
【超入門】Hugging Faceで始めるAI開発!新人エンジニアが最初に触るべきTransformerの基礎と実践
 山崎講師
山崎講師こんにちは。ゆうせいです。
最近、どこを見ても「AI」や「AIモデル」という言葉が飛び交っていますね。新人エンジニアのみなさん、正直なところ「自分もAIを使ってみたいけれど、数学も難しそうだし、環境構築で挫折しそう」と感じていませんか?
その気持ち、痛いほどわかります!でも、安心してください。現代には「Hugging Face(ハギングフェイス)」という、エンジニアにとっての強力な武器があります。これを使えば、まるでライブラリをインポートするような手軽さで、世界最高峰のAIモデルを自分の手元で動かせるのです。
今日は、AI開発の民主化を象徴するこのツールを使って、実際にTransformerモデルを動かすところまで一緒にやってみましょう。難しそうな数式は一切なしで、概念から実践までわかりやすく案内しますよ!
AI界の「GitHub」?Hugging Faceとは何か
まず最初に、Hugging Faceとは一体何者なのか、ここから紐解いていきましょう。
一言で表すなら、Hugging FaceはAIモデルにおける「GitHub」のような存在です。世界中の研究者や企業が開発したAIモデルが、ここに集約され、公開されています。開発者はそこから好きなモデルを選んでダウンロードし、自分のプログラムに組み込むことができるのです。
例えるなら、巨大な「AIのコンビニ」を想像してください。「文章を要約したい」「画像を識別したい」「音声を文字にしたい」といった要望があれば、棚から目的に合ったモデルを選んでカゴに入れるだけ。ゼロから自分でAIを育てる必要はありません。
このプラットフォームのおかげで、私たちエンジニアは巨人の肩に乗り、最先端の技術をすぐにアプリやサービスに応用できるようになったのです。
Transformer:AIに「文脈」を理解させる革命児
Hugging Faceで扱われるモデルの多くは「Transformer(トランスフォーマー)」という仕組みをベースにしています。映画のタイトルではありませんよ!
これは2017年にGoogleが発表した、深層学習(ディープラーニング)のアーキテクチャのひとつです。Transformerが登場する前は、AIは長い文章を読むのが苦手でした。文章の最初の方にある単語を、最後の方まで覚えておくことが難しかったのです。
しかし、Transformerは「Attention(アテンション)機構」という画期的な仕組みを持っています。これは、文章の中の「どの単語」が「どの単語」と強く関連しているか、文脈全体を見渡して重要度を判断する能力です。
高校の現代文の授業を思い出してください。「それ」や「あれ」という指示語が何を指しているか、前後の文脈から判断しましたよね?Transformerはまさにそれを、計算によって行っているのです。
ここで、その計算のイメージを少しだけ数式風に表現してみましょう。あくまで概念的なイメージですが、AIの中では次のような処理が行われています。
単語の重要度 

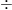
このように、掛け算や割り算を膨大な回数繰り返すことで、AIは「この単語には注目すべきだ!」と判断しているのです。
Hugging Faceを使うメリットとデメリット
便利な道具には、必ず良い面と注意すべき面があります。実際に使い始める前に、ここをしっかり押さえておきましょう。
メリット
- 爆速で実装できる数行のコードを書くだけで、翻訳や感情分析などの機能が動きます。「車輪の再発明」をする必要がありません。
- 最新モデルがすぐ試せる論文発表されたばかりの最新モデルが、数日後にはアップロードされていることも珍しくありません。常に最先端に触れられます。
- 日本語モデルも豊富英語だけでなく、優秀な日本語モデルも多数公開されているため、日本のビジネスシーンでも即戦力になります。
デメリット
- マシンスペックが必要高性能なモデルほどサイズが大きく、計算量も膨大です。手元のノートPCでは動作が遅かったり、メモリ不足で動かなかったりすることがあります。
- ライブラリの依存関係が複雑Pythonのバージョンや、関連するライブラリ(PyTorchやTensorFlowなど)のバージョン合わせに苦労することがあります。
- モデルの中身がブラックボックスになりがち簡単に動かせる反面、中で何が起きているかを理解せずになんとなく使ってしまいがちです。エラーが起きたときの対処が難しくなる可能性があります。
実践!感情分析AIを動かしてみよう
さあ、いよいよ手を動かす時間です!
今回は、入力した文章が「ポジティブ」か「ネガティブ」かを判定する「感情分析」をやってみましょう。
前提として、Pythonがインストールされている環境で、以下のコマンドを使ってライブラリをインストールしておいてください。
pip install transformers torch準備ができたら、以下のPythonコードを書いて実行してみてください。
from transformers import pipeline
# 感情分析のパイプラインを作成
# 初回実行時はモデルのダウンロードが行われます
classifier = pipeline("sentiment-analysis")
# AIに判定させたい文章
text = "Hugging Faceを使った開発はとても楽しい!"
# 判定を実行
result = classifier(text)
# 結果を表示
print(f"文章: {text}")
print(f"判定結果: {result}")
いかがですか?たったこれだけのコードで、AIモデルをダウンロードし、読み込み、判定まで行ってくれるのです。
もし英語のモデルがデフォルトで選ばれてしまった場合、日本語を入れると精度が出ないことがあります。その場合は、引数で日本語対応のモデル名を指定してあげるだけで解決します。ぜひ、いろいろなモデルを差し替えて遊んでみてください!
次のステップへ進むために
今日はHugging FaceとTransformerの入り口に立ちました。自分で動かしてみると「意外と簡単だ!」と思えたのではないでしょうか?その「できた!」という感覚こそが、エンジニアとして成長するための何よりの燃料です。
これからさらに学びを深めるための指針をいくつか示しておきます。
- ファインチューニングに挑戦する既存のモデルを、自分独自のデータで再学習させて、特定のタスクに特化させる技術です。これができると、実務での価値がグッと上がります。
- 異なるタスクを試す今回は感情分析でしたが、文章要約、質問応答、画像生成など、パイプラインを変えるだけで様々なことができます。公式ドキュメントを眺めてみましょう。
- モデルの仕組みを深掘りする動かせるようになったら、次は「なぜ動くのか」を学びましょう。Attention機構の数式や論文を読んでみると、より深い理解が得られます。
AIの世界は日進月歩ですが、恐れることはありません。今日あなたが踏み出した一歩は、未来への大きな飛躍につながっています。さあ、次はどんなモデルを動かしてみますか?
あなたのエンジニアライフが、ここからさらに面白くなることを願っています!
【脱・初心者】AIを自分色に染める?ファインチューニングで「賢い」モデルを作る方法
前回の記事では、Hugging Faceにある既存のモデルをそのまま動かしてみましたね。自分の手元でAIが動いたときの感動、まだ覚えていますか?
でも、少し使っているとこんな不満が出てくるかもしれません。「もっと自分の業界の専門用語を理解してほしい」「うちの会社の社風に合った文章を書いてほしい」と。
そう、借りてきたAIはあくまで「一般的な優等生」です。特定の専門分野については、まだ素人なんですね。そこで今回は、AI開発の次のステップとして「ファインチューニング(Fine-tuning)」という技術についてお話しします。
これをマスターすれば、あなたはただAIを使うだけでなく、AIを「育てる」エンジニアになれるのです。今日はその仕組みと、気をつけるべきポイントを一緒に学んでいきましょう。
ファインチューニングとは?AIへの「新人研修」
ファインチューニングを一言で言うと、AIに対する「専門教育」や「新人研修」です。
Hugging Faceにあるモデル(事前学習済みモデル)は、インターネット上の膨大なテキストを読んで、言葉の文法や一般的な知識を身につけています。これは、大学を卒業したばかりの優秀な新入社員のようなものです。基礎能力は高いですが、あなたの会社の業務ルールや専門用語はまだ知りません。
そこで、あなたの手元にある特定のデータ(業務日報や、過去の問い合わせ履歴など)を使って、もう一度少しだけ勉強させるのです。これがファインチューニングです。
基礎がすでに出来上がっているため、ゼロから教える必要はありません。短期間の研修で、即戦力のスペシャリストに生まれ変わらせることができるのです。
学習の仕組みを高校数学レベルで理解する
では、AIはどのようにして学習し、賢くなっていくのでしょうか?
