【決定係数の罠】説明変数を増やすとなぜ精度が良く見える?エンジニア1年目が知るべきロジック
 山崎講師
山崎講師こんにちは。ゆうせいです。
データ分析や機械学習の勉強を始めたばかりのとき、モデルの精度を示す数値が高くなると嬉しくなりますよね。特に「決定係数」というスコアが1に近づくと、「おっ、いいモデルができた!」とガッツポーズをしたくなるものです。
でも、そこでちょっと立ち止まってください。
もしあなたが、精度を上げるために「とりあえず手元にあるデータを全部突っ込んでみた」としたら、その高スコアは幻かもしれません。実は、この数値には「情報を増やせば増やすほど、勝手に良くなってしまう」という不思議な性質があるのです。
今日は、なぜそんなことが起きるのか、そのカラクリを数学が苦手な方にもわかるように紐解いていきます。一緒に「データの落とし穴」を回避する知恵を身につけましょう。
そもそも決定係数ってなに?
まずは基本のおさらいです。回帰分析という手法を使って予測モデルを作るとき、そのモデルがどれくらい優秀かを測る物差しとして使われるのが「決定係数」です。記号では 
決定係数は、0から1の間の値をとります。1に近いほど「このモデルはデータを完璧に説明できている!」ということになります。
たとえば、あなたが「気温」から「アイスクリームの売上」を予測したいとします。
- 説明変数(予測の手掛かり):気温
- 目的変数(予測したいもの):アイスクリームの売上
このとき、気温というデータだけで売上の変化をどれくらい説明できているかを示すのが決定係数です。
変数を増やすと何が起きるのか
ここで本題に入りましょう。
あなたはもっと精度を上げたくて、説明変数を増やそうと考えました。気温だけでなく、「湿度」「曜日の情報」「近くのイベントの有無」など、データをどんどん追加していきます。
すると不思議なことに、決定係数の値は下がることはなく、少しずつ上昇していくはずです。
さらに極端な話をしましょう。ここで全く関係のない「昨日の私の夕食のカロリー」や「サイコロを振って出た目」というデタラメなデータを説明変数に追加したとします。
普通に考えれば、ノイズが混ざって精度が落ちそうですよね?
ところがどっこい、それでも決定係数は「維持」または「わずかに上昇」してしまうのです。下がることはありません。これが今日みなさんに一番伝えたい「決定係数のクセ」なのです。
なぜゴミデータを入れてもスコアが上がるの?
なぜこんなことが起きるのでしょうか。ここからは少しロジカルに考えてみましょう。
回帰分析のモデル(最小二乗法)は、とにかく「実際のデータ」と「予測値」のズレを最小にしようと努力する真面目な性格をしています。
数式でイメージしてみましょう。通常の決定係数は以下のような関係で成り立っています。
決定係数 


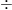
モデルが良いほど、「説明できなかったズレ」が小さくなり、引き算の結果である決定係数は1に近づきます。
ここで新しい変数を追加したとします。たとえそれが「サイコロの目」のような適当なデータであっても、計算上、偶然わずかに売上と連動している部分を見つけ出すことがあります。
モデルは非常に貪欲なので、その偶然の一致さえも利用して、ほんの少しでもズレ(誤差)を減らそうと計算式を調整します。
「使える武器が増えたなら、たとえそれが竹槍でも装備しておこう」という感じです。
数学的なルールとして、変数を増やしてモデルの表現力を上げると、過去のデータに対する当てはまりの良さ(残差平方和の減少)は、絶対に悪化しません。現状維持か、少しでも改善する方向へ動きます。
その結果、「説明できなかったズレ」が計算上は減ってしまい、結果として決定係数が上がってしまうのです。
メリットとデメリットを整理しよう
この性質を理解した上で、通常の決定係数を使うことの良し悪しを見てみましょう。
メリット
- 直感的でわかりやすい「1に近いほどすごい」という単純明快さは強力です。
- 絶対的な指標として使える単一の変数のモデル評価や、変数の数が変わらないモデル同士を比較するときには信頼できる指標です。
デメリット
- モデルの複雑さを評価できない変数を無闇に増やしただけの「無駄に複雑なモデル」でも高評価を与えてしまいます。
- 過学習(オーバーフィッティング)を見抜けない手元のデータには完璧にフィットしていても、未知の新しいデータには全く通用しない、という危険な状態を見落とす原因になります。
対処法:自由度調整済み決定係数を使おう
「じゃあ、どうやって本当の性能を見極めればいいの?」と思いますよね。
そこで登場するのが「自由度調整済み決定係数」という指標です。名前が長くて強そうですね。
これは、通常の決定係数に「ペナルティ」という概念を加えたものです。
- 通常の決定係数:変数を増やせば増やすほどハッピー。
- 自由度調整済み決定係数:「変数を増やすなら、その分だけ予測精度が劇的に上がらないと許さないぞ」と厳しくジャッジする。
つまり、変数を増やしたことによる「計算上の微量な改善」よりも、「変数を増やしたことへのペナルティ(コスト)」の方が大きければ、この数値は下がります。
無意味な変数を追加したとき、通常の決定係数は上がりますが、自由度調整済み決定係数は下がるのです。これなら公平な判断ができそうですね。
まとめと今後の学習指針
いかがでしたか。
「データさえ増やせば精度が上がる」というのは、半分正解で半分間違いです。数値上の見かけの精度と、本当に価値のある予測能力は別物だということを、エンジニアとして働き始めた今のうちに心に刻んでおいてください。
最後に、これからの学習の道しるべを提案します。
- 「過学習(Overfitting)」について深掘りする今日説明した現象は、過学習への入り口です。なぜモデルが複雑すぎるとダメなのか、図解されている書籍などで学んでみてください。
- AIC(赤池情報量基準)を知る自由度調整済み決定係数と同じように、モデルの良し悪しを決めるための「AIC」という指標があります。これも統計学では必須の知識ですので、ぜひ調べてみてください。
数字に踊らされず、数字を操るエンジニアを目指して、焦らず一歩ずつ進んでいきましょう。応援しています!
セイ・コンサルティング・グループの新人エンジニア研修のメニューへのリンク
投稿者プロフィール