくらい変わるか」を表します。
AIでは、損失関数の最小化のために傾きを使って学習するため、この概念はとても重要です。
積分とは?
微分の逆で、関数の下の「面積」を求めます。AIではあまり直接使いませんが、確率密度関数の理解などに使われます。
3.5 線形代数
人AIや機械学習では、データを効率よく扱うために「ベクトル」や「行列」といった線形代数の概念が重要になります。
ベクトルとは、複数の数値を1つにまとめた「数値の並び」で、例えば画像のピクセル値やユーザーの属性などを1つのベクトルとして表現します。
一方、行列は複数のベクトルを並べたもので、複数のデータを一括処理するために使われます。モデルでは「行列×ベクトル」の形で入力に重みをかけて出力を得る、という処理が基本になります。これは線形回帰やニューラルネットワークなど多くの手法の土台です。さらに、行列演算を使えば並列処理や高速な学習が可能となり、大量データを扱うAIにとって不可欠です。
線形代数の知識は、予測モデルの理解、パラメータ最適化、次元削減などあらゆる場面で活用されます。
ベクトルとは?
ベクトルは、向きと大きさを持った量です。たとえば、2次元のベクトル 
- ベクトル同士の足し算やスカラー倍(数をかける)も重要です。
行列とは?
行列は、数をタテ・ヨコに並べたもので、複数のベクトルをまとめた形です。
⎡ 1 2 ⎤
⎣ 3 4 ⎦これは、2行2列の行列です。行列の掛け算は、データの変換(線形変換)に使われます。
AIでの活用例
- ニューラルネットワークでは、重み行列と入力ベクトルをかけることで次の層への出力を計算します。
- 画像は「ピクセル値の行列」なので、画像処理でも行列は欠かせません。
コサイン類似度とは?
コサイン類似度は、2つのベクトルがどれだけ同じ方向を向いているかを数値で表す指標です。
ベクトルの「向きの類似性」に注目するため、たとえ大きさが違っても方向が似ていれば高いスコアになります。
たとえば、ユーザーAとユーザーBがまったく同じジャンルの商品を買っていても、購入回数が違うだけなら傾向は似ていますよね?
そんな時に使えるのがこの指標です。
数式による定義
2つのベクトル $\vec{A}$ と $\vec{B}$ のコサイン類似度は次のように定義されます。

日本語で読むと、
コサイン類似度 =(ベクトルの内積)÷(それぞれの大きさの積)
用語の補足:
:内積(dot product)。ベクトルAとBの対応する要素を掛けてすべて足した値です。
:ベクトルの大きさ(ノルム)。
例えばのとき、

AIでの活用例
- 自然言語処理(NLP)
単語や文をベクトル化し、似た文を探す際にコサイン類似度を用います。
例:「猫」と「犬」は近いベクトルになりやすく、「猫」と「パソコン」は離れる。 - 推薦システム
ユーザーの行動(例:購入履歴)をベクトルに変換し、似たユーザーや商品を見つける。 - 画像認識
特徴量ベクトルの比較により、似ている画像を検索することができます。
行列演算との関係
ベクトルが複数あれば、それらを行列としてまとめ、行列同士の掛け算でコサイン類似度を一括計算できます。
例えば、ユーザーが100人いたら、100本のベクトルを1つの行列にして、他の行列と掛けることで類似度を一度に求めることができます。
まとめ:AIは“数学”で動いている
この章では、人工知能を支える「数学のエッセンス」を学びました。
ポイントは、深い理論よりも、どんな場面で使われるのかを理解することです。
| 分野 | 使われる場面 |
|---|---|
| 線形代数 | ニューラルネットワーク、画像処理など |
| 確率・統計 | 分類、推論、ベイズなど |
| 微分 | 最適化、誤差の調整 |
数学が苦手でも心配いりません。
「どんな問題に、どの数式が使われているのか」を少しずつ結びつけていけば、自然と理解できるようになります。
次章では、「ディープラーニングの仕組み」を学びます。