AIの中には、無数の「重み(パラメータ)」という数字のつまみがあります。学習とは、このつまみを微調整して、正解に近づける作業のことです。
少しイメージしやすいように、学習の更新プロセスを簡単な式で表してみましょう。AIが答え合わせをして、間違っていたときにどれくらい反省して修正するか、という式です。
新しい知識 
ここで重要なのが「学習率」という言葉です。これは「一度にどれくらい修正するか」を決める値です。
もし学習率が大きすぎると、一回の失敗で極端に考えを変えてしまい、かえって正解から遠ざかってしまうことがあります。逆に小さすぎると、いつまでたっても成長しません。エンジニアは、この値を慎重に調整して、AIを適切な方向へ導いてあげる必要があるのです。
専門用語:これだけは覚えておこう
エンジニア同士で会話するときに困らないよう、いくつかの重要単語を解説しておきます。
- エポック(Epoch)用意した教科書(データセット)を、最初から最後まで何回繰り返して勉強したかを表す単位です。「3エポック回す」と言えば、同じ問題集を3周させたという意味になります。繰り返すほど記憶は定着しますが、やりすぎも禁物です。
- 損失関数(Loss Function)AIの答えが、正解とどれくらいズレているかを計算する数式のことです。学習のゴールは、この損失(Loss)を限りなく
に近づけることです。
- 過学習(Overfitting)これは勉強のしすぎで起こる問題です。練習問題の答えを丸暗記してしまい、少し違う問題が出されると全く答えられなくなる状態を指します。「応用が効かないガリ勉」になってしまうようなものです。
ファインチューニングのメリットとデメリット
夢のような技術に見えますが、やはり注意点もあります。
メリット
- 少ないデータで高性能なAIが作れるゼロから学習させるには何億ものデータが必要ですが、ファインチューニングなら数百〜数千件のデータでも十分な効果が出ることがあります。
- 学習時間が短い基礎ができているので、数時間から数日で学習が完了します。コストパフォーマンスが非常に高い手法です。
デメリット
- 破滅的忘却(Catastrophic Forgetting)なんて恐ろしい名前でしょう!これは、新しいことを詰め込みすぎた結果、元々知っていた一般的な知識を忘れてしまう現象です。専門バカになりすぎて、普通の会話ができなくなるリスクがあります。
- データの質が命偏ったデータや間違ったデータを読ませると、AIはその偏見まで学習してしまいます。データの掃除(前処理)が非常に重要になります。
実践!コードのイメージを掴む
実際にコードを書く場合、Hugging Faceの Trainer という機能を使うと非常に便利です。雰囲気だけ掴んでみましょう。
from transformers import Trainer, TrainingArguments
# 学習の設定(勉強のスケジュール)
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3, # 教科書を3周する
learning_rate=2e-5, # 学習率は慎重に小さく
)
# 教師役のトレーナーを用意
trainer = Trainer(
model=model, # 鍛えたいモデル
args=training_args, # 設定
train_dataset=dataset, # 教科書データ
)
# いざ、特訓開始!
trainer.train()
この trainer.train() を実行すると、パソコン(またはGPUサーバー)が唸りを上げて計算を始めます。画面に表示される Loss の数字が徐々に減っていく様子を見るのは、育ての親として何とも言えない快感がありますよ!
今後の学習の指針
ここまでくれば、あなたはもう立派なAIエンジニアの卵です。ファインチューニングを理解したことで、世界中のモデルを「素材」として扱えるようになりました。
次は、学習に必要な「データセット」に目を向けてみましょう。
世の中にはどんなデータが公開されているのか、あるいは自分でデータを作るにはどうすればいいのか。「データセットの構造とHugging Face Datasetsライブラリの使い方」を学ぶのが、確実なステップアップになります。
自分だけの最強AIを作る旅、楽しんでいきましょう!
【良質なデータこそがAIの燃料】Hugging Face Datasetsで学ぶ、学習データの準備と「分割」の極意
前回は、AIを自分好みに育てる「ファインチューニング」についてお話ししました。AIを賢くするための教育係としての役割、イメージできましたか?
さて、今日はその教育に欠かせない「教科書」、つまり「データセット」についてお話しします。
AI業界には「Garbage In, Garbage Out(ゴミを入れれば、ゴミが出てくる)」という有名な格言があります。どんなに優秀なAIモデル(天才的な脳)を持っていても、教えるデータ(教科書)が間違っていれば、AIは間違ったことしか覚えません。
今回は、Hugging Faceが提供する強力なツール「Datasets」ライブラリを使って、AIにとっての「良質な食事」をどのように用意し、どう与えればよいのか。その作法を一緒に学んでいきましょう。
Hugging Face Datasetsとは?巨大なデータ図書館
まず、「Hugging Face Datasets」というライブラリについて紹介します。これは、世界中の研究者や企業が作った高品質なデータセットを、たった1行のコードでダウンロードできる「巨大な図書館」のようなものです。
文章分類、翻訳、要約、質問応答など、あらゆるタスクに対応したデータが無料で公開されています。
自分でゼロからデータを作るのは大変です。例えば、感情分析をするために「このツイートはポジティブ」「これはネガティブ」と数千件もラベル付けをする作業を想像してください。気が遠くなりますよね?
Datasetsライブラリを使えば、先人たちが苦労して作ったデータを借りて、すぐに学習を始めることができるのです。
データの黄金比?「学習用」と「テスト用」を分ける理由
データを用意するときに、初心者がやりがちなミスがあります。それは「持っているデータをすべて学習に使ってしまうこと」です。
なぜこれがいけないのでしょうか?高校の定期テストを思い出してください。
先生が「授業で使ったプリントの問題」をそのままテストに出したらどうなりますか?生徒は答えを丸暗記して満点を取るかもしれません。でも、それは本当に「実力がついた」と言えるでしょうか?数字を変えたり、少しひねった問題が出たりした瞬間に解けなくなるなら、意味がありません。
AIも同じです。本当に賢くなったのか、それとも答えを丸暗記しただけなのかを確かめるために、データを必ず2つ(厳密には3つ)に分ける必要があります。
- 学習データ(Train)
AIに勉強させるための教科書。通常、全体の80%程度を使います。 - テストデータ(Test)
学習には一切使わず、最後に実力を測るための入学試験。残りの20%程度を使います。
これを数式風に表現すると、データ全体は次のように構成されます。
全データ 
この「分割(Split)」を厳密に行うことが、信頼できるAIを作るための第一歩です。
実践!データセットを読み込んで中身を見てみよう
では、実際にPythonを使って、Hugging Faceからデータを借りてきてみましょう。今回は、感情分析によく使われるデータセットを例にします。
事前に以下のコマンドでライブラリを入れておいてください。
pip install datasets準備ができたら、以下のコードを書いてみましょう。
from datasets import load_dataset
# データセットをロード(ダウンロード)
# ここでは例として感情分析のデータセットを指定します
dataset = load_dataset("emotion")
# データの中身を確認
print(dataset)
実行すると、以下のような構造が表示されるはずです(内容はイメージです)。
DatasetDict({
train: Dataset({ features: ['text', 'label'], num_rows: 16000 }),
validation: Dataset({ features: ['text', 'label'], num_rows: 2000 }),
test: Dataset({ features: ['text', 'label'], num_rows: 2000 })
})
ここで注目してほしいのが features (特徴)と num_rows (行数)です。text がAIに読ませる文章、 label がその正解(喜び、悲しみ、など)です。そして、最初から train (学習用)や test (テスト用)にきれいに分かれていますね。
Hugging Face Datasetsを使えば、自分で分割する手間さえ省けることが多いのです。
Datasetsライブラリを使うメリットとデメリット
メリット
- データの前処理が楽になる
データセットによっては、すでに扱いやすい形式に整形されています。面倒なCSVファイルの読み込みや、文字化けの処理に悩まされる時間が激減します。 - メモリ効率が良い
巨大なデータセット(数ギガバイト以上)を扱う場合でも、メモリをパンクさせずに効率よく読み込む仕組み(Apache Arrowなど)が裏で動いています。 - 再現性が高い
「〇〇というデータセットを使いました」と言えば、世界中の誰でも同じ条件で実験を再現できます。
デメリット
- 著作権やライセンスの確認が必要
公開されているからといって、商用利用が自由とは限りません。データセットごとにライセンス(利用規約)が異なるため、必ず確認する癖をつけましょう。 - 中身にバイアスがある可能性
ネット上のデータを集めたものが多いため、偏見や不適切な表現が含まれていることがあります。鵜呑みにせず、中身をチラッと確認することが大切です。
今後の学習の指針
今日は、AIの燃料となる「データ」の扱い方について学びました。Hugging Face Datasetsを使えば、良質なデータにすぐにアクセスできることがわかりましたね。
さて、データを読み込み、AIを学習させたとしましょう。でも、そのAIが「どれくらい賢くなったのか」をどうやって数値化すればいいのでしょうか?
「正解率80%」と言われたら凄そうですが、もしデータの90%が「異常なし」という正解だったら、AIが何も考えずにすべて「異常なし」と答えても正解率は90%になってしまいます。これでは意味がありませんよね。
次回は、AIの実力を正しく測るための「評価指標(メトリクス)」について解説します。Accuracy(正解率)だけで満足してはいけない、奥深い世界へ案内しますよ。
それでは、またお会いしましょう!
【AIの成績表】「正解率」だけで満足してない?PrecisionとRecallでモデルの本当の実力を測る
前回は、AIにとっての食事である「データセット」の準備方法についてお話ししました。良質なデータを与えれば、AIはすくすくと育ちます。
でも、育てたAIが本当に「賢く」なったのか、どうやって判断しますか?
