
【AIの回答精度アップ】間違えないAIを作るには?「自己整合性プロンプティング」を新人エンジニアに解説
 山崎講師
山崎講師こんにちは。ゆうせいです。
新人エンジニアの皆さん、生成AIを使っていてこんな経験はありませんか?
「あれ? さっきと同じ質問をしたのに、違う答えが返ってきた」
「論理パズルや数学の問題を解かせると、自信満々に間違った答えを出してくる」
AIは非常に賢いですが、ときどき「知ったかぶり」や「計算ミス」をします。これを防ぎ、AIの信頼性を劇的に高めるテクニックがあることをご存知でしょうか。
その名も「自己整合性プロンプティング(Self-Consistency Prompting)」です。
名前だけ聞くと、「なんだか難しそうだな……」と身構えてしまうかもしれません。でも大丈夫です。仕組みはとてもシンプルで、人間社会の「ある行動」とまったく同じなのです。
今日は、AIがより賢く答えを導き出すための、この魔法のような手法について一緒に学んでいきましょう!
一人の天才より、三人の相談?
まず、この手法のイメージを掴むために、例え話をしましょう。
あなたは数学の難問を解こうとしています。目の前に、数学が得意な学生が1人います。彼に問題を解かせたとしましょう。彼は優秀ですが、たまにケアレスミスをします。もし彼がうっかり計算ミスをして、そのまま答えを出したら、あなたはそれが正解だと信じてしまいますよね。
では、学生が「5人」いたらどうでしょうか?
5人全員に、それぞれ別々に計算してもらいます。そして答えを見せ合います。
- 学生A:答えは 10 です。
- 学生B:答えは 10 です。
- 学生C:答えは 12 です。
- 学生D:答えは 10 です。
- 学生E:答えは 8 です。
この結果を見たら、あなたはどの答えを採用しますか?
間違いなく「10」を選びますよね。なぜなら、5人中3人が同じ答えに辿り着いたからです。
これが「自己整合性プロンプティング」の正体です。
一言で言えば、「AIに何度も考えさせて、一番多かった答えを採用する(多数決をとる)」というテクニックなのです。
技術的な仕組みを深掘りしよう
ここからは、もう少しエンジニアらしく、裏側で起きていることを解説します。この手法は、2022年にGoogleの研究チームによって発表されました。
手順は大きく分けて3つのステップがあります。
1. 思考の連鎖(CoT)を促す
まず、AIにただ答えを聞くのではなく、「ステップ・バイ・ステップで考えて」と指示します。これを「Chain-of-Thought(思考の連鎖)」と呼びます。計算過程や論理の道筋を書かせることで、回答の精度を上げる基本テクニックです。
2. サンプリング(多様な回答を作る)
ここがポイントです。同じプロンプト(命令)を、あえて「ランダム性」を持たせて複数回実行します。
通常、AIの設定には「Temperature(温度)」というパラメータがあります。
- 温度が低い(
に近い):毎回同じ、確実な答えを返す。
- 温度が高い(
に近い):毎回少し違う、創造的な答えを返す。
自己整合性プロンプティングでは、この温度をあえて少し高く設定します。そうすることで、AIは毎回微妙に異なるルート(思考過程)を通って答えを出そうとします。
3. マジョリティ・ボート(多数決)
最後に、集まった複数の回答を集計します。
思考のルート(過程)はバラバラでも、論理が正しければ、最終的な「答え」は一致するはずですよね?
最も多く出現した答え(整合性が取れている答え)を、最終的な回答として採用します。
数式で見る「信頼度」の考え方
なぜ、この方法で精度が上がるのでしょうか。簡単な数式のイメージで考えてみましょう。
通常のAIへの質問は、一発勝負です。

もしAIが 
一方、自己整合性プロンプティングはこうなります。

たとえば、3回推論させて、3回とも答えが一致したなら、「偶然3回連続で同じ間違いをする確率」は極めて低くなりますよね。
数式的に見ても、サンプル数(試行回数)を増やして共通項をとることで、ノイズ(間違い)を取り除けることがわかります。
メリットとデメリット
非常に強力なこの手法ですが、万能ではありません。現場で導入する前に、メリットとデメリットをしっかり理解しておきましょう。
メリット:論理的ミスが激減する
数学、常識推論、記号操作など、明確な正解があるタスクにおいて、劇的に精度が向上します。単なる「Chain-of-Thought」よりも高いスコアが出ることが研究で実証されています。
デメリット:コストと時間がかかる
ここが最大のネックです。
例えば「5回多数決」を行う場合、AIを5回動かすことになります。単純計算で、APIの利用料金(コスト)は 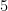
「速くて安い」を求めるシステムには不向きかもしれません。
「お金と時間はかかってもいいから、絶対に間違えてはいけない」という場面(金融データの分析や医療論文の要約など)でこそ、真価を発揮する技術です。
今後の学習の指針
いかがでしたか?
自己整合性プロンプティングとは、AIの中に「合議制の会議室」を作るようなものでした。
「三人寄れば文殊の知恵」ということわざがありますが、AIも一人で考えさせるより、何度も考えさせて答え合わせをしたほうが賢くなるなんて、なんだか人間臭くて面白いと思いませんか?
これからプロンプトエンジニアリングを極めたい方は、ぜひ次のステップとして以下のキーワードを調べてみてください。
- アンサンブル学習(Ensemble Learning):複数のモデルを組み合わせて精度を上げる、機械学習の元祖となる考え方です。
- Tree of Thoughts(思考の木):自己整合性をさらに発展させ、思考の分岐を探索する最新の手法です。
- Temperature(温度パラメータ):AIの創造性をコントロールする設定値です。
AIの「脳内」で何が起きているかを想像しながら、いろいろなプロンプトを試してみてくださいね。
それでは、またお会いしましょう。
明日から使えるアクションプラン
まずは手元のChatGPTなどで、数学の難しい文章題を「5回」入力してみてください(「新しいチャット」で毎回リセットするのがコツです)。微妙に違う解説が出てくるのを確認し、一番多かった答えを探す「手動・自己整合性プロンプティング」を体験してみましょう!
セイ・コンサルティング・グループの新人エンジニア研修のメニューへのリンク
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。

