
A/Bテストの失敗を未然に防ぐ!「データは何件必要?」に即答するための検出力分析入門
 山崎講師
山崎講師こんにちは。ゆうせいです。
これまで「P値」と「効果量」について学んできましたが、今日はデータ分析の計画段階で最も重要な質問に答えるための技術を紹介します。
上司やクライアントから、こんなことを聞かれたことはありませんか?
「で、このA/Bテスト、何人のユーザーで実験すればいいの? 100人? 1万人?」
これに対して「えっと、多ければ多いほどいいと思います……」なんて答えてしまっては、プロのエンジニア失格です! データが多すぎれば時間と予算の無駄ですし、少なすぎれば本当は効果があるのに見逃してしまいます。
そこで登場するのが、今回解説する「検出力分析(パワーアナリシス)」です。
これを使えば、「この実験を成功させるには、最低これくらいのデータ数が必要です」と、数学的な根拠を持って答えられるようになります。まるで未来予知のようなこのスキル、ぜひ身につけていきましょう!
検出力分析ってなに?
検出力分析とは、一言で言えば「実験に必要なデータ数(サンプルサイズ)を逆算する技術」です。
これを理解するために、少し例え話をしましょう。
あなたは広い砂浜で、落としてしまった「指輪」を探しています。
- 指輪の大きさ(効果量): 大きな指輪ならすぐ見つかりますが、小さな指輪だと見つけるのは大変です。
- 探す人数(サンプルサイズ): 1人で探すより、100人で探したほうが早く見つかります。
- 見つける確率(検出力): 「もしそこに指輪があるなら、80%の確率で発見できる」という確実性のことです。
検出力分析とは、「これくらいの大きさの指輪(効果量)を、これくらいの確実性(検出力)で見つけたいなら、何人の捜索隊(サンプルサイズ)が必要か?」を計算することなのです。
4つのパラメータを理解しよう
検出力分析を行うには、次の4つの要素が互いに関連し合っていることを理解する必要があります。これらはシーソーのような関係にあります。
1. 有意水準(Alpha)
これは「誤検知のリスク」のことです。本当は差がないのに「差がある!」と間違ってしまう確率ですね。通常は 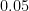
2. 検出力(Power / 1 - Beta)
これが今回の主役です。「本当に差があるときに、正しく『差がある』と言い当てられる確率」のことです。
一般的には 
3. 効果量(Effect Size)
前回学んだ「差の大きさ」です。
「劇的な改善(効果量大)」を見つけたいなら、データは少なくて済みます。逆に、「ほんのわずかな改善(効果量小)」を見つけたいなら、大量のデータが必要になります。
4. サンプルサイズ(Sample Size)
実験に必要なデータの数です。上の3つ(有意水準、検出力、効果量)を決めると、このサンプルサイズが自動的に計算されます。
なぜ事前に計算する必要があるの?
多くの失敗するA/Bテストは、この計算をサボったことが原因です。
たとえば、「クリック率を1%改善したい(効果量は小さい)」のに、「データは100件だけ(サンプルサイズ小)」で実験を始めたとします。
これは、「砂浜に埋まったコンタクトレンズ(極小の差)を、虫眼鏡も持たずに裸眼(低パワー)で探す」ようなものです。
結果として、本当は改善効果があったとしても、P値が下がらず「有意差なし」という判定になります。これを「第2種の過誤(見逃し)」と呼びます。せっかくの良いアイデアが、準備不足のせいで「効果なし」として葬り去られてしまうのです。これは非常にもったいないですよね。
実践:Pythonで必要なデータ数を計算する
では、実際にPythonを使って計算してみましょう。ここでは statsmodels というライブラリを使います。
シナリオ:
新しい機能の効果を検証したい。
- 過去の経験から、効果量は「中くらい(
)」と予想される。
- 有意水準は一般的
- 検出力はしっかり
- 必要なデータ数は?
Python
from statsmodels.stats.power import TTestIndPower
分析ツールのインスタンス化
analysis = TTestIndPower()
パラメータの設定
effect_size = 0.5 # 効果量(中くらい)
alpha = 0.05 # 有意水準(5%)
power = 0.8 # 検出力(80%)
サンプルサイズの計算
ratio=1.0 は、2つのグループの人数が同じ場合を意味します
result = analysis.solve_power(
effect_size=effect_size,
nobs1=None,
alpha=alpha,
power=power,
ratio=1.0
)
print(f"必要なデータ数(片方のグループあたり): {result:.1f}")
このコードを実行すると、おおよそ 
つまり、Aグループ64人、Bグループ64人の、合計128人のデータがあれば、80%の確率で「中くらいの差」を見抜けることがわかります。
もしここで、「もっと小さな差(効果量 

「小さな差を見つけるには、それだけコスト(データ数)がかかる」ということが、数字として明確になるわけです。
まとめ:計画なき実験に勝利なし
検出力分析は、実験の「設計図」を作る作業です。
- 検出力(Power): 差を見逃さない確率。通常は80%を目指す。
- 関係性: 小さな差を見つけようとするほど、必要なデータ数は爆発的に増える。
- メリット: 「やってみたけど分かりませんでした」という時間の無駄を、実験前に防ぐことができる。
上司に「データ数は何件必要?」と聞かれたら、こう答えましょう。
「どのくらいの改善(効果量)を期待していますか? それによって必要な件数が変わります。もし小さな改善も確実に拾いたいなら1000件必要ですが、大きな改善だけでいいなら100件で十分ですよ」
こう言えれば、あなたはもう単なる作業者ではなく、プロジェクトの設計者です!
今後の学習の指針
これで「統計的仮説検定」の基礎となる3点セット(P値、効果量、検出力)が揃いました。
次に学ぶべきステップとして、「ベイズ統計学」の世界を覗いてみることをおすすめします。
これまで学んできた統計(頻度論)は「データ数が決まってから結論を出す」スタイルですが、ベイズ統計は「データが入ってくるたびに確率を更新していく」スタイルで、現代のWebマーケティングやAI開発の現場で非常に人気があります。
「A/Bテストを途中で止めてもいいのか?」という現場の悩みに答えてくれる強力なツールになりますよ。
それでは、また次回の記事でお会いしましょう!
セイ・コンサルティング・グループの新人エンジニア研修のメニューへのリンク
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。