「テストデータの正解率が90%でした!」と言われると、なんとなく「すごい!優秀だ!」と思ってしまいますよね。
実は、ここには大きな落とし穴があります。もし、そのテスト問題の90%が「答えはA」で、AIが何も考えずに全て「A」と答えていたとしたらどうでしょう?それでも正解率は90%になってしまいます。これでは、実戦では全く役に立ちません。
今日は、そんな数字のトリックに騙されないために、AIの本当の実力を測る「評価指標(メトリクス)」について解説します。エンジニアとして、AIに正しい「通信簿」をつけてあげましょう。
「正解率(Accuracy)」の限界を知る
まず、最も一般的な指標である「正解率」について見てみましょう。これはシンプルに、全問のうち何問正解したかを表すものです。
正解率
これは分かりやすいですが、先ほどお話ししたように「データのバランスが悪いとき」に信用できなくなります。
例えば、工場の部品検査AIを作るとします。1000個の部品のうち、不良品はわずか10個(1%)しかありません。
もしAIが「全て正常です」と答え続けるポンコツAIだったとしても、990個は正解するので、正解率は99%になります。
でも、私たちが一番見つけたいのは、その1%の不良品ですよね?このポンコツAIは、一番重要な不良品を1つも見つけていないのに、成績優秀に見えてしまうのです。
そこで登場するのが、「適合率(Precision)」と「再現率(Recall)」という2つの指標です。
適合率(Precision):AIの「自信」は信用できるか?
適合率は、AIが「これはポジティブだ!」(または「これは不良品だ!」)と予測したもののうち、本当にそうだった割合です。
適合率
この数値が高いということは、AIの「自信」が信用できるということです。
例えば、スパムメールフィルターを想像してください。
AIが「これはスパムだ!」と判定してゴミ箱に入れたメールが、実は重要な取引先のメールだったら大問題ですよね。
こういう「誤検知(ぬか喜びや冤罪)」を絶対に避けたいときは、この適合率を重視します。
再現率(Recall):取りこぼしはないか?
再現率は、本来見つけるべき正解のうち、AIがどれだけ見つけ出せたかの割合です。
再現率
この数値が高いということは、「見落とし」が少ないということです。
先ほどの工場の不良品検知や、がん検診のAIなどを想像してください。
「怪しいものはとりあえず検査に回す」という方針なら、多少の間違い(誤検知)があってもいいから、絶対に不良品や病気を見逃したくありませんよね。
こういう「見落とし厳禁」のケースでは、再現率を重視します。
どっちも大事!そんな時の「F1スコア」
「適合率も大事だし、再現率も大事。どっちを見ればいいの?」と迷ったときは、「F1スコア」という指標を使います。これは、適合率と再現率のバランスを取った平均点のようなものです。
一般的に、コンペティションや論文では、このF1スコアを使ってモデルの優秀さを競うことが多いです。
実践!Hugging Faceで評価指標を計算する
では、実際にコードを書いてみましょう。
Hugging Faceには evaluate という便利なライブラリがあり、複雑な計算式を自分で書く必要はありません。
事前に以下のコマンドでライブラリを入れておいてください。
pip install evaluate scikit-learn学習用のコード(Trainer)の中に、以下のような関数を組み込みます。
import evaluate
import numpy as np
# 評価指標の読み込み
accuracy = evaluate.load("accuracy")
f1 = evaluate.load("f1")
def compute_metrics(eval_pred):
# AIが出した予測結果と、正解ラベルを取り出す
predictions, labels = eval_pred
# 確率(0.2, 0.8など)から、最も高いクラス(0か1か)に変換
predictions = np.argmax(predictions, axis=1)
# 正解率を計算
acc = accuracy.compute(predictions=predictions, references=labels)
# F1スコアを計算
f1_score = f1.compute(predictions=predictions, references=labels, average="weighted")
# 結果をまとめて返す
return {"accuracy": acc["accuracy"], "f1": f1_score["f1"]}この compute_metrics 関数を Trainer に渡してあげるだけで、学習中に自動で「今のAIの成績」を計算して表示してくれるようになります。
メリットとデメリット
評価指標を導入することの良し悪しを整理しましょう。
メリット
- モデルの「性格」がわかる「慎重なAI(Precisionが高い)」なのか、「積極的なAI(Recallが高い)」なのかが数字でわかります。
- 目的に合ったチューニングができるサービスの性質に合わせて、重視する指標を変えることで、より実用的なAIを作れます。
デメリット
- トレードオフがあるあちらを立てればこちらが立たず。適合率を上げようとすると再現率が下がることが多く、そのバランス調整(閾値の調整など)は泥臭い作業になりがちです。
- 解釈が難しい「F1スコアが0.8です」と言われても、それがビジネス的にどれくらいの価値があるのか、直感的に説明するのが難しい場合があります。
今後の学習の指針
今回は、AIの「本当の実力」を測る方法を学びました。これであなたは、ただ動くだけのAIではなく、「信頼できるAI」を作れるエンジニアになりました。
さて、ここまでで「モデルを動かす」「学習させる」「評価する」という一連の流れをマスターしました。手元には、あなただけの素晴らしいモデルが完成しているはずです。
でも、そのモデルをあなたのPCの中に閉じ込めておくのはもったいないと思いませんか?
次回は、いよいよ最終段階。あなたの作った自慢のAIモデルを、世界中の人々に使ってもらうために、「Hugging Face Hubへのモデルのアップロードと、デモアプリの公開(Spaces)」について解説します。
自分の作品が世界に公開される瞬間は、何度味わってもドキドキしますよ。それでは、また次回お会いしましょう!
【完結編】自作AIを世界へ公開!Hugging Face HubへのアップロードとSpacesでのデモ作成
これまで、モデルを選び、自分のデータで鍛え(ファインチューニング)、その実力を評価してきました。あなたの手元には今、世界に一つだけの、あなた好みに育ったAIモデルがあります。
でも、ちょっと待ってください。その素晴らしいモデル、あなたのパソコンの中に閉じ込めたままにしていませんか?
それはまるで、一生懸命描いた絵を誰にも見せずに押入れにしまっているようなものです。もったいないですよね!
このシリーズの最終回となる今回は、あなたの作ったAIを「Hugging Face Hub」にアップロードして保存し、さらに「Spaces」という機能を使って、誰でもブラウザから使えるアプリとして公開する方法を解説します。
これができれば、友人に「俺、AI作ったんだ」とURLを送るだけで自慢できるようになりますよ。さあ、最後の仕上げといきましょう!
Hugging Face Hub:AIのための「展示場」
まず、モデルを保存する場所についてです。
シリーズの最初で、Hugging Faceは「AIのコンビニ」や「図書館」だと説明しました。今度は、あなたがそこに「商品」を並べる番です。
あなたが学習させたモデル(重みデータ)や、設定ファイル(Config)をHugging Faceのクラウド上にアップロードすることを「Hubへのプッシュ」と呼びます。
これを行うと、あなたのモデルに専用のページが作られます。これには大きな意味があります。
- どこからでも呼び出せる一度アップロードすれば、会社のマシンでも、家のノートPCでも、たった1行のコードであなたのモデルを呼び出せるようになります。
- ポートフォリオになる就職活動や転職活動で「私はAI開発ができます」と言うよりも、「これが私が開発したモデルのURLです」と見せる方が、100倍の説得力を持ちます。
イメージとしては、モデルの共有は以下のような流れになります。
あなたのPC 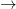
Spaces:動く「デモアプリ」を爆速で作る
モデルを公開するだけでも凄いことですが、エンジニアではない人(友人や家族)に「これ使ってみて」と言って、Pythonのコードを渡しても困られてしまいますよね?
そこで登場するのが「Hugging Face Spaces」です。
これは、あなたのモデルを使ったWebアプリ(デモ画面)を、サーバーの知識ゼロで公開できるサービスです。
通常、Webアプリを作るにはHTMLやCSS、JavaScript、そしてサーバーの構築など、膨大な知識が必要です。しかし、Spacesでは「Gradio(グラディオ)」や「Streamlit(ストリームリット)」というPythonライブラリを使うことで、Pythonコードだけで画面まで作れてしまうのです。
実践!モデルをアップロードしてアプリにする
では、魔法のような手順をコードで見てみましょう。
1. モデルをHubにアップロードする
まずは、認証が必要です。ターミナルで以下のコマンドを打ち込み、Hugging Faceのサイトで取得した「Access Token」を入力してログインします。
huggingface-cli loginその後、Pythonコードで以下のように記述します。
from transformers import AutoModelForSequenceClassification, AutoTokenizer
# あなたが学習させたモデルとトークナイザを読み込む
model_path = "./my_finetuned_model" # 保存してあるフォルダ
model = AutoModelForSequenceClassification.from_pretrained(model_path)
tokenizer = AutoTokenizer.from_pretrained(model_path)
# Hubにアップロード(プッシュ)する
# "my-first-ai" の部分は、あなたの好きな名前に変えてください
model.push_to_hub("my-first-ai")
tokenizer.push_to_hub("my-first-ai")
たったこれだけで、あなたのモデルがインターネット上に公開されました!
