
「P値はデータが増えるとなぜ下がる?」新人エンジニアが陥る統計の罠と解決策
 山崎講師
山崎講師こんにちは。ゆうせいです。
新人エンジニアのみなさん、A/Bテストやデータ分析の結果を見ていて、こんな経験はありませんか?
「P値が0.05(5%)を下回った! 有意差ありだ! この施策は大成功です!」
と喜んで上司に報告したら、「でもそれ、データ数が膨大だから当たり前じゃない?」 と冷たく返されてしまった……。
なぜデータ数が増えると、P値は小さくなりやすいのでしょうか? 不思議だと思いませんか? 直感的には「データが増えれば増えるほど、結果はより正確になるはずだから、P値も落ち着くべきでは?」と思うかもしれません。
実はこれ、統計学における「虫眼鏡のパラドックス」とも呼べる現象なのです。
今日は、なぜデータ数を増やすだけでP値が下がってしまうのか、そのカラクリと、エンジニアが気をつけるべき「落とし穴」について、数式をなるべく使わずに解説していきます!
P値とは「偶然」を疑う指標
まず、P値の正体をおさらいしましょう。教科書的な定義は一旦忘れてください。現場での感覚はこうです。
「この結果は、たまたま偶然起きただけじゃないの?」という確率
たとえば、コインを投げて「表」が出たとします。
- 3回投げて、全部「表」だった場合「まあ、たまたま運が良かっただけかもね」と思いますよね。このとき、P値はまだ 大きめ です(偶然の可能性が高い)。
- 100回投げて、全部「表」だった場合「いやいや! さすがにそれはおかしい。イカサマか、重心が偏っているコインに違いない!」と確信しますよね。このとき、P値は 限りなくゼロ に近づきます(偶然の可能性が低い)。
つまり、「試行回数(データ数)が増えれば増えるほど、『たまたま』という言い訳が通用しなくなる」 のです。これが、データ数が増えるとP値が下がる直感的な理由です。
数学的な理由:分母に隠れた「ルートn」
では、もう少しエンジニアらしく、メカニズムを覗いてみましょう。
P値を計算するとき、その背後には必ず「検定統計量(t値など)」というスコアが存在します。ざっくり言うと、このスコアは次のような割り算で決まります。
検出力(スコア) 
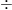
このスコアが大きければ大きいほど、「差がある!」と判定され、P値は小さくなります。
ここで重要なのが、分母にある「バラつき(標準誤差)」の正体です。この「バラつき」は、データ数( $n$ )が増えるとどうなるでしょうか?
実は、標準誤差の式には、分母に 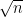
バラつき 

ここが最大のポイントです!
- データ数
を増やす(無限に近づける)。
- すると、分母の
- 割り算の結果である「バラつき(ノイズ)」は ゼロに近づく。
- ノイズが小さくなれば、最初の式の「スコア」は 爆発的に大きくなる。
- スコアが大きいということは、P値は 限りなく小さくなる。
つまり、データ数を増やすということは、「ノイズを強制的に小さくして、どんなに微小な差でも浮き彫りにする」 という行為なのです。
メリットとデメリット:高画質すぎるカメラの悲劇
この性質は、良いことばかりではありません。具体的に見ていきましょう。
メリット:微細な変化を見逃さない
データ数を増やすことの最大のメリットは、「検出力」が上がること です。
たとえば、ウェブサイトのボタンの色を変えて、「クリック率が 0.1% 上がった」とします。データ数が100件なら「誤差」として無視されますが、データ数が100万件あれば「統計的に有意な差(P < 0.05)」として検出できます。
ほんのわずかな改善でも確実に拾い上げたい場合、データ数は正義です。
デメリット:どうでもいい差まで「有意」になる
これが今回のテーマの核心、「過剰な検出力」 という問題です。
たとえば、新しいダイエット薬を開発したとしましょう。
10万人の被験者を集めて実験した結果、「平均体重が 1グラム 減った」とします。
データ数が10万もあるので、計算上、P値は 
しかし、冷静になってください。「1グラム減る薬」にお金を払いますか?
払いませんよね。統計的には「差がある(有意である)」ことは間違いありませんが、実用上は「意味がない」のです。
これが、上司が言った「データ数が多いから当たり前」の正体です。高性能な8Kカメラ(大量のデータ)を使えば、目に見えないホコリ(無意味な微差)までくっきり写ってしまう のと同じことなのです。
今後の学習の指針:P値の「次」へ進もう
最後まで読んでいただき、ありがとうございます!
「P値が小さければ正義」という考え方が、いかに危ういか伝わりましたでしょうか? データ数が多い現代の分析においては、P値は「差があるかどうか」を教えてくれるだけで、「その差が重要かどうか」までは教えてくれません。
では、私たちはどうすればいいのでしょうか?
これからの学習の指針として、次は以下のキーワードを調べてみてください。
- 効果量(Effect Size):サンプルサイズに依存せず、「差の大きさそのもの」を評価する指標です(Cohen's dなどが有名です)。
- 信頼区間(Confidence Interval):「平均値の差は、95%の確率でこの範囲に収まるよ」という幅を見ることで、結果の安定性を判断します。
「P値は0.01です! でも効果量は小さいので、ビジネスインパクトは薄いかもしれません」
こんなふうに報告できるようになったら、あなたはもう新人エンジニア卒業です。上司も「おっ、こいつできるな」と顔色を変えること間違いなしですよ!
それでは、また次の記事でお会いしましょう!
セイ・コンサルティング・グループの新人エンジニア研修のメニューへのリンク
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。

