
「P値だけでは不十分?」ビジネスを動かす真の指標「効果量」を直感的に理解する
 山崎講師
山崎講師こんにちは。ゆうせいです。
前回は「データ数が増えるとP値が下がってしまう」という、統計の落とし穴についてお話ししましたね。「差があることはわかったけれど、それがビジネスにとって本当に意味がある差なのか?」という疑問が残ったはずです。
今回は、その疑問にズバリ答えるための強力な武器、「効果量(Effect Size)」について解説します。
もしあなたが上司に、「で、その施策でどれくらい儲かるの?」と聞かれて言葉に詰まったことがあるなら、この記事はあなたのためのものです。この概念を知れば、データ分析の結果を「ビジネスの言葉」に翻訳できるようになりますよ!
そもそも「効果量」とは何か?
一言で言うと、効果量とは「その差がどれくらい大きいか?」を表す数値です。
P値と効果量の違いは、よく次のような例えで説明されます。
- P値(確率):「スイッチはONか、OFFか?」を判定するもの。(差があるかないか、だけを教えてくれる)
- 効果量(大きさ):「ボリュームはどれくらい大きいか?」を測定するもの。(その差のインパクトの強さを教えてくれる)
わかりやすい例え話
想像してみてください。あなたは新しい「英語学習アプリ」を開発しました。1万人ユーザーでテストをしたところ、次のような結果が出ました。
- 旧アプリ: TOEIC平均 600点
- 新アプリ: TOEIC平均 601点
- P値: 0.01(1%以下)
P値を見ると「統計的に有意な差がある」ので、新アプリは効果があると言えます。でも、たった「1点」しか上がらないアプリに、ユーザーは月額料金を払うでしょうか?
ここで効果量の出番です。この「1点の差」を計算してみると、効果量は「ほぼゼロ」になります。つまり、「統計的には差があるけれど、実質的な効果はない」という判断ができるようになるのです。
なぜP値だけじゃダメなの?
新人エンジニアのみなさんにぜひ知っておいてほしいのは、P値の弱点です。前回の復習になりますが、P値は「データ数(サンプルサイズ)」の影響をモロに受けます。
データが巨大であれば、どんなにゴミのような小さな差でも「有意(P < 0.05)」になってしまいます。これでは、本当に価値のある改善なのか判断できませんよね。
一方、効果量はデータ数の影響を受けません。
データが100個でも100万個でも、「差の大きさ」そのものが変わらなければ、効果量の値は変わりません。だからこそ、ビッグデータを扱う現代のエンジニアにとって、P値よりも信頼できる「羅針盤」になり得るのです。
代表的な効果量:「コーエンのd」
効果量にはいくつか種類がありますが、エンジニアがまず覚えるべきは「コーエンのd(Cohen's d)」です。
これは、2つのグループの平均値の差を、データの「ばらつき(標準偏差)」で割ったものです。
数式で見るイメージ
数式アレルギーの方も安心してください。日本語で書くとこうなります。
コーエンのd 
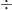
もっと噛み砕くと、「その差は、標準偏差いくつ分ですか?」と聞いています。
基準の目安
この「d」の値がどれくらいなら「効果がある」と言えるのでしょうか? 統計学者のコーエンさんが提唱した、一般的な目安があります。
- 0.2 : 小さい効果(Small)→ 気づかないレベルかもしれないけれど、差はある。
- 0.5 : 中くらいの効果(Medium)→ 肉眼でも「あ、違うな」とわかるレベル。
- 0.8 : 大きい効果(Large)→ 誰が見ても明らかに違うレベル。
もし分析結果で 
メリットとデメリット
どんな指標にも、良い点と悪い点があります。
メリット
- データ数に騙されない100万件のデータがあっても、意味のない差なら効果量は「0.01」のように小さく出ます。ノイズを除去して本質を見ることができます。
- 異なる実験と比較できる「A/Bテストの結果」と「過去の別プロジェクトの結果」など、単位が違うデータ同士でも、効果量という共通の物差しで比較できます。
デデメリット
- 上司への説明が少し難しい「P値が0.05を切りました!」と言うと通りが良いですが、「効果量が0.4でした!」と言っても、統計に詳しくない上司は「……で?」となりがちです。この記事にあるような「ボリュームのつまみ」の例えを使って説明するスキルが求められます。
- データの分布に注意コーエンのdは、データが「正規分布(釣り鐘型のきれいな山)」になっていることを前提としています。極端な外れ値があるデータでは、計算結果がおかしくなることがあります。
実践:Pythonで計算してみよう
難しい計算はPythonに任せましょう。2つのデータ群 group_a と group_b があるとします。
import numpy as np
平均値の差を計算
diff = np.mean(group_a) - np.mean(group_b)
統合された標準偏差(プールド標準偏差)を計算
※少し簡略化しています
std = np.sqrt((np.var(group_a) + np.var(group_b)) / 2)
効果量(コーエンのd)
cohens_d = diff / std
print(cohens_d)
このコードを保存しておけば、いつでもサッと効果量を算出できますね!
今後の学習の指針
今回の解説で、P値という「確率」の世界から、効果量という「実質的なインパクト」の世界へ足を踏み入れました。これであなたは、「統計的に有意か」と「ビジネス的に意味があるか」を分けて考えられるようになっています。
最後に、次に学ぶべきステップを提案します。
次は「検出力分析(パワーアナリシス)」について調べてみてください。
これは、「効果量0.5(中くらいの差)を見つけたいなら、最低でも何件のデータが必要か?」を逆算する技術です。これを知っていれば、実験を始める前に「今回はデータが100件しかないから、微小な差は見つけられないな」と予測できるようになります。
「無駄なA/Bテスト」を減らし、会社のお金と時間を節約できるエンジニアを目指して、ぜひ学習を続けてください。
それでは、また次回の記事でお会いしましょう!
セイ・コンサルティング・グループの新人エンジニア研修のメニューへのリンク
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。