2. Gradioで画面を作る
次に、このモデルを使ったアプリの画面を作ります。これには Gradio というライブラリが最強です。
import gradio as gr
from transformers import pipeline
# Hubに上げた自分のモデルを指定してパイプラインを作る
# "username"はあなたのHugging Faceのユーザー名です
classifier = pipeline("sentiment-analysis", model="username/my-first-ai")
# アプリの動きを定義する関数
def ai_func(text):
result = classifier(text)
# 結果からラベルとスコアを返す
return f"判定: {result[0]['label']}, スコア: {result[0]['score']}"
# 画面を作る
demo = gr.Interface(
fn=ai_func, # 動かす関数
inputs="text", # 入力はテキストボックス
outputs="text", # 出力もテキスト
title="私の感情分析AI", # タイトル
description="文章を入れると、ポジティブかネガティブか判定します!"
)
# アプリを起動
demo.launch()
このコードをSpaces上のファイル(app.py)として保存するだけで、入力ボックスと送信ボタンがついたWebサイトが自動的に生成されます。まるで魔法でしょう?
メリットとデメリット
公開することの意義を整理しておきましょう。
メリット
- フィードバックがもらえる自分一人では気づかなかったバグや改善点を、他のユーザーから教えてもらえることがあります。
- サーバー代が(基本)無料小規模なデモアプリであれば、Hugging Faceが提供する無料のCPU環境で動かせます。自分でAWSなどを契約する必要がありません。
- モチベーションが爆上がりする自分の作ったものが動いて、誰かに使ってもらえる。この快感こそがエンジニアリングの醍醐味です。
デメリット
- 機密情報に注意社外秘のデータを使って学習させたモデルや、パスワードなどの認証情報をうっかり公開しないように細心の注意が必要です。公開設定を「Private」にすることも可能です。
- 重いモデルは遅い無料の環境ではCPUしか使えないことが多く、大規模なモデルだと判定に時間がかかる場合があります。サクサク動かすには有料のGPU契約が必要になることがあります。
【最先端】話題の生成AIを操れ!大規模言語モデル(LLM)とプロンプトエンジニアリング入門
これまでの連載で、私たちはAIに「この文章はポジティブ?ネガティブ?」と判定させるモデルを作ってきました。これは、言わばAIに「審判」の役割をさせる技術でしたね。
でも、今のAIブームの中心にいるのは、ChatGPTのように「人間のような文章を自分で作り出す」AIです。これを技術用語で「生成AI(Generative AI)」や「大規模言語モデル(LLM)」と呼びます。
「判定」から「創造」へ。今日は、エンジニアとしてのステップを一段飛ばして、この魔法のような技術がどう動いているのか、そしてそれをどう操ればいいのかを体験してみましょう。
実は、Hugging Faceを使えば、あのChatGPTの親戚のようなモデルも、自分の手元で動かすことができるのです。ワクワクしてきませんか?
LLMの正体:超巨大な「次単語予測ゲーム」
まず、大規模言語モデル(LLM)とは一体何者なのでしょうか?
難しそうな名前ですが、その本質は非常にシンプルです。彼らは、ひたすら「次の言葉当てゲーム」をしているだけなのです。
みなさんも会話の中で、相手が言いかけた言葉を予測することがありますよね?
「明日の天気は、晴れるといい...」と言われたら、次は「ね」や「な」が来ると予想できます。「サツマイモ」とは続きませんよね。
LLMは、インターネット上の膨大なテキストを読み込み、この「次に来る言葉の確率」を学習しています。
これを少し数式風にイメージしてみましょう。AIは常に、これまでの文脈をもとに、次に来る単語の確率を計算しています。
次の単語の確率 
例えば、「昔々、あるところに」という入力があったら、「おじいさんが(80%)」「お城が(10%)」「宇宙人が(0.01%)」のように計算し、サイコロを振って次の言葉を選んでいるのです。
これを猛烈なスピードで繰り返すことで、まるで意志を持って喋っているかのような流暢な文章が生まれます。
魔法の杖:プロンプトエンジニアリング
LLMは非常に賢いですが、指示の出し方一つで答えがガラリと変わります。この「指示出しの技術」をプロンプトエンジニアリングと呼びます。
新人エンジニアのみなさんに、ぜひ覚えておいてほしいテクニックが2つあります。
1. ゼロショット(Zero-shot)
これは、例を与えずにいきなり質問する方法です。
「空が青い理由を説明して」
最近のモデルは賢いので、これでも答えられますが、複雑なタスクだと失敗することがあります。
2. フューショット(Few-shot)
こちらは、いくつか「例」を見せてから質問する方法です。これが非常に強力です。
入力例:
赤色:情熱
青色:冷静
黄色:
このように例を並べてから「黄色:」と渡すと、AIは「あ、これは色から連想されるイメージを答えるゲームだな」と文脈を理解し、「注意」や「活発」といった答えを出しやすくなります。
AIに「空気を読ませる」ための技術、それがフューショットです。
実践!Hugging Faceで文章生成を行う
では、実際にPythonで文章生成モデルを動かしてみましょう。
今回は、日本語に対応した「rinna」という会社が公開しているモデル(GPT-2という種類のモデル)をお借りして動かしてみます。
事前に必要なライブラリをインストールしておいてください。
pip install transformers sentencepiece準備ができたら、以下のコードを実行してみましょう。
from transformers import pipeline, set_seed
# 生成結果が毎回変わるように乱数をセット
set_seed(42)
# 日本語の文章生成モデルをロード
# "rinna/japanese-gpt2-medium" というモデルを使います
generator = pipeline("text-generation", model="rinna/japanese-gpt2-medium")
# AIへの書き出し(プロンプト)を与える
prompt = "AIエンジニアになるためには、"
# 文章を生成!
# max_lengthは文章の長さ、num_return_sequencesは作る数です
result = generator(prompt, max_length=50, num_return_sequences=3)
# 結果を表示
for i, item in enumerate(result):
print(f"生成パターン{i+1}: {item['generated_text']}")
print("-" * 20)
いかがですか?
「AIエンジニアになるためには、プログラミングの勉強が必要です」といった真面目な答えから、少し突飛な答えまで、AIが続きを考えてくれたはずです。
prompt の中身を変えたり、max_length の数字を変えたりして、AIがどんな物語を紡ぎ出すか遊んでみてください。
生成AIのメリットとデメリット
流行りの技術ですが、エンジニアとして冷静にメリットとデメリットを把握しておく必要があります。
メリット
- 汎用性が高い一つのモデルで、翻訳、要約、作文、プログラミング補助など、あらゆるタスクをこなせます。
- クリエイティブな作業が得意アイデア出しや、小説の執筆補助など、正解のない問いに対して力を発揮します。
デメリット
- ハルシネーション(幻覚)これが最大の問題です。AIは「確率的にありそうな言葉」をつなげているだけなので、平気で嘘をつきます。「日本の首都は大阪です」と自信満々に答えることがあるのです。
- 計算コストが高い高性能なモデルほどサイズが巨大で、動かすのにお金や電気代がかかります。
今後の学習の指針
今日で、あなたは「判定するAI」と「生成するAI」の両方に触れました。もう初心者は卒業と言っても過言ではありません。
しかし、生成AIの世界は奥が深いです。今のままだと、AIは学習したことしか答えられません。例えば「今日のあなたの会社の売上」を聞いても、AIは知りようがありませんよね?
そこで次のステップとして学びたいのが、「RAG(ラグ)」という技術です。
これは、AIに社内のマニュアルや最新のニュース記事といった「外部の知識」を与えて、それをカンニングさせながら答えさせる技術です。これを使えば、「社内専用のChatGPT」を作ることができます。
興味があれば、「LangChain(ラングチェーン)」というライブラリについて調べてみてください。これがRAGを実現するための鍵となります。
AIとの対話は、まだ始まったばかりです。ぜひ、あなただけの相棒を育て上げてくださいね!
【嘘つきAIにさよなら】社内データで回答する最強AIを作る!RAGとLangChainの基礎
前回は、まるで人間のように文章を書く「生成AI(LLM)」を動かしてみましたね。AIが物語を紡ぎ出す様子に感動したのではないでしょうか?
しかし、しばらく使っていると、ある「弱点」に気づくはずです。
例えば、AIに「私の会社の就業規則について教えて」と聞いてみてください。当然、「知りません」と返されるか、あるいは適当な嘘(ハルシネーション)をつかれるでしょう。
これは当たり前ですよね。AIはインターネット上の一般常識は知っていますが、あなたの会社の内部情報や、昨日起きたばかりのニュースは学習していないからです。
そこで今回は、AIに「外部の知識」をカンニングさせて、正確な答えを導き出す技術「RAG(ラグ)」について解説します。これを使えば、あなたは「社内専用のChatGPT」を作れるようになりますよ!
