
エクセルとPythonで計算結果がズレる?その驚きの原因と解決策を徹底解説
 山崎講師
山崎講師こんにちは。ゆうせいです。
みなさんは、仕事や勉強でデータ分析をしているとき、こんな経験をしたことはありませんか?
「あれ? エクセルで出した平均値と、Pythonで計算した結果が微妙に違う……」
計算式は間違っていないはずなのに、最後の1桁だけ数字が合わない。これ、実は計算ミスではないんです!
今日は、データ分析の現場で頻発する「エクセル、R、Pythonの数値の不一致」というミステリーについて、その犯人を捜していきましょう。この謎が解ければ、あなたのデータ分析スキルは一気にレベルアップしますよ!
なぜ「正解」がいくつもあるの?
まず最初に、衝撃的な事実をお伝えします。コンピュータの世界には、絶対的な「ひとつの正解」が存在しないことがあるんです。
エクセル、R、Pythonは、それぞれ「開発された目的」や「歴史」が異なります。そのため、計算に対する「哲学」や「流儀」が違うのです。
たとえば、料理を作るときを想像してみてください。「塩少々」と言われたとき、指でつまむ人もいれば、小さじで計る人もいますよね? どちらも間違いではありませんが、出来上がりの味は微妙に変わります。
これと同じことが、コンピュータの計算の世界でも起きているのです。では、具体的にどんな違いがあるのか、詳しく見ていきましょう。
原因1:数字の「記憶力」が違う
ひとつ目の原因は、コンピュータが数字を覚えるときの「記憶力(精度)」の違いです。
エクセルの「15桁」ルール
エクセルには、少し変わったルールがあります。それは「有効数字は15桁まで」という決まりです。
どういうことかというと、エクセルは非常に長い数字を扱うとき、16桁目以降をバッサリと切り捨てて「0」にしてしまいます。
たとえば、ものすごく細かい計算をして「100.123456789012345」という答えが出たとしましょう。エクセルはこれを「100.123456789012000」として記憶します。
PythonやRの記憶力
一方で、PythonやRといったプログラミング言語は、コンピュータの性能が許す限り、もっと細かい数字(約17桁ほど)まで正確に覚えようとします。
この「ほんのわずかな切り捨て」が、何千回、何万回と計算を繰り返すうちに積み重なって、最終的に目に見えるズレとなって現れるのです。これを専門用語で「丸め誤差」や「情報落ち」と呼んだりします。
原因2:四捨五入の「流儀」が違う
ふたつ目は、もっと身近な「四捨五入」の話です。
みなさんが小学校で習った四捨五入は、「0.5なら切り上げる」でしたよね? これを「四捨五入」と呼びます。エクセルの ROUND 関数は、この学校で習った通りの動きをします。
しかし、PythonやRは違います。「銀行丸め(偶数への丸め)」という特殊な方法を使っているのです。
銀行丸めってなに?
銀行丸めとは、「端数がちょうど0.5のとき、結果が偶数になるほうに丸める」というルールです。
- 2.5 を丸めると
になります(2は偶数だから)。
- 3.5 を丸めると
になります(4は偶数だから)。
なぜこんな面倒なことをするのでしょうか?
もし「0.5は常に切り上げ」にしてしまうと、たくさんのデータを足し合わせたとき、全体的に数字が「少し大きく」なってしまいますよね。これを防ぐために、切り上げと切り捨てを半々にして、全体のバランスを取ろうというのが「銀行丸め」の考え方です。
統計学的にはこちらのほうが公平なのですが、エクセルと結果が合わなくなる最大の原因のひとつです。
Pythonでエクセルと同じ計算をするには?
もしPythonを使っていて、エクセルとピッタリ同じ結果を出したい場合は、通常の round ではなく、少し工夫したプログラムを書く必要があります。
import decimal
def excel_round(number, digits):
context = decimal.getcontext()
context.rounding = decimal.ROUND_HALF_UP
return round(decimal.Decimal(str(number)), digits)
このように、ツールごとの「癖」を知っておくことが大切です。
原因3:統計の「定義」が違う
ここからは少し専門的になりますが、高校生のみなさんにもわかるように解説しますね。
データのばらつきを表す「標準偏差(ひょうじゅんへんさ)」という言葉を聞いたことはありますか? 実はこの計算式も、ツールによって違うんです。
割り算の分母は「n」か「n-1」か
データを集めてそのばらつきを計算するとき、データの個数 
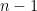
- エクセル(STDEV.P)やPython(NumPy)データの個数
- エクセル(STDEV.S)やPython(Pandas)、Rデータの個数から1を引いた
ややこしいですよね! でも、どちらを使っているかを確認しないと、計算結果は絶対に一致しません。
Pythonを使うときの注意点
Pythonには数値計算が得意な NumPy と、データ分析が得意な Pandas というライブラリがありますが、なんとこの2つでもデフォルト(初期設定)の計算式が違います。
- NumPy:
- Pandas:
NumPyを使ってエクセル(STDEV.S)と同じ結果を出したいときは、次のように「自由度(ddof)」を1に設定する必要があります。
np.std(data, ddof=1)
原因4:過去の「バグ」を継承している
最後は、歴史的な面白いお話です。
エクセルには「1900年うるう年問題」という有名なバグがあります。本当は1900年はうるう年ではない(2月29日はない)のですが、エクセルの中では「ある」ことになっています。
これは、エクセルが生まれる前に普及していた「Lotus 1-2-3」というソフトの不具合を、互換性のためにあえてマネした結果だと言われています。
一方でPythonやRは、カレンダー通り正しく計算します。そのため、日付の計算をすると、1900年3月1日より前の日付で1日ズレてしまうのです。
まとめ:結局どうすればいいの?
ここまで見てきたように、数値のズレは「バグ」ではなく、それぞれのツールの「個性」や「設計思想」の違いによるものでした。
- エクセル: ビジネスの現場で直感的に使いやすいように設計されている。
- Python/R: 科学的な厳密さや、統計的な正しさを優先して設計されている。
今後の学習の指針
もしあなたが、厳密な科学実験や高度なAI開発をするなら、PythonやRの結果を信じるのが安全です。一方で、会社の経理や一般的なレポート作成なら、エクセルの計算結果に合わせるほうが混乱が少ないでしょう。
大切なのは「ズレることは当たり前」と知っておくことです。
これからデータ分析を学ぶみなさんは、単にツールを使うだけでなく、「その裏側でどんな計算が行われているのか?」という仕組みにも興味を持ってみてください。
まずは、Pythonの Pandas ライブラリを使って、エクセルと同じ計算結果が出せるように「設定(パラメータ)」を調整する練習から始めてみてはいかがでしょうか?
そうすれば、あなたは「数字が合わない!」と慌てる同僚を助けられる、頼れるデータサイエンティストになれるはずです!
セイ・コンサルティング・グループの新人エンジニア研修のメニューへのリンク
投稿者プロフィール
- 代表取締役
-
セイ・コンサルティング・グループ株式会社代表取締役。
岐阜県出身。
海外放浪の末、2000年創業、2004年会社設立。
IT企業向け人材育成研修歴業界歴20年以上。
すべての無駄を省いた費用対効果の高い「筋肉質」な研修を提供します!
この記事に間違い等ありましたらぜひお知らせください。
学生時代は趣味と実益を兼ねてリゾートバイトにいそしむ。長野県白馬村に始まり、志賀高原でのスキーインストラクター、沖縄石垣島、北海道トマム。高じてオーストラリアのゴールドコーストでツアーガイドなど。現在は野菜作りにはまっている。