RAGとは?AIに「カンニング」を許す技術
RAG(Retrieval-Augmented Generation:検索拡張生成)という言葉、なんだか強そうですが、やっていることは非常にシンプルです。
一言で言えば、「試験中に教科書を見てもいいよ(持ち込み可)」 というルールにする技術です。
これまでのAI(LLM)は、学習した知識だけを頼りに、記憶力だけで答えようとしていました。これを「クローズドブック(教科書なし)試験」と呼びます。知らないことを聞かれたら、記憶を捏造して答えてしまうのも無理はありません。
一方、RAGを使ったAIは次のような動きをします。
- 検索(Retrieval):あなたの質問に関連する資料(社内マニュアルやPDF)をデータベースから探してくる。
- 拡張(Augmented):見つけた資料を、質問文と一緒にAIに渡す。
- 生成(Generation):AIは渡された資料を読んで、それを元に回答を作成する。
これを数式風にイメージすると、AIへの命令(プロンプト)は次のようになります。
最終的な命令
「この資料を読んで、以下の質問に答えてください」という指示を、プログラムが自動で裏側で作ってくれるわけです。
なぜ「再学習(ファインチューニング)」じゃないの?
ここで鋭い新人エンジニアなら、こう思うかもしれません。
「知らないなら、前々回に習ったファインチューニングで、社内データを学習させればいいのでは?」と。
もちろんそれも一つの手ですが、実はRAGの方が圧倒的に有利なケースが多いのです。理由は2つあります。
- 更新が楽ファインチューニングは「記憶」させる作業なので、データが変わるたびに何時間もかけて再学習が必要です。一方、RAGは「本棚」に新しい資料を差し込むだけ。一瞬で最新情報に対応できます。
- 根拠がわかる「この回答は、社内規定マニュアルの3ページ目を参考にしました」と提示できるため、AIの嘘を見抜きやすくなります。
ベクトル検索:AIはどうやって資料を探す?
RAGを実現するための肝となるのが、「どうやって膨大な資料から、質問に関係する部分だけを瞬時に見つけ出すか」です。
ここで登場するのが「ベクトル化(Embedding)」という魔法です。
コンピュータは言葉の意味を直接理解できません。そこで、言葉を「数字の列(座標)」に変換します。これをベクトルと呼びます。
面白いことに、AIの世界では「意味が似ている言葉」は、この数字の空間の中で「距離が近く」なります。
例えば、「犬」という言葉の近くには「猫」があり、「スマホ」という言葉はずっと遠くにある、といった具合です。
検索の仕組みはこうです。
まず、あなたの質問を数字(ベクトル)に変換します。そして、あらかじめ保存しておいた資料の中で、その数字と「距離が最も近い」ものを探してくるのです。
類似度
この計算を行うことで、単語が完全に一致していなくても、意味が似ている資料を見つけ出すことができます。
LangChain:RAG開発の最強ツール
この「検索」と「生成」をつなぎ合わせる作業を、全部自分でコードを書くのは大変です。そこで、世界中のエンジニアが愛用しているのが「LangChain(ラングチェーン)」というライブラリです。
LangChainは、LLMアプリケーションを作るための「接着剤」のようなものです。PDFの読み込み、ベクトル化、検索、そしてAIへの受け渡しまで、一連の流れを驚くほど簡単に書くことができます。
雰囲気をつかむために、擬似的なコードを見てみましょう。
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
from langchain.document_loaders import TextLoader
from langchain.indexes import VectorstoreIndexCreator
# 1. 読ませたい社内データを指定する
loader = TextLoader("社内就業規則.txt")
# 2. データをベクトル化して、検索できる状態(インデックス)にする
# ここで裏側では、文章を数字に変換して保存しています
index = VectorstoreIndexCreator().from_loaders([loader])
# 3. AIに質問する
query = "有給休暇は何日もらえますか?"
result = index.query(query)
print(result)
たったこれだけで、AIは「社内就業規則.txt」の中身を読みに行き、「規定によると、入社半年後に10日付与されます」のように答えてくれるようになります。感動的ですよね!
RAGのメリットとデメリット
非常に強力なRAGですが、万能ではありません。
メリット
- 最新情報に対応できるニュースや株価など、刻一刻と変わる情報も、検索対象に入れるだけで対応可能です。
- コストが安いモデル自体を再学習させる必要がないため、高価なGPUを長時間回す必要がありません。
- セキュリティ管理がしやすい「部長にはこの資料を見せる」「新人には見せない」といったアクセス権の管理を、検索システム側で行うことができます。
デメリット
- 検索に失敗すると答えられない当たり前ですが、検索システムが的外れな資料を持ってきてしまったら、AIは正しい答えを出せません。「ゴミを入れてもゴミしか出ない」原則はここでも生きています。
- 処理に少し時間がかかる「検索する」→「読む」→「考える」というステップを踏むため、即答するチャットボットに比べると、回答が表示されるまで数秒のラグが発生することがあります。
今後の学習の指針
今回は、AIに「外部知識」という武器を持たせるRAGについて学びました。これであなたのAIは、ただのおしゃべり相手から、実務をこなす頼れるアシスタントへと進化しました。
さて、ここまでの学習で、AIは「判断(分類)」「創造(生成)」「調査(RAG)」ができるようになりました。
しかし、まだ足りないものがあります。それは「行動」です。
今のAIは、答えを画面に表示することしかできません。「会議の予約を入れておいて」と頼んでも、「予約する方法は以下の通りです」と答えるだけで、実際にカレンダーを操作してはくれませんよね?
次回は、AIが自ら考え、ツールを使いこなし、現実世界でアクションを起こす技術「AIエージェント(Agents)」について解説します。これができれば、本当の意味での自動化が実現します。
あなたのAIが、手足を持って動き出す未来。楽しみにしていてくださいね!
【自律型AI】AIが勝手に仕事する?「AIエージェント」でGoogle検索や計算を自動化しよう
前回の記事では、AIに社内のドキュメントをカンニングさせて賢くする「RAG」という技術を学びました。これで、AIはあなたの会社のルールも、専門的な知識も答えられるようになりましたね。
でも、人間の仕事って「知っていることを答える」だけでしょうか?
例えば、「来週の大阪の天気を調べて、もし雨なら社内のカレンダーに『雨天中止』と書き込んでおいて」と頼まれたとします。
今のAI(RAGを含む)は、「天気は調べられないし、カレンダーも触れません」と答えるか、あるいは「わかりました(何もしない)」という悲しい嘘をつくことしかできません。知識はあるけれど、手足がない状態だからです。
そこで今回は、AIに「手足(ツール)」を与え、自ら考え行動させる技術「AIエージェント」について解説します。これができるようになれば、AIはただの相談相手から、仕事を任せられる「同僚」へと進化しますよ!
AIエージェントとは?「脳」に「手足」がついた姿
AIエージェントを一言で表すと、「自分で道具を選んで使うAI」のことです。
これまでのチャットボット(LLM)は、あくまで「脳(考える機能)」だけでした。
エージェントは、この脳に「Google検索」や「電卓」、「カレンダー操作」といった「道具(ツール)」を持たせたものです。
そして一番すごいのは、「どの道具を、いつ、どう使うか」をAI自身が判断するという点です。
概念を簡単な式で表してみましょう。
AIエージェント
例えば、「
しかしエージェントなら、「これは計算の問題だ。じゃあ『電卓ツール』を使おう」と判断し、正確な計算結果を返してくれます。
どうやって動いている?「ReAct」の仕組み
AIが自分で考えるといっても、魔法ではありません。裏側では「ReAct(リアクト)」と呼ばれる思考プロセスがぐるぐると回っています。
これは Reasoning(推論)と Acting(行動)の略で、次のような独り言を繰り返しながら進んでいきます。
- 思考(Thought):「ユーザーが今の天気を知りたがっている。私は今の天気を知らない。だから『検索ツール』を使おう」
- 行動(Action):検索ツールを実行。「今日の東京の天気」
- 観察(Observation):ツールからの返事。「晴れ、気温25度です」
- 思考(Thought):「情報が揃った。ユーザーに答えよう」
- 回答(Final Answer):「今日の東京は晴れですよ!」
まるで人間が仕事をする時と同じですよね?
「わからないことは調べる」「計算が必要なら計算機を使う」。この当たり前のプロセスを、AI自身にやらせるのがエージェント技術なのです。
実践!LangChainでエージェントを作る
では、実際にPythonとLangChainを使って、簡単なエージェントを作ってみましょう。
今回は「計算」と「検索」の2つの道具を持たせてみます。
※注意:実際に動かすにはOpenAIのAPIキーや、Google検索のAPIキー(SerpApiなど)が必要になります。ここではコードのイメージを掴んでください。
from langchain.agents import load_tools, initialize_agent, AgentType
from langchain.llms import OpenAI
# 1. AIの脳みそを用意
llm = OpenAI(temperature=0)
# 2. AIに持たせる道具を用意
# "serpapi"はGoogle検索、"llm-math"は正確な計算機です
tools = load_tools(["serpapi", "llm-math"], llm=llm)
# 3. エージェントの誕生!
# agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION は
# 「道具の説明文を読んで、どれを使うか自分で決めるタイプ」です
agent = initialize_agent(
tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True # AIの独り言(思考プロセス)を表示する
)
# 4. 仕事を依頼する
# 検索と計算の両方が必要な、意地悪な質問をしてみましょう
agent.run("現在のドル円相場を調べて、100ドルが何円になるか計算して")これを実行すると、AIは次のように動き出します(verbose=Trueのおかげで思考が見えます)。
- 思考:「ドル円のレートを知る必要があるな。検索しよう。」
- 行動:Google検索(1ドル 何円)
- 観察:「1ドル = 150円です」という結果を取得。
- 思考:「レートはわかった。次は100倍する計算が必要だ。計算機を使おう。」
- 行動:計算機(
)
- 観察:「15000」という結果を取得。
- 回答:「現在のレートだと、100ドルは15,000円です。」
完璧な連携プレーです!
エージェントのメリットとデメリット
夢のような技術ですが、実務で使うには少しコツがいります。
メリット
- 複雑なタスクを自動化できる「検索して、要約して、メールで送る」といった、複数の手順が必要な仕事を丸投げできます。
- 正確性が上がる計算や最新情報の取得を専用のツールに任せることで、AIの弱点(ハルシネーションや計算ミス)を補えます。
デメリット
- 無限ループの恐怖AIが手順に迷ってしまい、「検索→失敗→検索→失敗…」と同じ行動を延々と繰り返すことがあります。API利用料が高額になるリスクがあるので、実行回数に制限(リミット)をかけるのが必須です。
- 動きが遅い「思考→行動→観察」を何度も繰り返すため、単純なチャットボットに比べて回答までの待ち時間が長くなります。
今後の学習の指針
お疲れ様でした!これで、「モデルを動かす」ことから始まり、「学習させ(ファインチューニング)」、「知識を与え(RAG)」、ついには「行動させる(エージェント)」ところまで辿り着きました。
ここまでの知識があれば、あなたはもう「AIを使って何かを作りたい人」ではなく、「AIアプリケーションを作れるエンジニア」です。
これからの学習は、ぜひ「アウトプット」に重心を移してください。
- 独自のツールを作ってみるLangChainを使えば、自作のAPI(社内の在庫検索システムなど)をツールとしてAIに渡すこともできます。「在庫確認エージェント」なんて面白そうじゃありませんか?
- UIを作り込む前回紹介したGradioやStreamlitを使って、チャット画面を作り、友人や同僚に使ってもらいましょう。
AI技術は日進月歩で、来月にはまた新しい技術が出ているかもしれません。でも、この連載で学んだ「Transformerの基礎」や「AIにどう指示を出すか」という根本の考え方は、どんなに技術が進んでも変わりません。
恐れずに、新しい技術で遊び倒してください。あなたの書くコードが、未来の世界を少し便利にすることを信じています。
長い間、この連載にお付き合いいただき、本当にありがとうございました!
【魔法の軽量化】巨大なAIをノートPCで動かす!「量子化」の仕組みと実践
前回は、AIに道具を持たせて仕事をさせる「AIエージェント」について学びました。AIが自分で考えて行動する様子は、まさに未来のテクノロジーでしたね。
しかし、高性能なAIモデルを使えば使うほど、ある「壁」にぶつかることになります。それは「メモリ不足(Out of Memory)」という壁です。
「もっと賢いモデルを使いたいけど、自分のパソコンじゃ動かない…」
「クラウドの高いGPUを借りるお金がない…」
そんな悩みを抱える新人エンジニアの皆さんに朗報です。実は、巨大なAIモデルをギュッと圧縮して、普通のパソコンでも動くサイズにする魔法のような技術があります。
それが「量子化(Quantization)」です。
今日は、AIのダイエット技術とも言えるこの手法を使って、限られた環境で最強のモデルを動かす方法を伝授します。
量子化とは?AIの「解像度」を下げる技術
量子化を一言で説明すると、「計算の精度を少しだけ落として、データ量を劇的に減らす技術」です。
イメージしやすいように、写真で例えてみましょう。
プロのカメラマンが撮った写真は、非常に画質が良く、ファイルサイズも巨大ですよね。でも、スマホの画面で見るだけなら、そんなに高画質である必要はありません。画質を少し落としても、見た目はほとんど変わらず、容量は何分の一にもなります。
AIモデルも同じです。通常、AIの中にある「重み(パラメータ)」という数字は、非常に細かい桁数まで保存されています。
通常のAI(32ビット):

量子化したAI(4ビット):

このように、細かい端数を「四捨五入」して大雑把にすることで、メモリの使用量を劇的に減らすのです。
32ビット vs 4ビット:どれくらい軽くなる?
コンピュータの世界では、数字を表現するデータの大きさを「ビット」で表します。
- FP32(32ビット浮動小数点数)通常のAIモデルの形式です。非常に高精度ですが、メモリを大量に食います。例えるなら、高級ホテルのフルコースディナーです。場所も取るしお金もかかります。
- FP16(16ビット)最近の主流です。32ビットの半分のサイズで、精度はほぼ変わりません。
- INT8(8ビット) / INT4(4ビット)これが量子化の領域です。INT4なら、なんと元のサイズの
まで圧縮できます。フルコースをカロリーメイトに圧縮するようなものです。
計算式で見てみましょう。例えば、70億個のパラメータを持つモデル(7Bモデル)を動かすのに必要なメモリは以下のようになります。
32ビットの場合: 
4ビットの場合: 
これなら、あなたのノートPCでも動かせそうですよね?
実践!bitsandbytesでモデルを軽量化してロードする
では、実際にPythonで量子化を試してみましょう。
Hugging Faceには bitsandbytes という、量子化を簡単に行うためのライブラリがあります。
事前に以下のライブラリをインストールしておいてください。
pip install transformers bitsandbytes accelerateコードは驚くほど簡単です。モデルを読み込むときに「設定」を渡すだけです。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
# 量子化の設定を作成
# 「4ビットで読み込んでね」という指示書です
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16
)
# モデルをロード
# ここで設定を渡すことで、ダウンロードしながら圧縮してくれます
model_name = "cyberagent/open-calm-7b" # 例として70億パラメータのモデル
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=quantization_config,
device_map="auto" # 空いているGPUに自動で割り当て
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# あとはいつも通り使うだけ!
text = "AIの軽量化技術について教えて"
inputs = tokenizer(text, return_tensors="pt").to(model.device)
with torch.no_grad():
output_ids = model.generate(**inputs, max_new_tokens=100)
print(tokenizer.decode(output_ids[0], skip_special_tokens=True))
このコードを実行すると、通常なら20GB以上のメモリが必要なモデルが、わずかなメモリでサクサク動くはずです。これが量子化の威力です。
量子化のメリットとデメリット
良いことづくめに見えますが、エンジニアとしてトレードオフ(交換条件)を理解しておくことが大切です。
メリット
- 低スペックな環境でも動く高価なGPUサーバーを借りなくても、手元のゲーミングPCや、無料枠のGoogle Colabで巨大なモデルを実験できます。
- 推論速度が上がる扱うデータ量が減るため、計算やデータの転送が速くなり、AIの返答が早くなることが多いです。
- コスト削減必要なマシンスペックが下がるため、運用コストを大幅に下げることができます。
デメリット
- 精度が少し落ちる数字を丸めているため、厳密な計算や、微妙なニュアンスの表現力がわずかに低下することがあります。ただ、最近の技術(QLoRAなど)では、その劣化は人間には分からないレベルまで抑えられています。
- 設定が少し複雑GPUの種類によっては対応していない場合があったり、ライブラリのバージョン合わせに苦労したりすることがあります。
今後の学習の指針
今回は、AIを軽量化する「量子化」について学びました。これであなたは、巨大なモデルを飼いならす術を手に入れました。
「自宅のPCで最強のAIを動かす」。これは全エンジニアのロマンです。
この技術を突き詰めていくと、インターネットに繋がっていないローカル環境だけで動く「プライベートAI」を作れるようになります。
次回のステップとしておすすめしたいのが、「ローカルLLMの実行ツール(Ollamaやllama.cpp)」 に触れてみることです。
Pythonコードすら書かずに、ターミナルからコマンド一発でAIと会話できるツールたちが、今世界中で大流行しています。
自分のPCの中に、自分だけの専属アドバイザーを住まわせてみませんか?
AI開発の深淵へ、もう一歩踏み込んでいきましょう!
【脱・文字だけ】AIに「芸術」を教える?画像生成モデルとマルチモーダルAIの世界
前回の記事では、AIを軽量化して自分のPCで動かす「量子化」という職人技を学びましたね。これでエンジニアとしての足腰はかなり強くなりました。
でも、ふと思いませんか?
「今まで扱ってきたのって、全部『文字(テキスト)』だけじゃない?」と。
そうです。私たちはこれまで、AIに小説を書かせたり、計算をさせたりと、言葉の世界だけで遊んでいました。しかし、人間の知性は言葉だけではありません。私たちは美しい景色を見て感動し、音楽を聴いて涙し、絵を描いて表現します。
今回は、AI学習の新たな地平、「マルチモーダル(Multimodal)」の世界へ飛び込みましょう。
特に、世界中で大ブームを巻き起こしている「画像生成AI」を、Hugging Faceの diffusers ライブラリを使って動かしてみます。
AIが「言葉」を超えて「芸術」を理解したとき、何が起きるのか。一緒に体験してみましょう!
マルチモーダルとは?AIに「五感」を与える
「マルチモーダル」という言葉、難しそうですが、分解すれば簡単です。「マルチ(複数の)」+「モード(種類)」です。
テキスト、画像、音声、動画など、異なる種類のデータを組み合わせて扱う技術のことを指します。
その中でも、今一番ホットなのが「画像生成」です。「Stable Diffusion(ステイブル・ディフュージョン)」という名前を聞いたことがある人も多いのではないでしょうか?
これは、あなたが「夕暮れの海辺で走る猫」と文字で指示(プロンプト)を送ると、AIがその通りの絵を一瞬で描いてくれる魔法のような技術です。
仕組み解説:ノイズから絵を彫り出す「拡散モデル」
画像生成AIは、どうやって何もないところから絵を描いているのでしょうか?
彼らが使っているのは「拡散モデル(Diffusion Model)」という仕組みです。
イメージしてください。真っ白なキャンバスに、砂嵐のような「ノイズ(雑音)」が一面に広がっています。テレビの砂嵐のような状態です。
AIは、この砂嵐の中から、「ノイズじゃない部分」を見つけ出し、少しずつ取り除いていきます。
まるで、彫刻家が四角い石の塊から、余分な石を削り落として美しい彫像を彫り出すような作業です。
これを数式風に表現すると、以下のような引き算を何十回も繰り返しています。
きれいな画像
AIは「犬の画像には、こんなノイズは無いはずだ」と予測し、引き算を行います。これを繰り返すうちに、砂嵐の中から徐々に鮮明な犬の姿が浮かび上がってくるのです。
実践!diffusersライブラリで絵を描かせてみよう
では、Hugging Faceが提供する画像生成のためのライブラリ diffusers を使って、実際に絵を描かせてみましょう。
今回は、Stable Diffusionのモデルを動かします。GPUが必要になるので、Google Colabなどの環境で試すのがおすすめです。
必要なライブラリ:
pip install diffusers transformers accelerate torchコードは驚くほど短いです。
import torch
from diffusers import StableDiffusionPipeline
# 1. モデルをロードする(Hugging Faceから借りてくる)
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
# GPUを使う設定(これをしないと遅くて待っていられません!)
pipe = pipe.to("cuda")
# 2. 呪文(プロンプト)を唱える
prompt = "An astronaut riding a horse on mars, highly detailed, 8k"
# (火星で馬に乗っている宇宙飛行士、超高精細、8k画質)
# 3. 生成実行!
image = pipe(prompt).images[0]
# 4. 画像を保存・表示
image.save("astronaut_on_mars.png")
image.show()これを実行して数秒待つと…画面には、火星の大地を馬で駆ける宇宙飛行士の絵が表示されるはずです。
「horse(馬)」を「dragon(ドラゴン)」に変えたり、「mars(火星)」を「tokyo(東京)」に変えたりして、AIという画家に色々な無茶振りをしてみてください。
専門用語:ネガティブプロンプト
画像生成を制御する上で、覚えておきたい重要なテクニックがあります。それが「ネガティブプロンプト」です。
これは、「描いてほしいもの」ではなく、「描いてほしくないもの」を指定する指示のことです。
例えば、AIに人物を描かせると、指が6本になったり、腕が曲がっていたりすることがよくあります。
そこで、「低画質」「奇形」「指の欠損」などをネガティブプロンプトとして指定すると、AIは「そういう要素は避ければいいんだな」と理解し、画像のクオリティが劇的に向上します。
良い絵
この引き算の美学こそが、プロンプトエンジニアの腕の見せ所です。
メリットとデメリット(倫理的な話)
画像生成AIは強力ですが、テキスト以上に社会的な影響が大きいため、注意が必要です。
メリット
- 素材作成のコストがゼロにWebサイトの背景画像や、プレゼン資料の挿絵など、著作権フリーの素材を自分で無限に作り出せます。
- アイデアの具現化絵が描けない人でも、頭の中のイメージを可視化し、デザイナーに伝えるためのラフ画として使えます。
デメリット
- 著作権の問題AIはネット上の大量の画像を学習しています。特定のアーティストの画風を真似たり、既存のキャラクターを描かせたりすることには、法的な議論やリスクが伴います。
- フェイク画像の拡散実在する人物が言ってもいないことを言っている画像や、起きてもいない事件の画像を簡単に作れてしまいます。エンジニアとして、技術の悪用には常に警戒心を持つ必要があります。
今後の学習の指針
おめでとうございます!これであなたは「言葉」だけでなく「視覚」も扱えるエンジニアになりました。
画像生成の世界は奥が深く、自分の顔写真を学習させてアバターを作ったり(LoRA)、ラフ画から清書を行ったり(ControlNet)と、進化が止まりません。
さて、人間の感覚で残っているものは何でしょうか?
視覚ときたら、次は「聴覚」ですよね。
次回のステップとしておすすめなのが、「音声認識(Whisper)」と「音声合成」の世界です。
AIがあなたの声を聴き取り、そしてAIがあなたの声で喋り返す。
ここまで揃えば、いよいよ映画に出てくるような「完全なAIアシスタント」の完成です。
音の世界も、Hugging Faceなら数行のコードで操れます。ぜひ、耳を澄ませて次の技術へ進んでみてください!
【聴覚獲得】AIに「耳」と「口」を与える!Whisperで学ぶ音声認識と音声合成
前回の記事では、AIに「目」を与えて、言葉から絵を描く方法を学びましたね。テキスト、そして画像。AIは着実に人間の感覚を身につけてきています。
さて、人間の五感で、まだAIに教えていない重要な感覚があります。それは「聴覚」です。
私たちがSF映画で見るAIは、キーボードをカタカタ叩かなくても、話しかければ声で返してくれますよね?あのかっこいい体験を実現するためには、2つの技術が必要です。
- 音声認識(ASR):AIの「耳」。人間の声を文字に変換する技術。
- 音声合成(TTS):AIの「口」。文字を人間の声に変換する技術。
今回は、Hugging Faceで最も人気のあるモデルの一つである「Whisper(ウィスパー)」を使って、AIに「聴く力」を授けてみましょう。これができれば、議事録の自動化や、あなたの声で動くロボットも夢ではありませんよ!
音は「波」ではなく「絵」である?
まず、AIがどうやって音を理解しているのか、その仕組みを少しだけ覗いてみましょう。
高校の物理で習ったように、音は空気の振動、つまり「波」です。
マイクで拾った音は、時間とともに変化する波形データとして保存されます。
しかし、今のAI(特にTransformer)は、この波形をそのまま聞いているわけではありません。実は、音を一度「画像」に変換しているのです。
これを「スペクトログラム」と呼びます。横軸を時間、縦軸を音の高さ(周波数)、色の濃さを音の大きさにして、音をヒートマップのようなグラフに変換します。
つまり、AIにとって「声を聴き取る」という作業は、「スペクトログラムという画像を読んで、そこに何が描いてあるか(何と言っているか)を当てる」という、画像認識の一種なのです。
前回の画像生成の話とつながってきましたね!
音声認識の革命児「Whisper」
今回使う「Whisper」は、ChatGPTの開発元であるOpenAIが公開したモデルです。
このモデルの凄いところは、日本語を含む多言語の認識精度が桁違いに高いことです。「えーっと」といった言い淀みや、早口、多少の雑音があっても、驚くほど正確に文字に起こしてくれます。
これをゼロから作ろうとすると、スーパーコンピュータを使っても何ヶ月もかかりますが、Hugging Faceを使えば、私たちは完成品を借りてくるだけでOKです。
実践!AIにあなたの声を聴かせてみよう
では、Pythonで実装してみましょう。
今回は、音声認識(耳)の部分を実装します。
事前に以下のライブラリをインストールしておいてください。
pip install transformers datasets librosa torch※音声ファイルを扱うため、librosa というライブラリも使います。また、PCにマイク入力環境がない場合やGoogle Colabの場合は、サンプル音声データをダウンロードして使います。
from transformers import pipeline
from datasets import load_dataset
# 1. モデルの準備(AIに耳をつける)
# "openai/whisper-tiny" は軽量版のモデルです。
# 精度を上げたい場合は "openai/whisper-large" などに変えてください。
transcriber = pipeline("automatic-speech-recognition", model="openai/whisper-tiny")
# 2. 音声データの準備
# ここではHugging Faceにあるサンプルの音声データセットを使います
# 実際には、自分の声を録音した ".wav" や ".mp3" ファイルを指定できます
dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
sample_audio = dataset[0]["audio"]["array"]
# 3. 認識実行!(耳を澄ませる)
# 日本語の音声を読ませる場合は、generate_kwargs={"language": "japanese"} を追加します
result = transcriber(sample_audio)
# 4. 結果を表示
print("AIが聴き取った内容:")
print(result["text"])
たったこれだけで、音声データがテキストに変換されます。
もし手元に「test.mp3」などのファイルがあれば、transcriber("test.mp3") とファイルパスを渡すだけで、あなたの声を文字にしてくれますよ。
音声合成(TTS)でAIに喋らせる
「耳」ができたら、次は「口」ですよね。
Hugging Faceには「SpeechT5」や「Bark」といった、テキストを声に変えるモデルもたくさんあります。
コードの雰囲気だけ紹介すると、こんなに簡単です。
# 音声合成のパイプラインを作る
synthesizer = pipeline("text-to-speech", model="suno/bark-small")
# 喋らせたい言葉
text = "こんにちは!私はAIです。歌うこともできますよ。"
# 音声を生成
speech = synthesizer(text)
# この speech データをファイルに保存すれば、再生できます!これらを組み合わせれば、「あなたの声を聞いて(Whisper)、AIが脳で考え(LLM)、声で返事をする(TTS)」という、夢の対話システムが完成します。
メリットとデメリット
音声技術は便利ですが、扱うデータの性質上、特有の注意点があります。
メリット
- ハンズフリー操作が可能に料理中や運転中など、手が離せない状況でもAIを使えるようになります。
- 情報のバリアフリー化視覚障害のある方に画面の内容を読み上げたり、聴覚障害のある方に音声を文字で伝えたりと、アクセシビリティを劇的に向上させます。
デメリット
- プライバシーの侵害音声は指紋と同じく、個人の特定が可能な「個人情報」です。無断で録音したり、AIに学習させたりすることは法律や倫理に触れる可能性があります。
- ディープフェイク(声の偽造)たった数秒の音声データから、その人の声を完全にコピーして、言ってもいないことを喋らせる技術も生まれています。オレオレ詐欺などに悪用されるリスクがあり、技術者としてのモラルが問われます。
今後の学習の指針
これで、テキスト、画像、そして音声と、主要なデータ形式をすべて扱えるようになりました。あなたはもう、立派な「マルチモーダルAIエンジニア」です。
しかし、私たちが生きているこの世界は、静止画や音声だけではありませんよね?
そう、「時間」という軸があります。つまり「動画(Video)」です。
動画は、パラパラ漫画のように「大量の画像」と「音声」が組み合わさった、究極のデータ形式です。
ここまでの知識を総動員すれば、動画の中身を理解したり、新しい動画を作り出したりすることも夢ではありません。
次回は、これまでの総決算として、「動画生成・解析AI」の世界を少しだけ覗いてみましょう。
そして、この長い連載の締めくくりとして、AIエンジニアがこれからの時代をどう生き抜くべきか、最後に熱いメッセージを送らせてください。
さあ、ラストスパートです!準備はいいですか?
【最終回】動画生成AIの衝撃と、これからのエンジニアが生き残るための「3つの武器」
ついに、この連載も最終回を迎えました。
最初は「AIなんて難しそう」と怯えていたのが嘘のようですね。私たちはこれまで、文章を書き、絵を描き、声を聴き、喋るAIを作ってきました。
そして今日、最後に触れるのは、それら全ての集大成である「動画(Video)」の世界です。
さらに記事の後半では、爆速で進化するこのAI時代において、私たちエンジニアがどうやって生き残り、価値を発揮し続けていくべきか。そのための「羅針盤」をお渡しします。
技術の話と、未来の話。少し長くなりますが、最後までお付き合いください。
動画生成AI:時間軸を持った芸術
画像生成AI(Stable Diffusionなど)が静止画を描く画家だとしたら、動画生成AIは映画監督です。
動画とは、そもそも何でしょうか?
パラパラ漫画を思い出してください。少しずつ違う絵を連続して見せることで、あたかも動いているように錯覚させていますよね。つまり、動画データの本質はこういうことです。
動画
AIにとって、ただ綺麗な絵を一枚描くだけなら簡単です。しかし、「動画」にするためには、1秒間に24枚や30枚もの絵を描き続けなければなりません。
しかも、前の絵と次の絵で、キャラクターの顔が変わったり、背景が急に消えたりしてはいけません。この「一貫性」を保つのが、動画生成AIの最大の難関でした。
しかし、最新の技術(SoraやRunwayなど)は、この壁を乗り越えつつあります。
Hugging Faceの diffusers ライブラリを使えば、短い動画なら誰でも生成することができます。コードのイメージを見てみましょう。
import torch
from diffusers import DiffusionPipeline, DPMSolverMultistepScheduler
from diffusers.utils import export_to_video
# 動画生成用のパイプラインを準備
pipe = DiffusionPipeline.from_pretrained("damo-vilab/text-to-video-ms-1.7b", torch_dtype=torch.float16, variant="fp16")
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
# 呪文(プロンプト)
prompt = "Spiderman is surfing"
# (スパイダーマンがサーフィンをしている)
# 動画生成実行!
video_frames = pipe(prompt, num_inference_steps=25).frames[0]
# 動画ファイルとして保存
video_path = export_to_video(video_frames, "spiderman_surfing.mp4")これを実行すると、数秒間の短い動画ですが、スパイダーマンが波に乗る様子が生成されます。
テキストから、映像が生まれる。数年前まではSFの世界だったことが、今あなたの手元で起きているのです。
AI時代を生き抜くための「3つの武器」
さて、技術解説はここまでにしましょう。
ここまで学んできて、ワクワクすると同時に、こんな不安も感じていませんか?
「技術の進化が速すぎる。せっかく覚えても、すぐに古くなるんじゃないか?」
「AIがコードを書けるようになったら、エンジニアは要らなくなるんじゃないか?」
その答えは、半分イエスで、半分ノーです。
「ただコードを書くだけ」のエンジニアは厳しくなるでしょう。しかし、AIを相棒にできるエンジニアは、これまでの100倍の価値を生み出せます。
これからの時代に必要な「3つの武器」を紹介します。
1. キャッチアップ力(知的好奇心)
今日の最新技術は、半年後の「当たり前」、1年後の「時代遅れ」です。
特定のライブラリの使い方を丸暗記することに意味はありません。それよりも、「新しい技術が出てきたときに、それを面白がって触ってみる姿勢」が最強のスキルになります。
「Hugging Faceに新しいモデルが出たぞ!とりあえず動かしてみよう」
このフットワークの軽ささえあれば、あなたは常に最先端に居続けられます。変化を恐れず、楽しんでください。
2. システム設計力(組み合わせる力)
AIモデル単体では、ただのファイルです。
それが社会の役に立つには、使いやすい画面(UI)、データを保存するデータベース、動かすためのサーバーなど、システム全体を組み立てる必要があります。
「この課題を解決するには、RAGを使って社内データを検索させよう」
「ユーザーが待たされないように、重い処理は裏側で動かそう」
AIという「部品」の特性を理解し、それをどうシステム全体に組み込むか。この「設計図を描く力」は、AIにはまだ難しい、人間だけの領域です。
3. 課題発見力(愛と倫理)
これが最も重要です。
AIは「どうやって作るか(How)」については答えられますが、「何を作るべきか(What)」や「なぜ作るのか(Why)」は決められません。
「お年寄りがスマホの操作で困っているから、音声で動くアプリを作ろう」
「この使い方は誰かを傷つけるかもしれないから、制限をかけよう」
誰かの痛みに気づき、解決したいと願う「共感」や「愛」。そして、技術を正しく使うための「倫理観」。
これこそが、エンジニアの魂です。技術はあくまで、誰かを幸せにするための手段でしかないことを忘れないでください。
終わりの言葉:あなたはもう、魔法使いだ
全12回(想定)にわたる長い旅、本当にお疲れ様でした。
最初の頃を思い出してください。「環境構築って何?」と言っていたあなたが、今では最新のAIモデルを操り、マルチモーダルなシステムを理解しています。
あなたは今、現代の魔法使いです。
その魔法の杖(キーボード)を使って、何を作りますか?
面倒な作業を自動化して、同僚を早く帰してあげますか?
面白いアプリを作って、友人を笑わせますか?
それとも、世の中の大きな問題を解決するサービスを立ち上げますか?
Hugging Faceという巨人の肩に乗り、あなたのアイデアと情熱を掛け合わせれば、作れないものはありません。
さあ、ブラウザを閉じて、エディタを開きましょう。
あなたの作り出す未来を、楽しみにしています。
今までありがとうございました。また、コードの世界のどこかでお会いしましょう!
セイ・コンサルティング・グループの新人エンジニア研修のメニューへのリンク
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。

